Apache Arrow as Data Interchange
Apache Arrow entered the data scene quietly; for years, it languished in obscurity, unheard of and uncared for by the data community. Back in the olden days of 2022, which feels like another world, I was happily using and writing about Arrow as a data processing tool. A lot has changed since then, and Arrow has catapulted its way into everyday data engineering conversations.
- This is the 2022 article, if you’re interested.

Apache Arrow took an interesting approach, unlike others, to implant itself slowly and quietly in places beneath the castles of power and out of the sight of the average data user. Very much unlike tools that vie for the interface at the user level, DuckDB, Polars, Daft, Spark … Arrow came up from the bottom of the stack, inserting itself into the middle of the data stack.
Apache Arrow is an open-source project designed to make data processing faster and more efficient across different programming languages and systems.
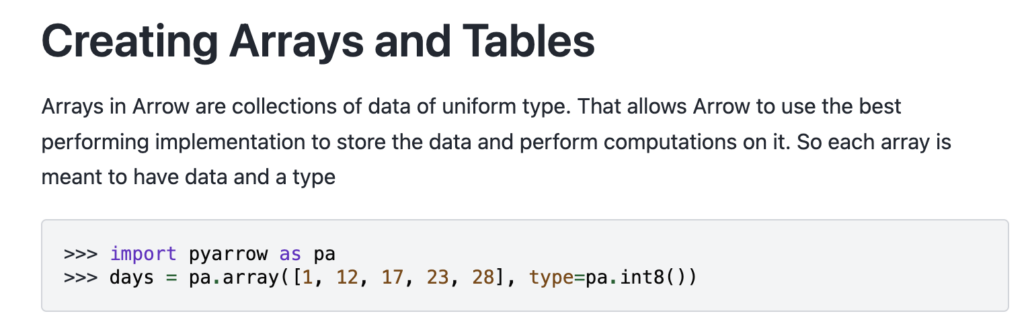
At its core, Apache Arrow defines a standardized in-memory columnar data format. Instead of every tool or library storing data differently in RAM, Arrow provides a shared memory layout that systems can use without constantly converting or copying data between formats.
Sure, you can use something like Python and interact with Arrow directly for data processing.

But, methinks, while a small subset of users might do this, most likely this will never become the main use case for Apache Arrow, direct access via specific libraries that is.
Arrow as the data layer.
Instead, Arrow is now a core part of many tools, almost as an optional extension to data processing frameworks.
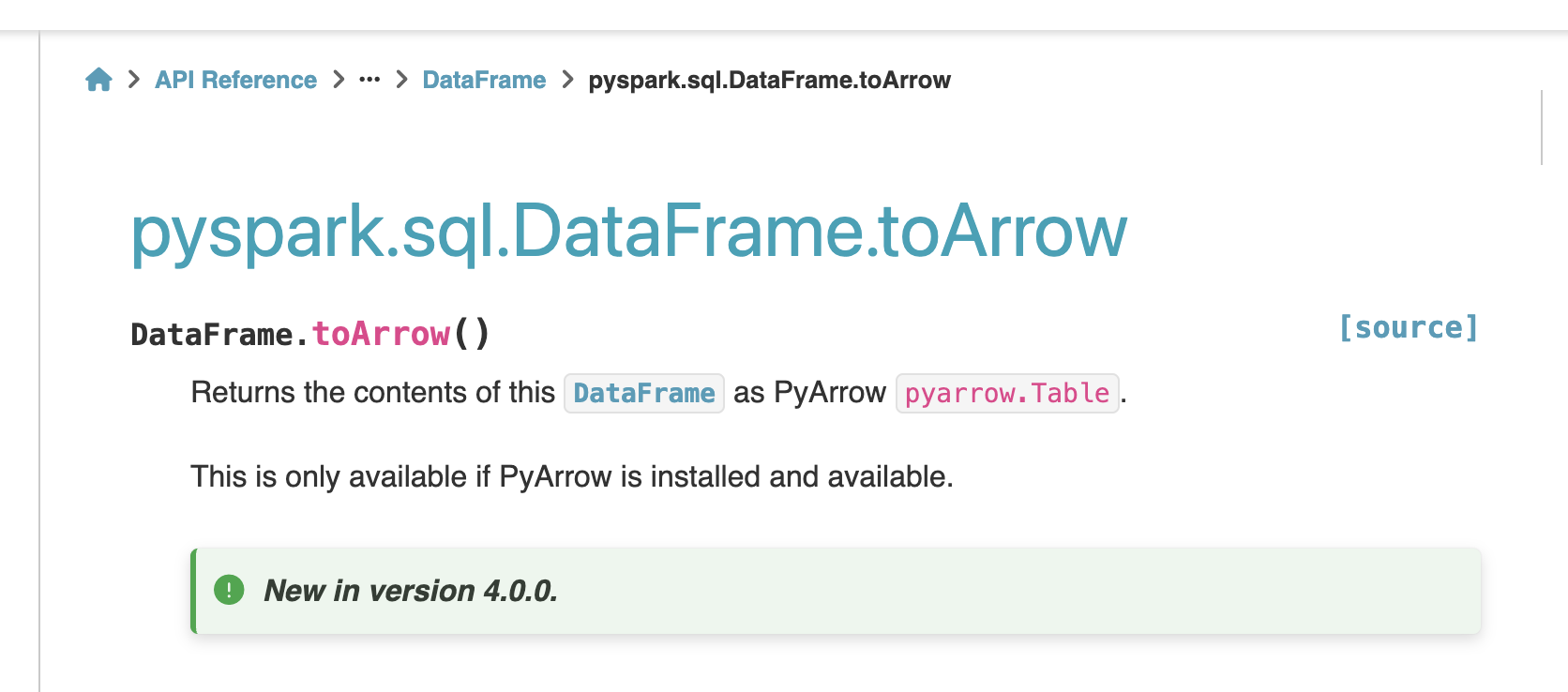

