Data Quality – Great Expectations for Data Engineers

Mmmm … Data Quality … it is a thing these days. I look forlornly back to the ancient days of SQL Server when nobody cared about such things. Alas, we live in a different world, where hundreds of terabytes of data are the norm, and Data Quality becomes a thing. I’ve been meaning to give Great Expectations a poke for like a year, but just haven’t had the time or inclination to do so, but times are changing, and so should I.
I’m not really planning on giving an in-depth guide to Data Quality with Great Expectations, what I’m more interested in are topics like, how easy is it to set up and use, what’s the overhead, what are the main features and concepts and are they easy to understand. I find this sort of review of Data Engineering tools to be more helpful than simply a regurgitation of the documentation.
Introducing Great Expectations.
I have great expectations for Great Expectations. I had to say it at least once, couldn’t help it. It’s hard to know where to start with Data Quality, but it’s definitely becoming a more prominent discussion in Data Engineering. Huge distributed data sets have given rise to the need of simply knowing “what’s going on” and “what’s going wrong” with my data, type of questions.
Data at scale always presents challenges, and Data Quality is defiantly starting to become a big piece of that puzzle. I’ve had this experience and thought myself many times, “I have hundreds of terabytes of data, and more arriving every day, how do I know what that data looks like, how it’s changing, what bugs are being introduced?” I mean sure, you can roll your own stuff, which I’ve had experience with, but in the end, you write a code base and architect a system large enough to warrant its own repository and documentation, and it probably only caches a small subset of “meta-data” on your total data set.
So, Great Expectations is going to solve all our problems! We shall see. All my code is available in GitHub for this Great Expectations + Apache Spark setup.
“Great Expectations is a shared, open standard for data quality. It helps data teams eliminate pipeline debt, through data testing, documentation, and profiling.”
– Great Expectations website.
I tell you what, that sentence alone is like music to my ears.
- data testing
- documentation
- profiling
I would say as a Data Engineer who’s been doing data stuff forever, these 3 points do truly get at the crux of the issue when it comes to data. Testing all incoming data for quality and correctness, documentation of what data sets exist and simply “look like”, and profiling, or getting to “know what the data looks like.”
Getting your hands around these three topics would most likely put you light years ahead of most data organizations.

Installation of Great Expectations.
The first and most wonderful part of Great Expectations is that a person can apparently simply pip install it.
pip install great-expectationsTechnical Concepts of Great Expectations
I feel like many times this is the make or break for Data Engineering tool adoption. I’ve seen a lot of tools that are nice and fancy, but when it comes to the concepts, their documentation, ease of use, and implementation, they fall sadly short and therefore impeds adoption. So let’s review the main “concepts” or “building blocks” for working technically with Great Expectations and see what comes of it.
Here is my take on the concepts and what we will cover.
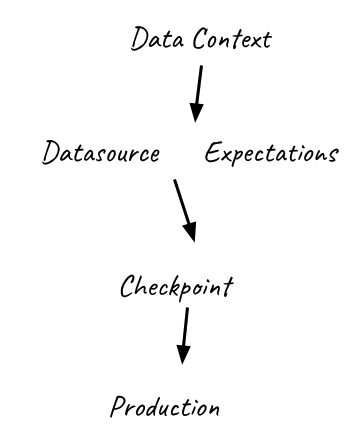
- Data Context
– Holds all configurations and below componets for your project. - Datasource
– Holds all configurations related to your data source(s) and interacting with them. - Expectation
– The actual tests and “expectations” that describe your data. - Checkpoint
– The validation that will run against your data, reporting metrics etc.
This is the order in which we will create our new Great Expectations project as well.
Data Context
Any perusal of the documentation will lead straight away to the concept of a Data Context. Clearly the entry point and starting point for any Great Expectations project. I would call it the Gandolf to the Fellowship of Data Quality.
The Data Context appears to hold all configurations related to your Data Quality project. It’s the key that holds information about the other concepts we will cover that are specific to a Great Expectation project, like Data Sources, Expectations, Profilers, Checkpoints, and the like.
The Data Context will be created during the setup of a Great Expectations project, and the documentation appears to favor their cli to do this.
