Databricks Access Control – The 3 Most Important Steps

It’s not often I yearn for the good old days of SQL Server, but I’ve had a few of those moments lately. Some things I miss, some I don’t, and it’s probably because I’m getting old and crusty, stuck in my ways, by permissioning is one of those topics where I think about the good old days. Data access control and permissions are topics that we all kinda ignore as not that important … until we actually are trying to do something with them. Then all of sudden we start complaining about complexity and why this isn’t easier. That’s a good way to describe my reaction to having to work on Databricks Access control.
But, I learned a few things and I think they will be helpful for someone. Read on for the basics of handling permissions and access control in Databricks and Delta Lake.
Overview of Data Access Control and Permissions in Databricks and Delta Lake.
I have this topic of access and permission controls to be very tedious and mundane. Sorry to all you administrators out there, it’s just the way I am. From my days of SQL Server to SAP products and heaven forbid AWS, I always get a little bit weepy when I have to work on permissions. I’m not sure what it is about those tasks, but it’s always such a headache, and nothing works like it’s supposed to.
Enough war stories.
Let’s talk at a super high level about Databricks and Delta Lake, and our options for Access and Data control. I’m going to keep it very high level and show you the basics of what will probably get you 90% of the way down the road, the rest is up to you.
Four Approaches to Access and Permissions for Databricks + Delta Lake.
At a high level, I see three ways you can control access to data and features inside Databricks (AWS).
- Admin User Console
AWSinstance profiles.- Cluster Access Control
- Table Access Control
So let’s start with the first thing to know.
Admin User Console
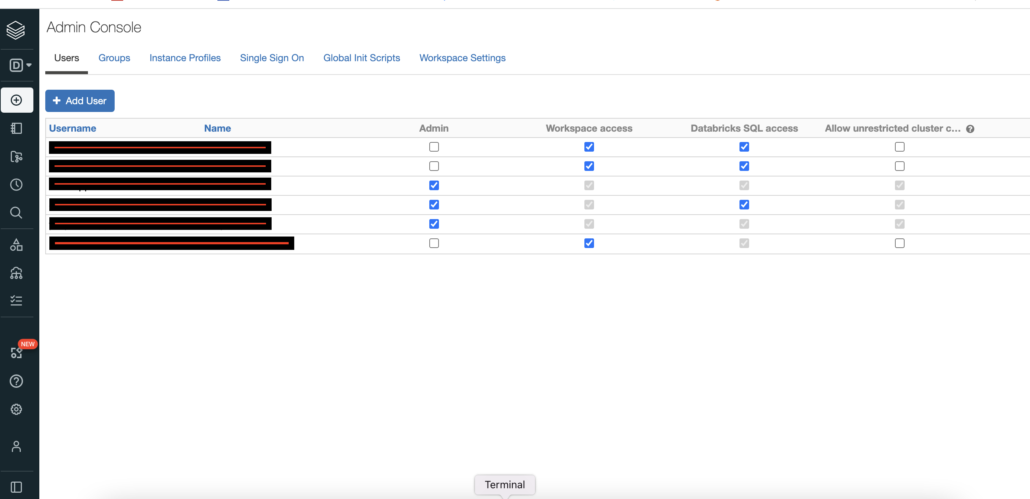
The Admin Console in Databricks is your first line of defense when it comes to access and permissions. From this UI as you can see, you can add a User via their email and control a few obvious settings like … is this person an Admin or not, can they access the Workspaces, DatabricksSQL, or be able to create their own Clusters willy-nilly.
Most likely the new Users will not be Admins but they will probably need Workspace Access, using DatabricksSQL is pretty standard, and depending on who they are, a developer or just a consumer, you may or may not want them to have Allow unrestricted cluster creation.
Controling access at the Cluster level.
So once you have Users in your Databricks account, the next obvious question is going to be … what do I want this person to do, or NOT to do more likely. It’s easy to just trust people, but that can be dangerous.
One thing to remember is that (except Databricks Serverless SQL) most folks have to interact with Spark or Delta Lake, or whatever they are doing with Databricks, that the Compute is going to have to run on some Cluster. This makes managing Cluster level permissions somewhat important. I’m going to couple this topic with AWS instance profiles.
