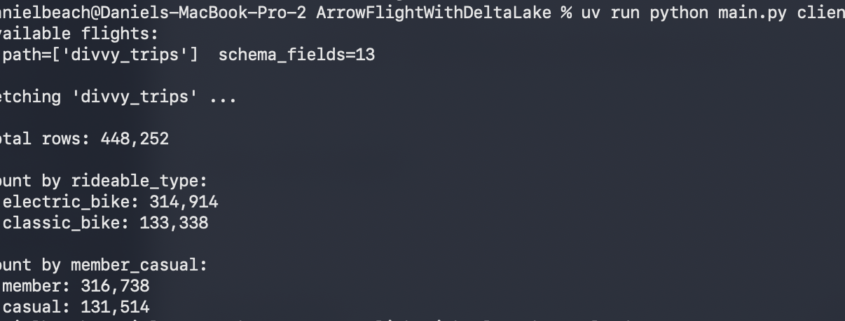
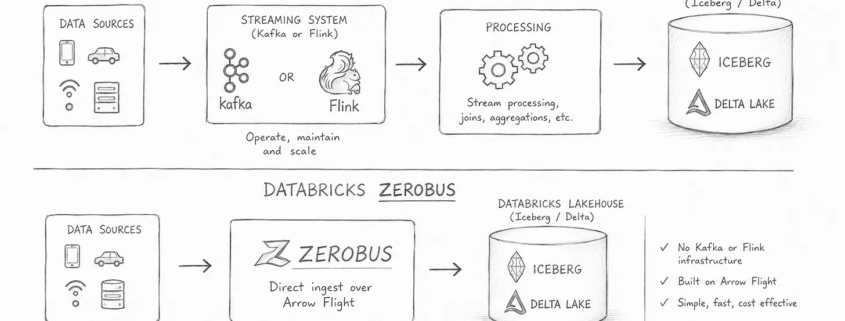
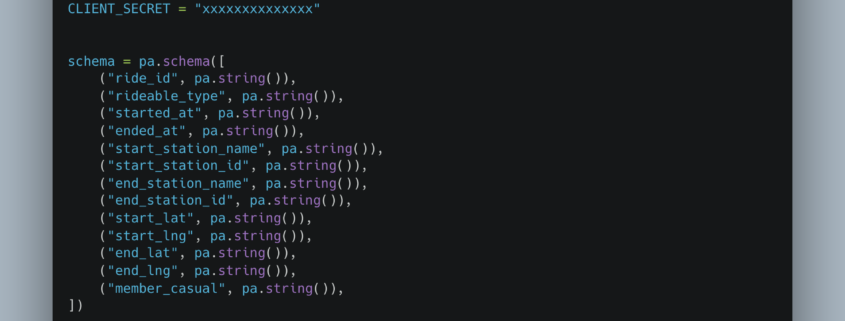
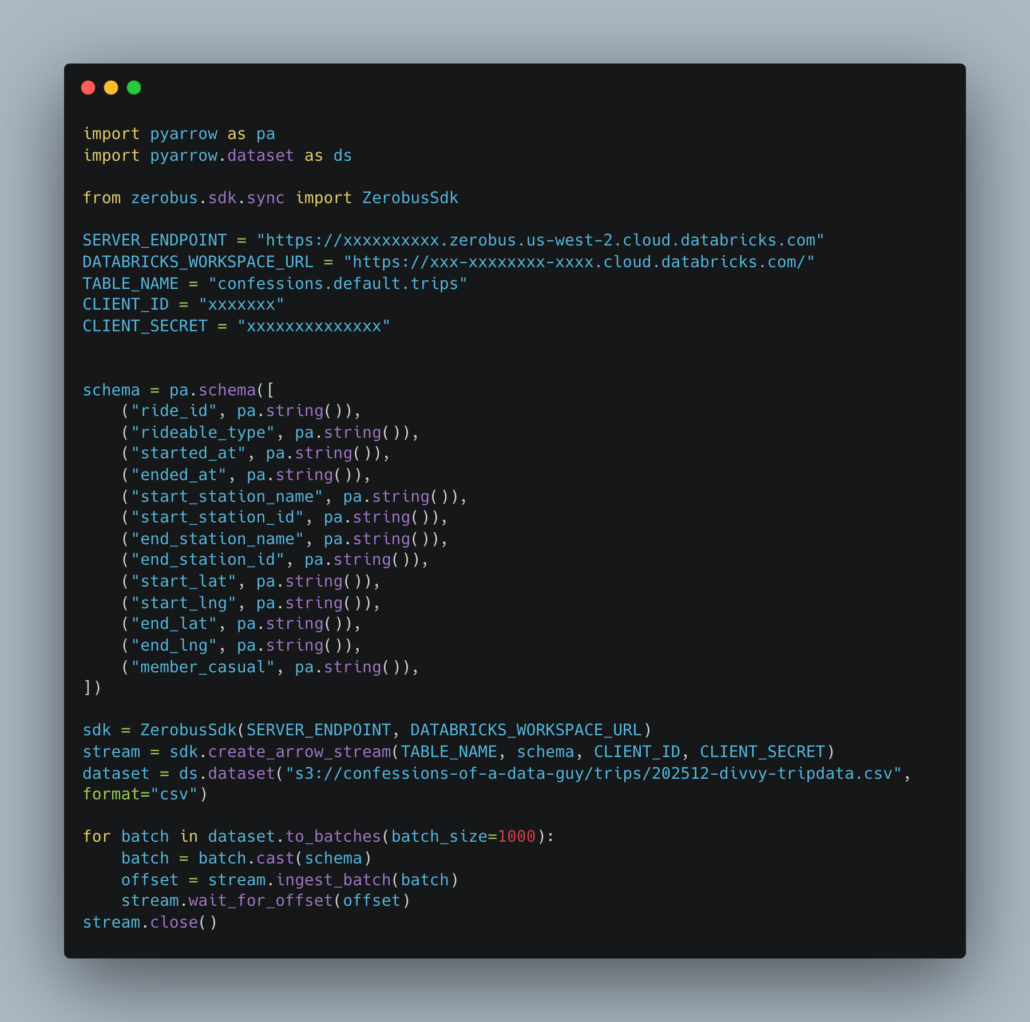
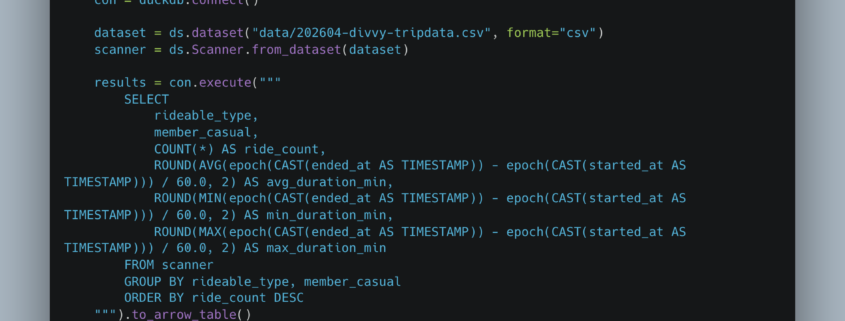
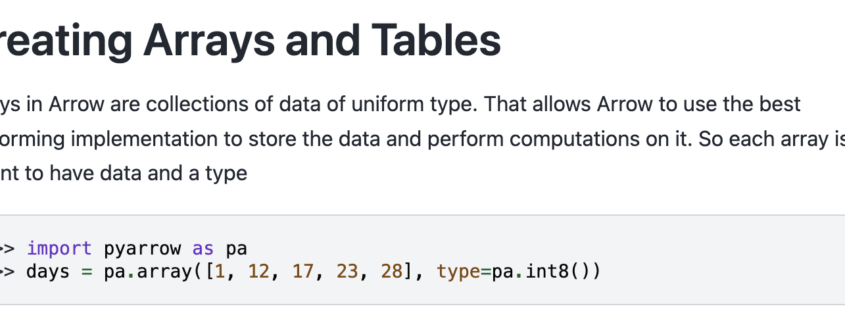
Why isn’t anyone talking about this?
Sometimes I am genuinely amazed by what captures the attention of the broader data community and what gets quietly pushed off to the side. I suppose I understand why it happens. New models arrive, vendors announce shiny features, and everyone rushes toward the next big thing. Still, as someone who has spent the last few years championing what I affectionately call the Single Node Rebellion, it is difficult not to wonder why certain developments receive so little attention. This is one of those moments.