Let’s understand this concept of a Data Context by setting one up. Running the following command in your terminal, inside your already created or soon to be created Data Engineering project.
great_expectations init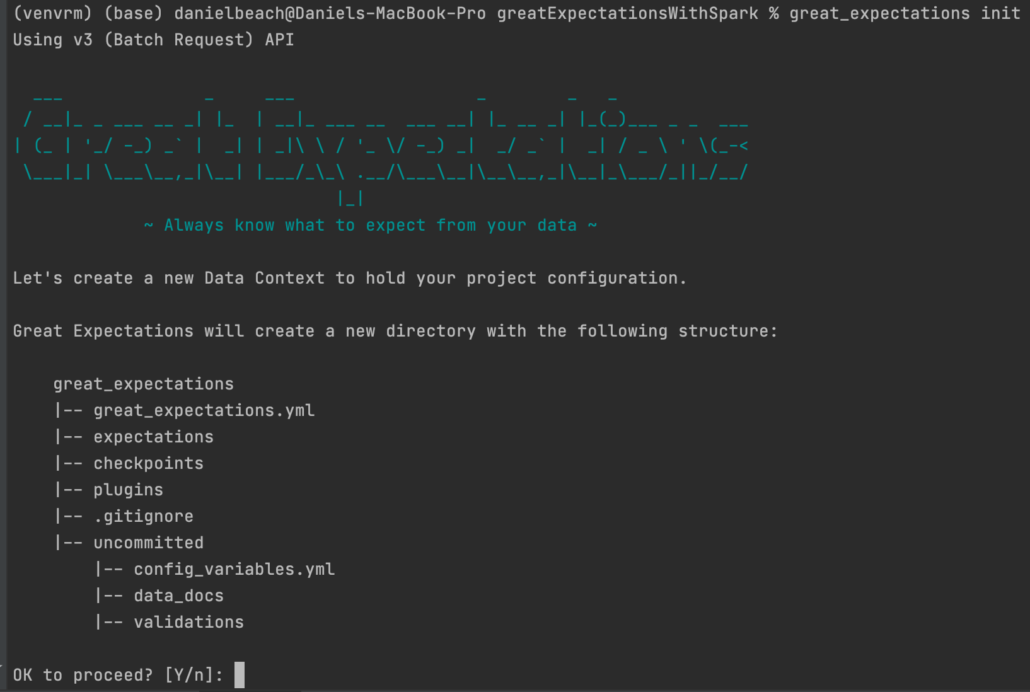
Apparently, the first order of business is that the cli, with the init command creates a bunch of new files as you can see in the above screenshot.
great_expectations
|-- great_expectations.yml
|-- expectations
|-- checkpoints
|-- plugins
|-- .gitignore
|-- uncommitted
|-- config_variables.yml
|-- data_docs
|-- validationsMy only side comment about this is that every new file added to my repo is another file that I have to manage and worry about. I’m probably just scarred from working in organizations where you were told to use this “cookie-cutter” repository that generated 2,000-3,000 lines of code before I wrote a single line myself. Sounds good in practice but in reality that can turn into a nightmare.
All I’m saying is that I hope these files don’t get carried away. The message we get after creating our first Great Expectations project gives an idea of the concepts and steps to come. It’s almost hard to know where to start.
Congratulations! You are now ready to customize your Great Expectations configuration.
You can customize your configuration in many ways. Here are some examples:
Use the CLI to:
- Run `great_expectations datasource new` to connect to your data.
- Run `great_expectations checkpoint new <checkpoint_name>` to bundle data with Expectation Suite(s) in a Checkpoint for later re-validation.
- Run `great_expectations suite --help` to create, edit, list, profile Expectation Suites.
- Run `great_expectations docs --help` to build and manage Data Docs sites.
Edit your configuration in great_expectations.yml to:
- Move Stores to the cloud
- Add Slack notifications, PagerDuty alerts, etc.
- Customize your Data Docs
Please see our documentation for more configuration options!Let’s start in the next obvious place.
Datasource
The next obvious concept for Great Expectations is Datasource. Didn’t see that coming … wait, yes I did.