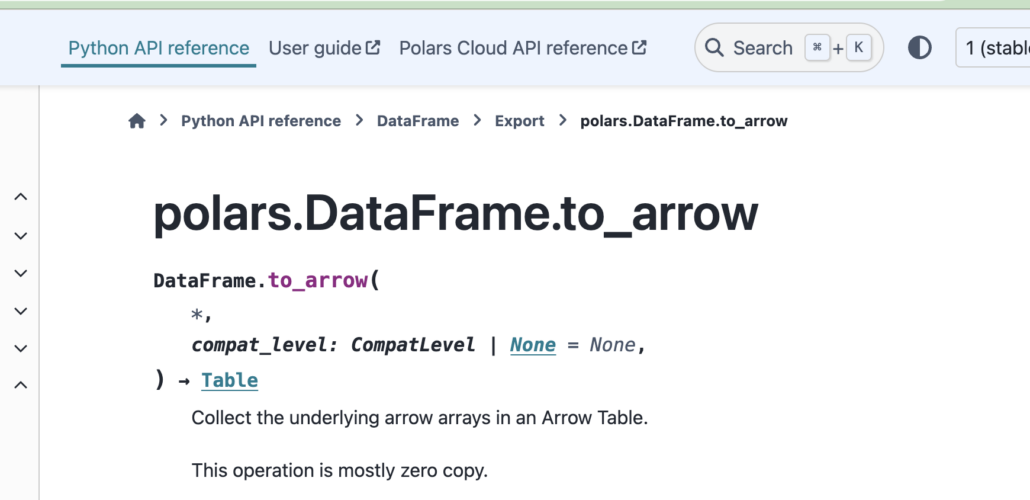
Is that enough for you to get the picture? Apache Arrow is the data interchange (zero copy) of choice for many data tools. This should bring up a question in your mind, and mine, why would you, when using Apache Spark, DuckDb, Polars … whatever, would you choose to NOT use whatever the default is for your tool, like a Spark RDD, and instead use an Arrow table or RecordBatch.
The normal problem without Arrow
Traditionally, moving data between systems looks like this:
Database -> CSV/JSON/Row Objects -> Python Objects -> Pandas -> Spark -> ML ToolAt each step:
- Data is serialized/deserialized
- Memory is reallocated
- Rows are transformed into different internal formats
- CPU burns cycles copying bytes around
That copying is surprisingly expensive, especially for analytics workloads with millions or billions of rows.
For example:
- PostgreSQL stores data in one way
- Pandas store it another way
- Spark another
- NumPy another
- Polars another
So data constantly gets translated.
Arrow’s approach
Arrow defines a universal columnar memory format.
Instead of converting data between systems:
System A ---> Arrow Memory ---> System BBoth systems understand the exact same memory layout, and this is where, my friend, we get the real benefit of Arrow. We’ve known for some time that columnar formats are quick and fast for most data operations. But the real performance gain comes from zero-copy data transmission, with no serialization or deserialization to slow the process.
So, will you see immense gains using Apache Arrow over … something else?
It depends on your use case and the current pipelines. For example, it appears Polars uses in-memory formats that conform to Apache Arrow specs.
I think the hope is that, over time, many such data processing tools will default to using Arrow as the in-memory format, so it’s seamless and straightforward, almost invisible.