It’s worth noting that you need a Premium Databricks account to get Cluster level access controls.
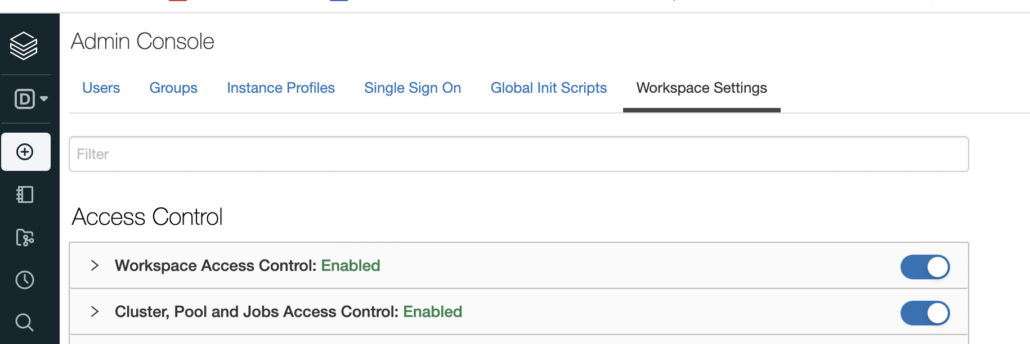
First, you will have to go to Workspace Settings and turn on the Cluster Access Control. Once this feature is turned on, you can control who can access your Cluster(s) and what they can do with those clusters.
For example you can add a user or group and …
- Can Manage
- Can Restart
- Can Attach To
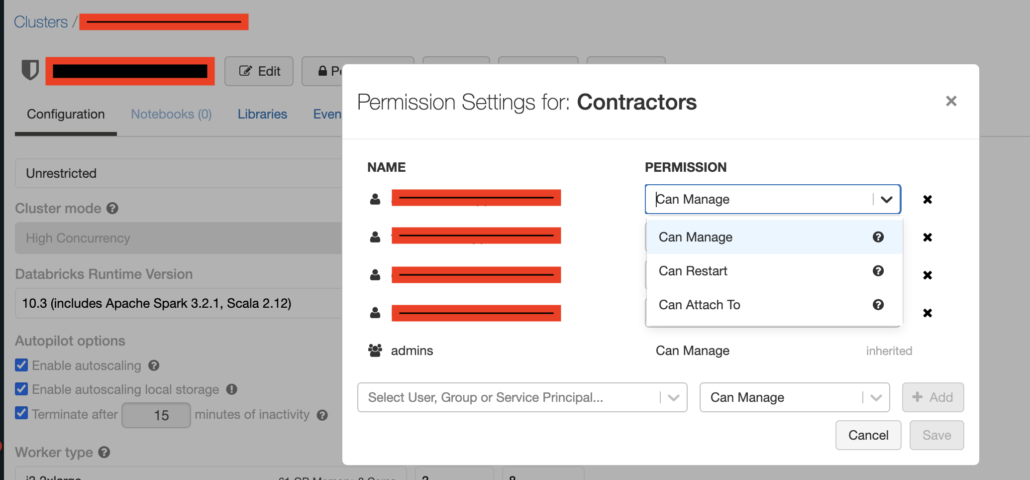
There’s probably lot’s of Users you want to be able to Attach to and use a Cluster , but not necessarily Manage a cluster.
Don’t forget to attach instance profiles to your Clusters to control actions on AWS, especially s3 storage.