“A Datasource provides a standard API for accessing and interacting with data from a wide variety of source systems.”
Great Expectations docs
I just figured this would be some sort of pointer to file(s), but they make it sound all fancy. An API for my data? I guess we will see. Let’s just again create a simple Datasource and see what happens. (I’m going to use the simple Divvy Bike trips free CSV dataset)
great_expectations datasource newHere is the dialogue that opens up. We will choose our local Datasource to make things easy.
(venvrm) (base) danielbeach@Daniels-MacBook-Pro greatExpectationsWithSpark % great_expectations datasource new
Using v3 (Batch Request) API
What data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL)
: 1
What are you processing your files with?
1. Pandas
2. PySpark
: 2Not going to lie, they are making this easy so far. But, the next part where I entered the path to my local files I wasn’t expecting. My PyCharm went crazy and Great Expectations kicked me over to a Jupyter Notebook.
Enter the path of the root directory where the data files are stored. If files are on local disk enter a path relative to your current working directory or an absolute path.
: data
Please install the optional dependency 'black' to enable linting. Returning input with no changes.
Because you requested to create a new Datasource, we'll open a notebook for you now to complete it!
[I 19:57:37.107 NotebookApp] Writing notebook server cookie secret to /Users/danielbeach/Library/Jupyter/runtime/notebook_cookie_secret
[I 19:57:37.360 NotebookApp] Serving notebooks from local directory: /Users/danielbeach/PycharmProjects/greatExpectationsWithSpark/great_expectations/uncommitted
[I 19:57:37.360 NotebookApp] Jupyter Notebook 6.4.10 is running at:
[I 19:57:37.360 NotebookApp] http://localhost:8888/?token=0472fe066a7a287d3af843256f344f2dcc5a6296b1e1983a
[I 19:57:37.360 NotebookApp] or http://127.0.0.1:8888/?token=0472fe066a7a287d3af843256f344f2dcc5a6296b1e1983a
[I 19:57:37.360 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:57:37.375 NotebookApp]
To access the notebook, open this file in a browser:
file:///Users/danielbeach/Library/Jupyter/runtime/nbserver-69663-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=0472fe066a7a287d3af843256f344f2dcc5a6296b1e1983a
or http://127.0.0.1:8888/?token=0472fe066a7a287d3af843256f344f2dcc5a6296b1e1983a
[I 19:57:40.111 NotebookApp] Writing notebook-signing key to /Users/danielbeach/Library/Jupyter/notebook_secret
[W 19:57:40.112 NotebookApp] Notebook datasource_new.ipynb is not trusted
[I 19:57:40.843 NotebookApp] Kernel started: 54a0244e-beb7-4062-b35e-b8a073e0b954, name: python3
[IPKernelApp] ERROR | No such comm target registered: jupyter.widget.control
[IPKernelApp] WARNING | No such comm: bac9e973-3c5b-4511-a4c2-89c14af2a483
I wasn’t too sure of what to do next, so it was back to the documentation. After inspecting the documentation and Notebook a little closer, it appears the Notebook was just doing for me automatically what the documentation shows … writing a yaml or Python dict that describes the data source. See this documentation. Honestly, it was and is a little overwhelming at first.
So far the setup has been super easy, but the documentation at this point talks about execution engines and other such topics that weren’t pointed out earlier. In my case, I’m doing a Apache Spark project. Either way, I just changed the data source name in the Notebook that populated and ran it. A the bottom of the Notebook I could see it generated some configuration code for me.
