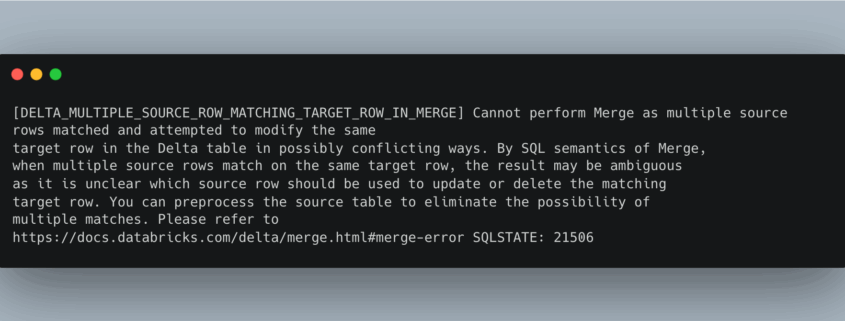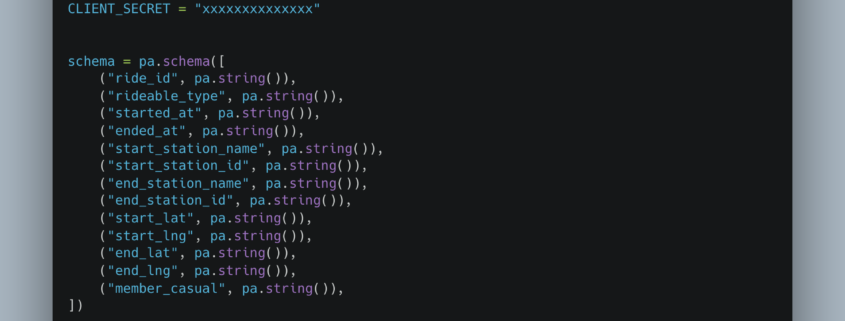
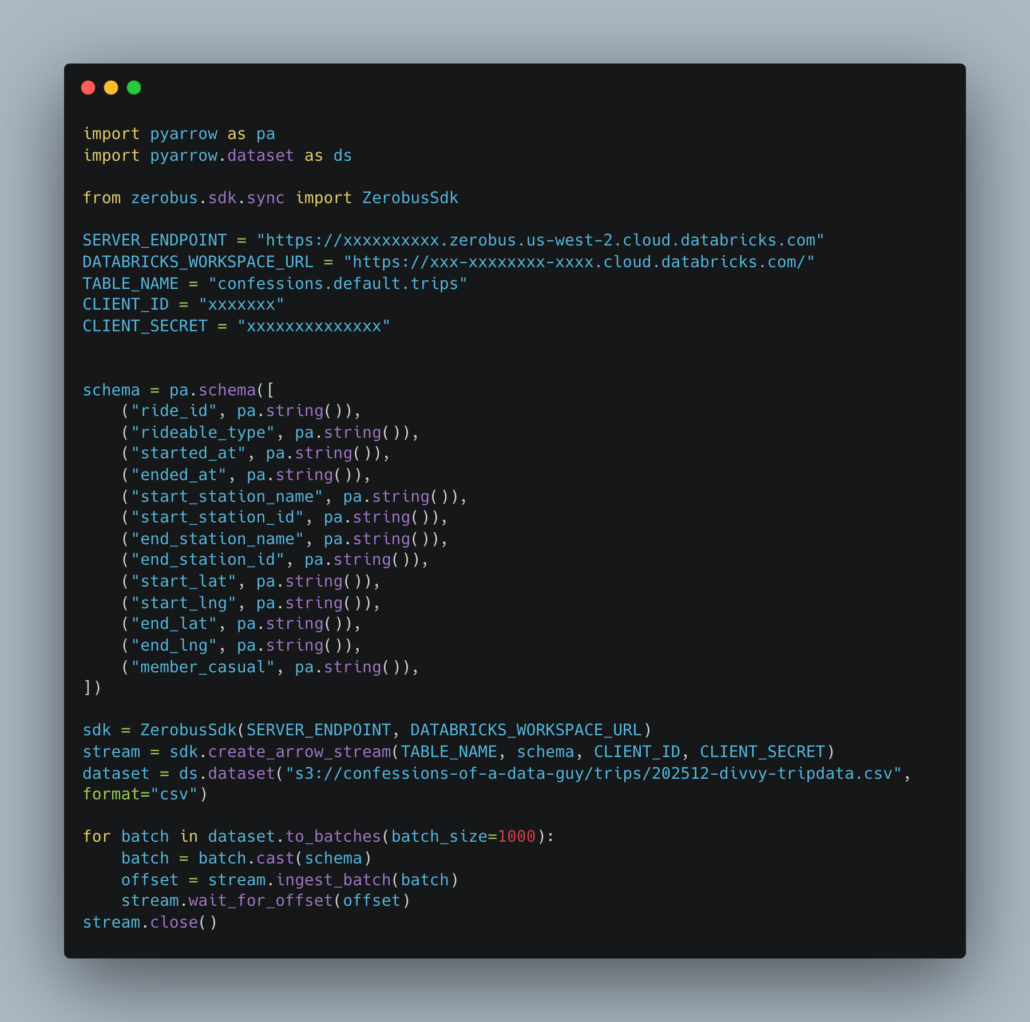
Yeah, so … I’ve heard rumbling and mumblings about, here and there. But I had yet to try it out for myself. I trust nothing I can’t put my hands on. Something about being raised in the cornfields of the Midwest, always be skeptical of anything that seems like Black Magic.