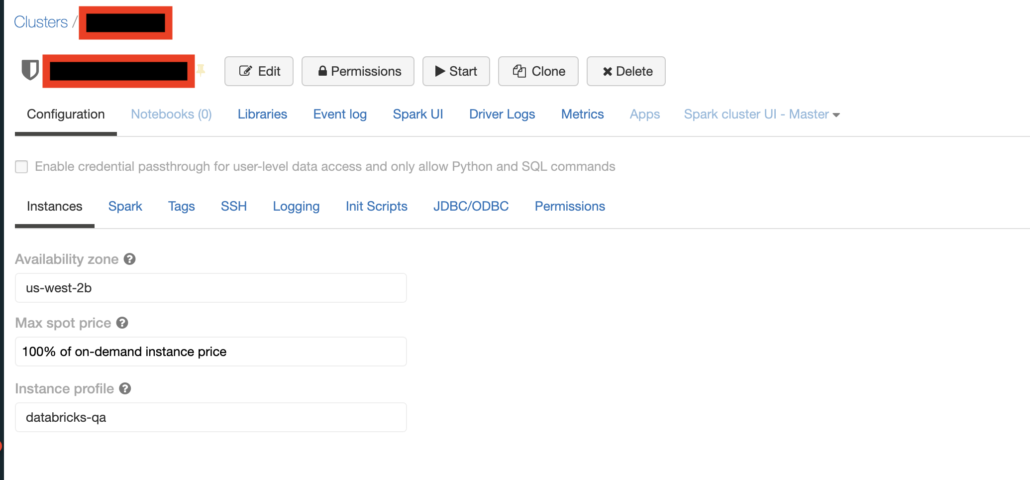
At the bottom of the above screenshot, you can see the important but small option of attaching an AWS instance profile to the cluster. This is important for say, a Cluster your general analytics users, to not be able to delete an s3 objects. You could control this, by attaching an instance profile that has read only access to s3 for example.
Table Access control.
The last and most important feature of controlling data access in Databricks, is Table Access control. Unfortunatley it’s the most annoying of all.
Once your Table Access Control is turned on, you are free to run the millions of SQL commands granting or revoking certain privileges on Delta objects.
You can read all about GRANT statements on the Databricks website. The documentation in this aspect is terribly lacking, and simply tells you to do …
GRANT privilege_types ON securable_object TO principal
What Databricks is lacking is a good simple overview of how should you approach data access control, and what your high level options are. I would boil it down to the following points.
- If you put your Delta
tablesin adatabase, you canGRANTaccess or remove access at thedatabaselevel, which is super helpful.- For example, if you keep a
databaseforproduction, this is great way to revoke who can access production tables.
- For example, if you keep a
- Most likey there are a set of uses you want to have only
SELECTcapabilities ontables. ` - A very helpful permission is to
REVOKEtheMODIFYprivilages ontables.
Most of your use cases are probably going to be these simple features, keep someone(s) from doing any sort of DELETE or UPDATE etc to your table(s) or database(s), as well as just simply giving someone(s) SELECT permission.
REVOKE MODIFY ON TABLE my_table FROM 'some_user@bad.com';
GRANT SELECT ON TABLE my_table TO 'big@bad.com`;The unfortunate part right now is no UI to make these changes in mass, you have to write loops and such when you have a large number of tables and users you need to run statements on. Here is an example of revoking MODIFY on all tables in a database to some user.
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)
## This code must be run on DBSQL Cluster via a Notebook.
## This script must be run on a cluster with Table Access Control configured.
## https://docs.databricks.com/security/access-control/table-acls/table-acl.html
## See cluster Admin in DatabricksSQL premium account.
CONTRACTOR = 'contractor@bingbong.com'
databaseList = ['production', 'integration']
for db in databaseList:
listTables = sqlContext.sql("show tables from "+db)
tableRows = listTables.collect()
for table in tableRows:
revokeCommand=sqlContext.sql("REVOKE MODIFY ON "+table['database']+"."+table['tableName']+f" FROM `{CONTRACTOR}`")
print("Revoked the MODIFY permissions on "+table['database']+"."+table['tableName']+f" for {CONTRACTOR}")Somewhat annoying, but not the end of the world to have to configure a bunch of scripts like this to run through users and database objects.
Musings
I think that’s all about you need to know starting out with permission and access control with Databricks. I wish their documentation gave a more high level overview of options and approaches to approach this topic. It’s still a task I will always hate, it seems tedious and it’s never easy or obvious with set of buttons to click and commands to run. A decade ago in SQL Server it was the same exact problem, not much has changed. Simply, how do I can control someone from doing something bad to this table or database.
For Databricks and Delta Lake it comes down to a few topics.
- Control the access to
Clustersand what people can do withClusters - Control access to database
tablesanddatabasesby runningREVOKEorGRANTcommands.
Hopefully Databricks comes out with some nice UI features to simply wholesale give or revoke permissions on tables and databases, because in the end, this problem has been around for a long time and it shouldn’t be hard to solve.