
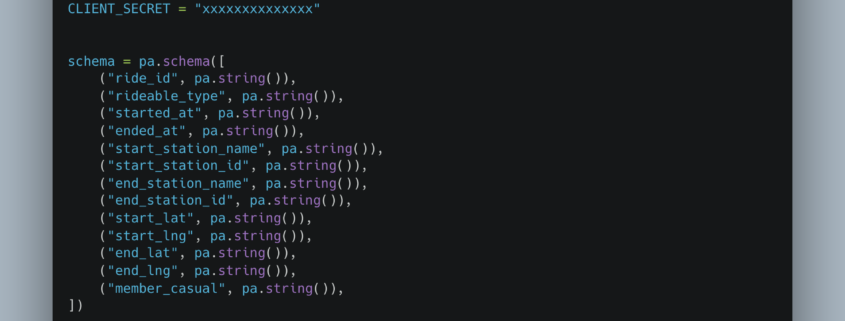
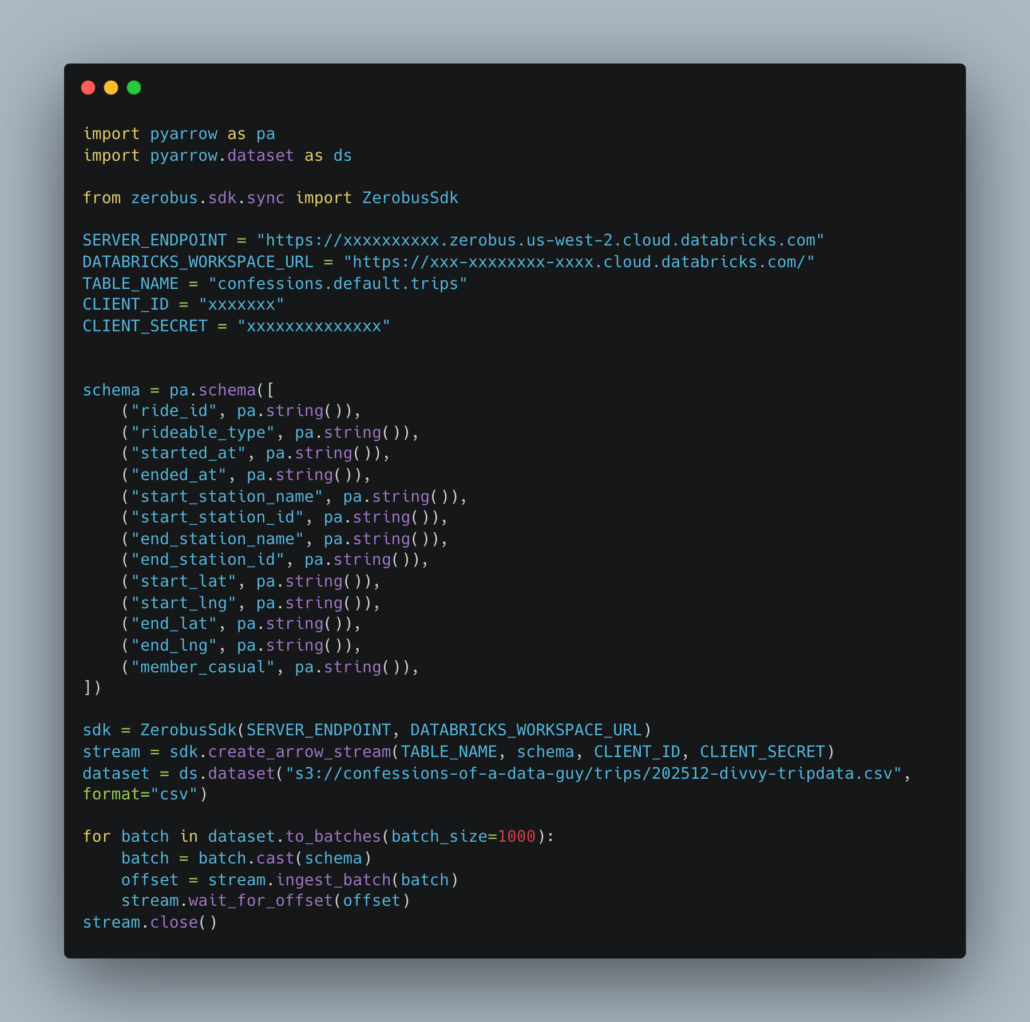
Yeah, so … I’ve heard rumbling and mumblings about, here and there. But I had yet to try it out for myself. I trust nothing I can’t put my hands on. Something about being raised in the cornfields of the Midwest, always be skeptical of anything that seems like Black Magic.

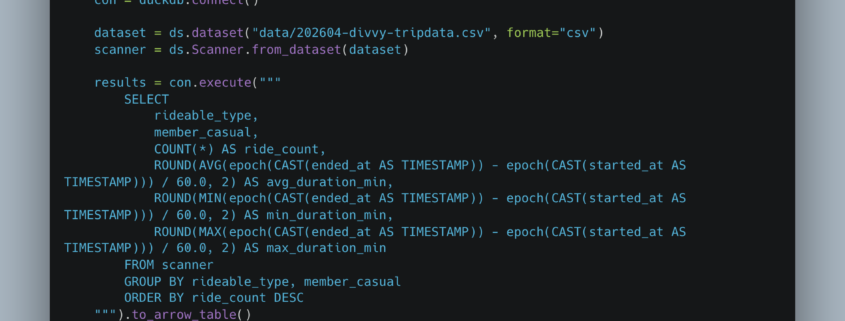
It’s hard to find the bright, shining stars amid the doom and gloom the tech world seems to be floundering in. When the going gets tough, I like to remind myself that there are lots of new and exciting tools released in the last few years, most of which, when combined, have not been part of the great LLM training material, leaving some fun left to explore.
Two of my newest favorite tools, DuckDB and Apache Arrow, have been around a while but are now becoming more integrated, starting to stand more firmly on their own and together.
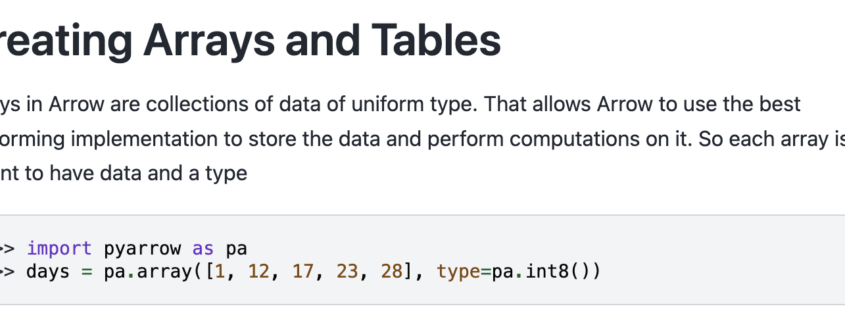
Apache Arrow entered the data scene quietly; for years, it languished in obscurity, unheard of and uncared for by the data community. Back in the olden days of 2022, which feels like another world, I was happily using and writing about Arrow as a data processing tool. A lot has changed since then, and Arrow has catapulted its way into everyday data engineering conversations.
Ok, Spark isn’t dead. Before you leave, I’m sorry for lying to you. Sorta. Kinda. Not really.
Undoubtedly Apache Spark has reached its zenith, shot like a rocket out of the Databricks barrel into the sky. The world is shifting though, even if ever so imperceptible.