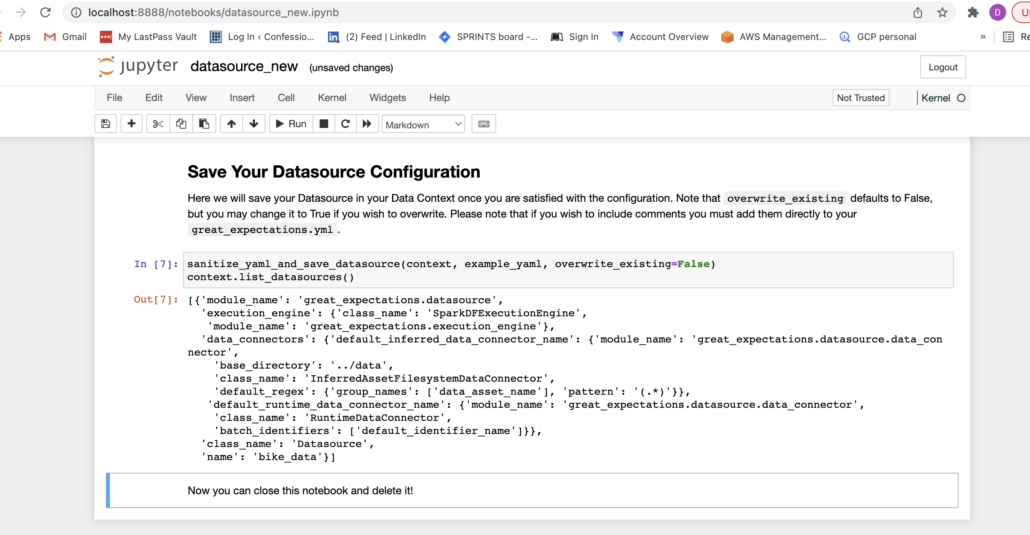
Apparently, something worked … when I run great_expectations datasource list I can see my bike_data source.
(venvrm) (base) danielbeach@Daniels-MacBook-Pro greatExpectationsWithSpark % great_expectations datasource list
Using v3 (Batch Request) API
1 Datasource found:
- name: bike_data
class_name: DatasourceThe next part is where my head started to spin. See this documentation. The documentation starts to go into great detail about DataConnector classes, talking about the types of them and which one you should choose. Honestly, things went from really straightforward to not so much very quickly. Looking back at the auto-generated data source configuration, it shows some default Data Connector classes, but I don’t know if I’m supposed to leave that or change it.
I guess I’m going to call it good and come back later to it if it doesn’t work.
Expectations
So now that we’ve got everything installed, project setup, and apparently the Datasource set up locally, the next step would be creating an Expectation. Once you read the Great Expectation documentation on Expectations, it becomes more clear what is going on. This is a broad topic to cover, and there are numerous ways of creating Expectations, from interactive/suggested Expectations … to making your own from scratch.
- Interactive Expectation generation.
- Proflier (auto-generated using data) Expectations.
- Manually define Expectations.
Also, we have the concept of Expectation Suites, groupings of our Expectations, I would expect maybe in large Data Quality projects we might have different suites for our different data sources.
Enough, let’s use the Proflier option to see if we can generate some Expectations. One disappointing note is that the documentation for the Proflier says “These Expectations are deliberately over-fitted on your data … Thus, the intention is for this Expectation Suite to be edited and updated to better suit your specific use case – it is not specifically intended to be used as is.”
So I can use it … but I can’t. Oh well, let’s try it.
great_expectations suite new --profile
(venvrm) (base) danielbeach@Daniels-MacBook-Pro greatExpectationsWithSpark % great_expectations suite new --profile
Using v3 (Batch Request) API
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
A batch of data is required to edit the suite - let's help you to specify it.
Which data asset (accessible by data connector "default_inferred_data_connector_name") would you like to use?
1. 202201-divvy-tripdata.csv
2. 202202-divvy-tripdata.csv
Type [n] to see the next page or [p] for the previous. When you're ready to select an asset, enter the index.
: 1
Name the new Expectation Suite [202201-divvy-tripdata.csv.warning]: bikes
Great Expectations will create a notebook, containing code cells that select from available columns in your dataset and
generate expectations about them to demonstrate some examples of assertions you can make about your data.
When you run this notebook, Great Expectations will store these expectations in a new Expectation Suite "bikes" here:
file:///Users/danielbeach/PycharmProjects/greatExpectationsWithSpark/great_expectations/expectations/bikes.json
Would you like to proceed? [Y/n]: yAgain we are thrown into the Notebook that generates our Profiler expectation suite.
