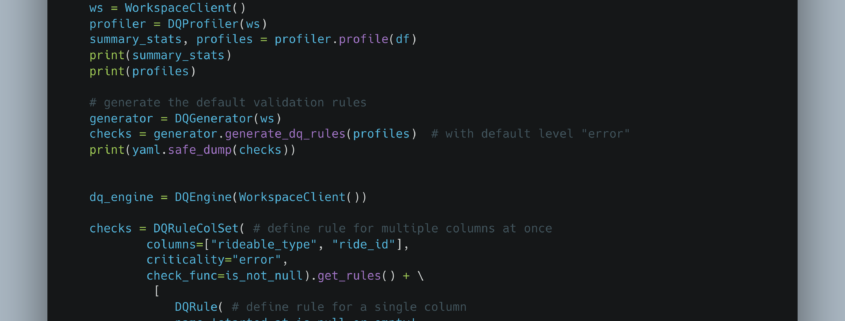
A Deep Dive into Databricks Labs’ DQX: The Data Quality Game Changer for PySpark DataFrames
Recently, a LinkedIn announcement caught my eye—and honestly, it had me on the edge of my seat. Databricks Labs has unveiled DQX, a Python-based Data Quality framework explicitly designed for PySpark DataFrames.
Finally, a Dedicated Data Quality Tool for PySpark
Data Quality has always been a cyclical topic in the data community. Despite its importance, it’s been hampered by a lack of simple, open-source tools. Yes, we have options like Soda Core and Great Expectations, but they can be cumbersome to integrate. Enter DQX.




