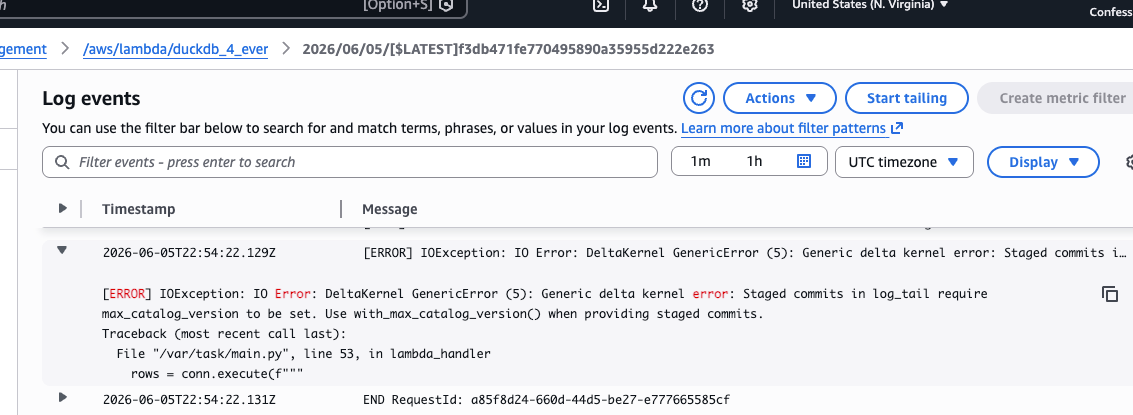
Delta Lake + DuckDB. Catalog Commits with Unity Catalog. Unlocking Concurrent Ingestion.
Why isn’t anyone talking about this?
Sometimes I am genuinely amazed by what captures the attention of the broader data community and what gets quietly pushed off to the side. I suppose I understand why it happens. New models arrive, vendors announce shiny features, and everyone rushes toward the next big thing. Still, as someone who has spent the last few years championing what I affectionately call the Single Node Rebellion, it is difficult not to wonder why certain developments receive so little attention. This is one of those moments.
The industry has largely settled on the lakehouse as the architectural pattern of choice for modern data platforms. Delta Lake and Iceberg continue to evolve and, in many ways, are converging toward similar goals. Most organizations have embraced this direction wholeheartedly, and for good reason. Lakehouse architectures offer flexibility, scale, and openness that traditional warehouse approaches struggled to provide. Once you drink from that particular chalice, there is very little desire to go back.

The side effect of this shift, however, is that many of us have become conditioned to believe that clusters and increasingly expensive compute resources are simply the cost of doing business. Serverless offerings have certainly improved the experience, and tools such as DuckDB, Polars, and Daft have expanded what is possible outside of traditional distributed environments, but we should not pretend there are not tradeoffs. Complexity has a way of creeping into systems quietly, and before long, what began as an elegant architecture starts demanding increasingly elaborate infrastructure just to accomplish relatively straightforward tasks.
Over the past few years, I have been the person enthusiastically stuffing DuckDB into AWS Lambda functions and pointing them directly at Unity Catalog governed Delta Lake tables. It has worked remarkably well in some scenarios, but there has always been an underlying tension. The moment transactions enter the picture, things become more complicated. Delta Lake exists because transactional guarantees matter, but transactional guarantees also mean you cannot simply allow every tool to write whenever and however it pleases.
How do you know that the engine performing a write is operating against the correct version of a table? How do you safely support multiple writers targeting the same dataset without creating corruption or inconsistent metadata? More importantly, how do you make those capabilities accessible to ordinary teams without forcing them to become experts in distributed systems internals?
That is the problem worth talking about.
For years, lakehouse architectures have excelled at delivering scalable storage and processing capabilities while struggling to support the messy realities of heterogeneous tooling. Reading data from Delta Lake tables became increasingly accessible across engines, but writing remained far more restrictive. The dream of truly open, multi-engine lakehouse architectures, where specialized tools could participate as first-class citizens in production workloads, often felt just out of reach.
A small number of practitioners ventured into that territory using projects such as delta-rs, DynamoDB-backed transaction mechanisms, or custom implementations that required considerable expertise to operate safely. For everyone else, the practical answer was straightforward. If you wanted robust write semantics, you stayed inside the boundaries of Spark clusters, serverless offerings, or vendor-specific execution environments. The lakehouse might have been open in principle, but the reality was that production write access remained tightly coupled to a relatively narrow set of technologies.
What was missing was not some revolutionary breakthrough in distributed computing theory. It was something far more practical. We needed a simpler approach to concurrent writes that worked with common tools and aligned with how data teams actually build systems. We needed a way to preserve the integrity and governance benefits of the lakehouse while opening the door to more flexible execution models.
Simple is good.