After running this Notebook, two Expectations were generated. Basically
- the columns should be in this order
- the number of rows show be X.
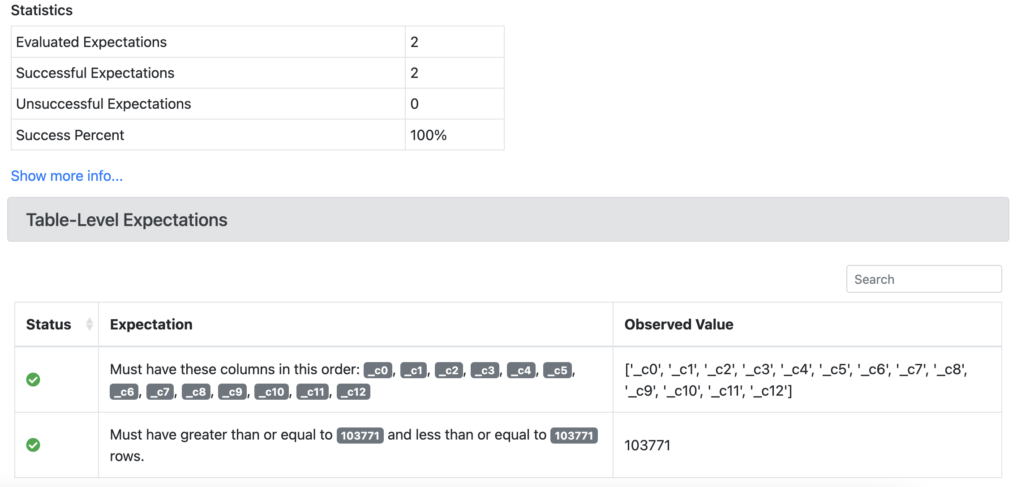
I am a little disappointed by the Proflier generated Expectations, but you know, I get it, and this gives a good base and a place to start. I also noticed our initial Datasource didn’t catch our column names of the CSV.
Checkpoint / Validate
It appears that the Checkpoint is the last piece of the puzzle, pulling together everything we’ve done into actually acting upon our data.
“They will validate data, save Validation Results, run any Actions you have specified, and finally create Data Docs with their results”
Great Expectation docs.
Let’s just dive in and try it.
great_expectations checkpoint new my_checkpointAgain, we get a Notebook pop that is pre-populated.
Again, I just run through the Notebook, taking all the defaults and some Checkpoint are apparently created for me. I want to point out that so far, while these Notebooks are nice, they appear to be complex and have a lot of options you should work on. This tool appears to be great, easy to set up and use, but use properly? It’s going to take some serious research and dedication to ferret out and understand every nuance of these main concepts and implement them correctly.
Also, note that as I’ve been running these commands, magically files are appearing in my repo.
Also, once a Checkpoint has run, we get some files in our data_docs folder of the project. The html file contains a visual of the results and Expectations.
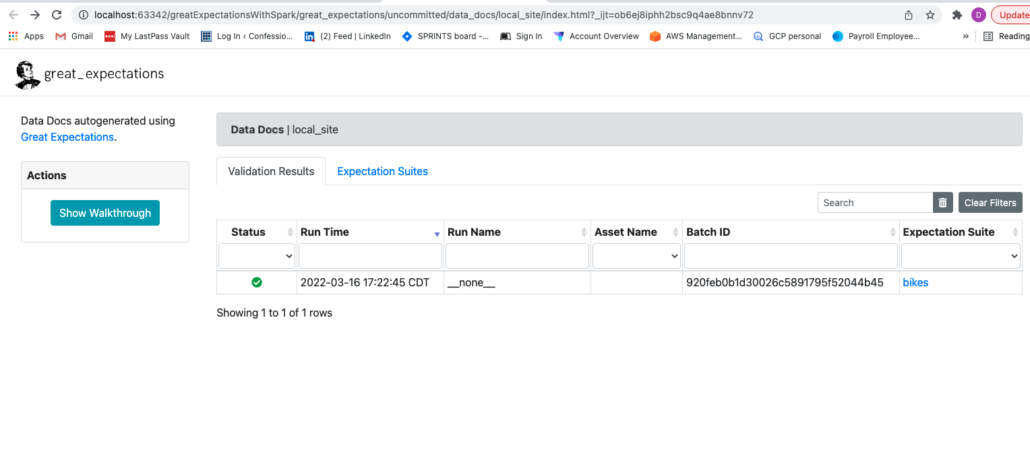
Wait, not done yet. After creating a new Checkpoint we have to generate a script that we can use to do this on a regular basis, aka as part of our data pipeline … or its own data pipeline.
great_expectations checkpoint script my_checkpointAfter running this command Great Expectations generates creates a Python file.
