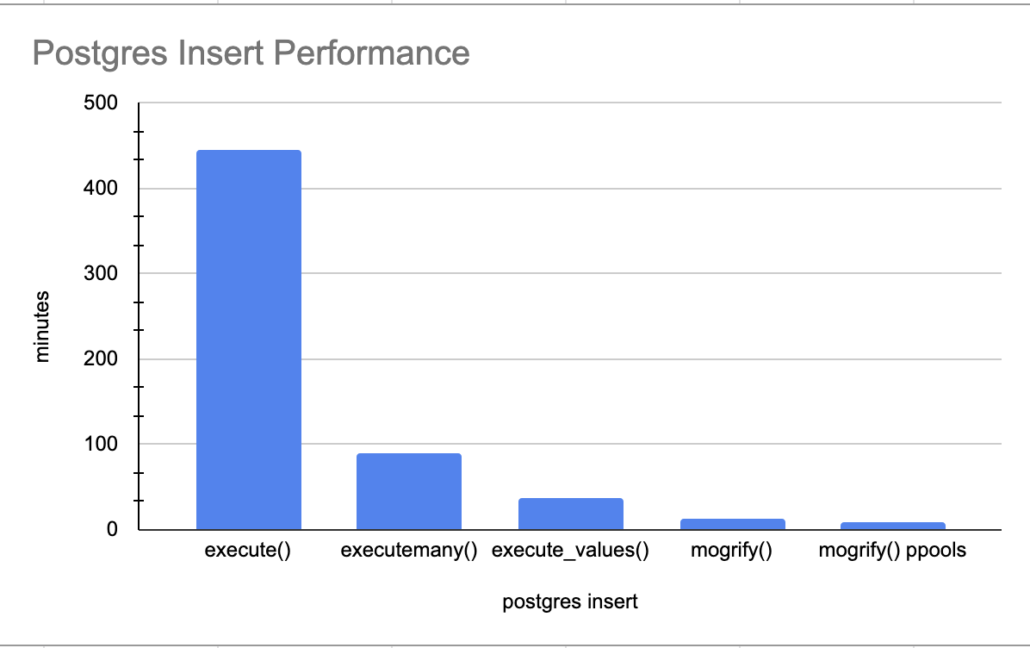
Even I get confused these days. Data Warehouse, Data Lake, and Lake Houses … why do we have three, what are the differences? Is it all just marketing huff-a-luff? Technology and life in the data world seem to be changing fast these days. Lot’s of new vendors on the streets trying to hawk their tools and solutions, each of them pumping out content designed to solve all your data needs.
I’ve seen a lot of content out there by SAAS vendors, and by folks who ascribe to a said vendor, about Data Lakes and Lake Houses, new schema designs and approaches, and it’s hard to know what is just a sales tactic and what is real. I’m going to stir the pot.
This is a start of a 5 part series on Demystifying Data Warehouses / Data Lakes / Lake Houses. Enjoy.
Read more