Simple architectures are easier to understand, easier to operate, and often more resilient because they reduce the number of moving pieces involved. The ability to safely combine multiple processing engines, each selected because it is the right tool for a particular task, represents a meaningful evolution in how we think about lakehouse platforms. The goal is not novelty for novelty’s sake. The goal is to expand what becomes practical.
This is where Catalog Commits enter the conversation.

At its core, Delta Lake provides ACID guarantees on top of object storage. That design decision is one of the reasons the technology became so successful. It delivers transactional capabilities without requiring a traditional database architecture underneath. However, as organizations adopted broader ecosystems of tools, limitations began to emerge.
Databricks has articulated several of these challenges clearly. External engines writing directly to Delta tables through object storage can cause catalog metadata to drift from the actual state of the data. Different tools often discover and interact with datasets using inconsistent mechanisms, leading to fragmented governance experiences and uneven enforcement of access controls. Historically, open lakehouse architectures have also struggled to support atomic operations spanning multiple tables.
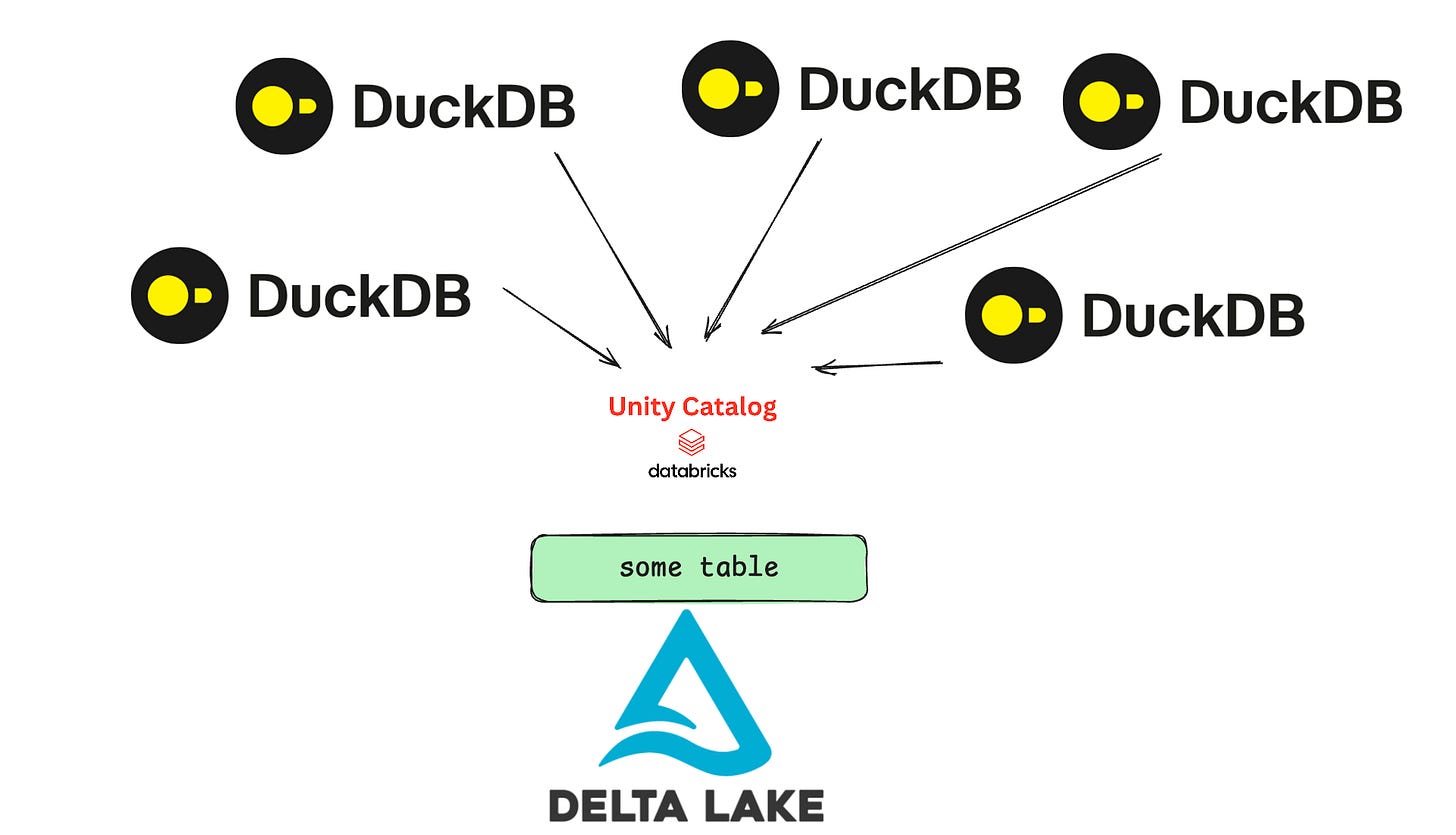
The logical conclusion is difficult to avoid. Data catalogs cannot simply exist as passive repositories of metadata. They increasingly need to become the primary mechanism through which engines interact with lakehouse storage. In many respects, this mirrors the path Iceberg has already taken. Governance, discovery, auditing, and transactional coordination become significantly more manageable when the catalog itself occupies a central role in the architecture.