(venvrm) (base) danielbeach@Daniels-MacBook-Pro greatExpectationsWithSpark % great_expectations checkpoint script my_checkpoint
Using v3 (Batch Request) API
A python script was created that runs the Checkpoint named: `my_checkpoint`
- The script is located in `great_expectations/uncommitted/run_my_checkpoint.py`
- The script can be run with `python great_expectations/uncommitted/run_my_checkpoint.py`Below are the contents.
"""
This is a basic generated Great Expectations script that runs a Checkpoint.
Checkpoints are the primary method for validating batches of data in production and triggering any followup actions.
A Checkpoint facilitates running a validation as well as configurable Actions such as updating Data Docs, sending a
notification to team members about validation results, or storing a result in a shared cloud storage.
See also <cyan>https://docs.greatexpectations.io/en/latest/guides/how_to_guides/validation/how_to_create_a_new_checkpoint_using_test_yaml_config.html</cyan> for more information about the Checkpoints and how to configure them in your Great Expectations environment.
Checkpoints can be run directly without this script using the `great_expectations checkpoint run` command. This script
is provided for those who wish to run Checkpoints in python.
Usage:
- Run this file: `python great_expectations/uncommitted/run_my_checkpoint.py`.
- This can be run manually or via a scheduler such, as cron.
- If your pipeline runner supports python snippets, then you can paste this into your pipeline.
"""
import sys
from great_expectations.checkpoint.types.checkpoint_result import CheckpointResult
from great_expectations.data_context import DataContext
data_context: DataContext = DataContext(context_root_dir="/Users/danielbeach/PycharmProjects/greatExpectationsWithSpark/great_expectations")
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name="my_checkpoint",
batch_request=None,
run_name=None,
)
if not result["success"]:
print("Validation failed!")
sys.exit(1)
print("Validation succeeded!")
sys.exit(0)Well, finally we have a Python file that could be configured and run through some pipeline! I’m curious of folks generate these files and schedule them separately, or imbed them right into the production data pipelines.
Musings on Great Expectations
Yikes, that was a lot, my head is still spinning. I pretty sure I barely scratched the surface, it’s impressive how much depth there is to Great Expectations, it’s almost too much. Here are my take aways about Great Expectations.
- It’s an impressive Data Quality tool with a wide range of features.
- It would be a serious undertaking to use and implement all of Great Expectation’s features.
- You will have to read the documentation 3 times through to catch everything.
- Great Expectations can easily solve most data quality issues that are common to Data Engineering.
- It’s a configuration nightmare.
- I wonder how well it works in the cloud with cloud based data sources and sinks.
It’s been along time since I’ve been impressed with a Data Engineering tool like this. It’s incredible the amount of configuration and range of Data Quality checks that could be written using Great Expectations. Also, this tool is not for the faint of heart, it’s one downfall appears to be that this tool is designed for Engineer’s and would take a serious amount of learning, effort, code, and configuration to implement well. It isn’t a tool (well, the output would be) for Data Analysts, folks who usually deal with Data Quality.
I’m definitely excited to use the tool more, I plan to do some more testing around it. It screams “use me” for Databricks + Delta Lake, but that probably brings a whole layer of complexity. From what I can tell this tool is one of the few that would be worth the headache to learn and implement.
I think the learning curve would be a little steep and require some serious upfront effort to implement, but once in place … I’ve never seen another system I’m my life that could provide this type of Data Quality at scale.
Would it scale well compared to sql when we apply individual column level expectations? Or would databricks take care of that load if available