
It’s hard to find the bright, shining stars amid the doom and gloom the tech world seems to be floundering in. When the going gets tough, I like to remind myself that there are lots of new and exciting tools released in the last few years, most of which, when combined, have not been part of the great LLM training material, leaving some fun left to explore.
Two of my newest favorite tools, DuckDB and Apache Arrow, have been around a while but are now becoming more integrated, starting to stand more firmly on their own and together.

I finally hit that point that every engineer eventually reaches with a tool they once loved, that moment where frustration quietly builds over time and then suddenly flips into a decision, not because of one catastrophic failure but because of the accumulation of too many small ones. That was me with Polars. After years of using it, promoting it, and even putting it into production workloads early on, I reached the point where I removed it entirely from a set of critical pipelines and replaced it with DuckDB without much hesitation.
Before anyone jumps in to defend Polars or call this an overreaction, it is worth understanding that this was not a spur-of-the-moment decision. This was the result of years of real-world usage, repeated friction, and a growing realization that what matters most in a production data platform is not theoretical performance or benchmark wins, but consistency, predictability, and trust that the tool behaves the same way every time it runs.

I’ve written before about the elusive “Semantic Layer,” that mythical construct every data team eventually talks about building. It’s the idea of pulling all business logic, calculations, and definitions into a single place so everyone agrees on what the numbers actually mean. Anyone who has worked in data long enough knows the pain this is trying to solve. Logic gets scattered across pipelines, dashboards, notebooks, and random scripts, and before long, no one can explain why two reports show different answers for the same metric.
Despite decades of industry experience, we still struggle with this. Data teams continue to fight their way through repos, documentation, and tribal knowledge just to understand how a number is calculated. It’s not that we don’t know better—it’s that systems naturally drift toward complexity and inconsistency over time.

Polars’ Streaming Engine Is a Bigger Deal Than People Realize
If there’s one tool that still doesn’t get enough attention in our strange little data world, it’s Polars. It gets some love, sure, but not nearly what it deserves. I’ve been using it on and off since around 2022, and it was actually the first tool I used to replace a Databricks Spark job in production. That alone earns it a permanent spot in my stack.
I’m still very much a believer in what I’ve been calling the “Single Node Rebellion,” especially as teams start taking a harder look at data platform costs. In a world where compute bills can spiral quickly, tools like Polars feel less like a niche option and more like an obvious direction forward. There’s no real reason it shouldn’t play a major role in the modern data stack.

Every few years, Spark reinvents itself. First, it was Scala and RDDs. Then DataFrames. Then Python took over. Now we’re entering the era of declarative pipelines. You can complain about abstraction if you want. There’s always a small but passionate group that mourns the loss of some lower-level construct. They cling tightly to bespoke implementations and handcrafted orchestration logic as if it were sacred scripture.
But abstraction is the story of software. It always has been. I mean, look at SQL. It always comes back to win the game in the end, no matter how mad all the hardcore programmers get.
And Spark Declarative Pipelines (SDP), branded as Lakeflow Declarative Pipelines on Databricks, aren’t random. They are a response to how Spark is actually being used in the real world, making it approachable for the average Data Engineer. RDDs were not approachable for everyone.
If you don’t make things approachable, you lose your customer and user base.
Anyone who’s been around for more than a decade or so in the programming, development, and data world might get a slight eye twitch when the word database driver appears. Before the modern times we live in came along, the entire data world was driven by SQL Server, Oracle, with just a sprinkling of Postgres and MySQL … a-la AWS. That’s just the way it was.
Part of that joy was dealing with database drivers, such as JDBC and ODBC, which are language-neutral, OS-level standards for accessing databases.
It seems we have several cadres of people when it comes to “clean code.” I know there is a lot of previous baggage that comes with that nomenclature, good and bad. But, I think we can think about “clean code” from a simplistic point of view. It doesn’t have to be that complex.
We live in the Age of AI, in relation to the generation of code, of products, features … the software developer’s role has shifted. We can argue how it’s shifted, but it has.
If the generation of most of the mundane and everyday code is given to our AI peons like Cursor and Claude, then what value can you bring to the table?
You can bring a sense of good architecture from a systems perspective and from a “these modules of code” perspective. This data pipeline. Sure, some places, businesses just want you to churn out bits and bytes as fast as those tokens will let you, I feel bad for you. Many places still recognize the business context and keep the product running well … leading to happy customers who give us money … is extremely important.
There is an argument to be made that you should ensure you, or your AI, is producing clean code.
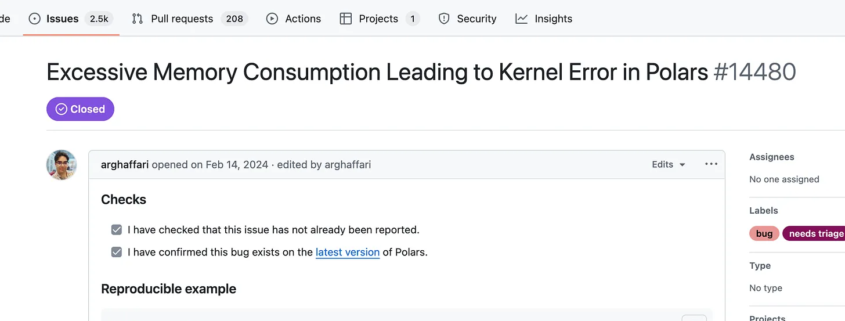
I’ve been a Polars bro for most of the last few years. Why? It’s Rust-based, fast, DataFrame-centric, just the way I like it. It also had the excellent feature, right from the start, of Lazy Execution. A few years ago, maybe two, I actually put Polars into production, running on Airflow, working with S3 and reading Delta Lake tables.
I was in love.
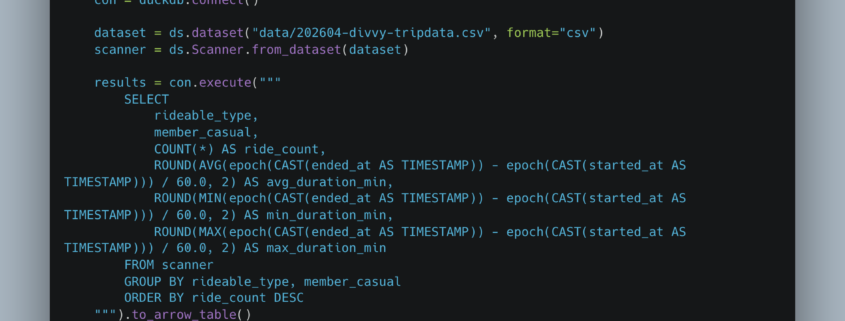
Over the last few years, I’ve found myself using PyArrow more and more for everyday data engineering things. Data ingestion, reading, and writing from various data sources and sinks. Most of us are familiar with Arrow and how it underpins a lot of new tech like DataFusion, and Arrow is used as an internal memory format.
But, small and mighty though it might be, the pyarrow Python package is a force to be reckoned with. Capable of blasting through all sorts of cloud-based datasets. It’s not particularly a data transformation framework, as much as a way to represent core datasets, transferring data hither and thither over the wire from one format to another.