The implications are larger than they might initially appear.
If catalogs evolve into active participants in transactional workflows, an entirely new set of architectural patterns becomes available. Suddenly, it becomes possible to imagine ingestion pipelines powered by lightweight engines operating safely alongside more traditional processing frameworks. The lakehouse stops being synonymous with Spark and begins to resemble something much more flexible.
That possibility is what excites me.
I have probably spent enough time philosophizing at this point, so let us move from theory into practice. Using my own AWS and Databricks environments, I want to explore how these ideas could reshape the way we think about data ingestion. What interests me most is not the sophistication of the architecture. It is the simplicity.
Because simplicity, when it works, is a beautiful thing.
Consider one of the most common patterns in data engineering. CSV files land in object storage and need to be ingested into a medallion architecture. Traditionally, this task might be handled using a Databricks Job running Spark. There is nothing inherently wrong with that approach, but it is worth questioning whether distributed compute is always justified. Processing a few hundred CSV files each day rarely requires an entire cluster, even if that has become the default solution.
What if those files simply triggered AWS Lambda functions? What if DuckDB running inside those Lambdas could ingest the data directly into Unity Catalog governed Delta Lake tables while preserving transactional correctness and supporting concurrent execution?

This Dockerfile
FROM –platform=linux/amd64 public.ecr.aws/lambda/python:3.12
RUN pip install –no-cache-dir uv && \
uv pip install –system –no-cache “duckdb”
RUN mkdir -p /opt/duckdb_extensions && \
python -c “import duckdb; c=duckdb.connect(config={‘extension_directory’:’/opt/duckdb_extensions’}); c.execute(‘INSTALL unity_catalog’); c.execute(‘INSTALL httpfs’); c.execute(‘INSTALL aws’); c.close()”
ARG DATABRICKS_HOST
ARG DATABRICKS_TOKEN
ENV DATABRICKS_HOST=${DATABRICKS_HOST}
ENV DATABRICKS_TOKEN=${DATABRICKS_TOKEN}
ENV DUCKDB_EXT_DIR=/opt/duckdb_extensions
COPY main.py ${LAMBDA_TASK_ROOT}
CMD [“main.lambda_handler”]
And the Lambda Code.
import os
import shutil
import logging
import duckdb
from urllib.parse import unquote_plus
logger = logging.getLogger()
logger.setLevel(logging.INFO)
DATABRICKS_HOST = os.environ[“DATABRICKS_HOST”]
DATABRICKS_TOKEN = os.environ[“DATABRICKS_TOKEN”]
_OPT_EXT_DIR = “/opt/duckdb_extensions”
DUCKDB_EXT_DIR = “/tmp/duckdb_extensions”
if not os.path.exists(DUCKDB_EXT_DIR):
shutil.copytree(_OPT_EXT_DIR, DUCKDB_EXT_DIR)
def lambda_handler(event, context):
record = event[“Records”][0]
bucket = record[“s3”][“bucket”][“name”]
key = unquote_plus(record[“s3”][“object”][“key”])
if not key.startswith(“trips/”):
logger.info(“Skipping key outside trips/ prefix: %s”, key)
return {“statusCode”: 200, “skipped”: True}
s3_path = f”s3://{bucket}/{key}”
logger.info(“Processing %s”, s3_path)
conn = duckdb.connect(config={“extension_directory”: DUCKDB_EXT_DIR})
conn.execute(“FORCE INSTALL delta FROM core_nightly”)
conn.execute(“LOAD delta”)
conn.execute(“LOAD unity_catalog”)
conn.execute(“LOAD httpfs”)
conn.execute(“LOAD aws”)
conn.execute(“CREATE SECRET (TYPE s3, PROVIDER credential_chain)”)
conn.execute(f”””
CREATE SECRET (
TYPE unity_catalog,
TOKEN ‘{DATABRICKS_TOKEN}’,
ENDPOINT ‘{DATABRICKS_HOST}’
)
“””)
conn.execute(“””
ATTACH ‘confessions’ AS uc_catalog
(TYPE unity_catalog, DEFAULT_SCHEMA ‘default’)
“””)
rows = conn.execute(f”””
INSERT INTO uc_catalog.default.trips
SELECT * FROM read_csv(‘{s3_path}’)
“””).rowcount
conn.execute(“COMMIT”)
conn.close()
logger.info(“Inserted %d rows from %s”, rows, s3_path)
return {“statusCode”: 200, “rows_inserted”: rows}
That architecture is not just simpler. It is genuinely compelling.
But, it doesn’t work yet.