Web Scraping + Sentiment + Spark Streaming + Postgres = Dooms Day Clock! PART 1.
So after watching way too many end of the world movies on Netflix I decided the best way to prepare for the Zombie Apocalypse would be to give myself a way to know when the dead are about to crash through my living room window (while I’m eating popcorn watching zombies on on Netflix of course). This is one reason I love Python, I knew I would barely have to write any code to do this. I figured if I could scrape the popular news sites and do some simple sentiment analysis, get the government threat levels, some weather alerts etc, jam all this data together I would get a perfect Dooms Day clock to tell me how close we are to the end of the world on any given day. So lets begin. All the code is on GitHub. Here is visual of what I wanted.
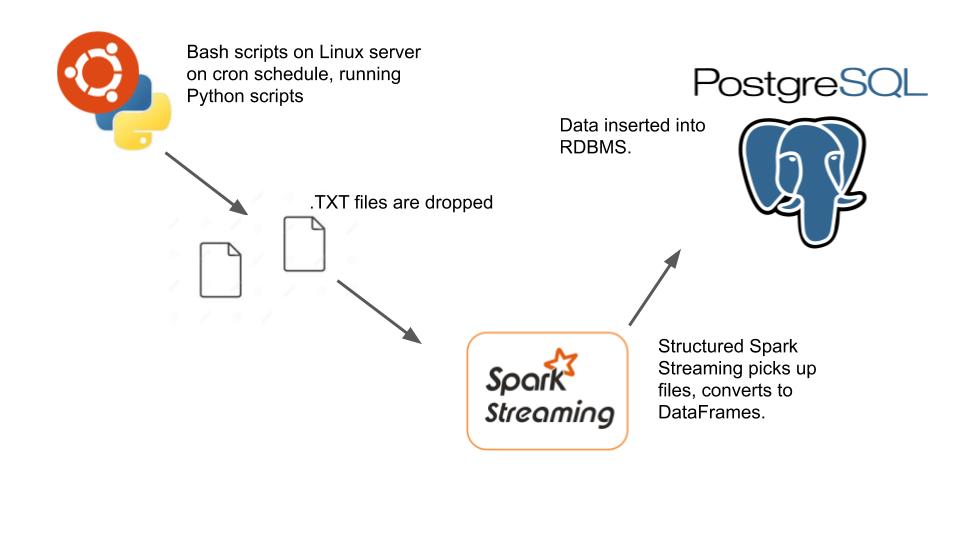
Basically I would want to use my Linode servers to schedule a .sh file to run a Python script, to dump files, to get picked up by my Spark Cluster to stream the data into my Postgres database. So first things first, let’s start with getting the data.
Web Scraping with Python.
You don’t need much to scrape whatever you want from web pages with Python. Everything always starts with the following line.
from bs4 import BeautifulSoup
import asyncio
from aiohttp import ClientSessionBeautifulSoup (bs4) is an awesome Python package that makes dealing with raw HTML super simple. For example, if you have a bunch of raw HTML and just want the actual text and not the HTML code itself, it’s as easy as .getText() .
The other two packages that rock are asyncio and aiohttp, these two gems will speed up the rate at which you can call multiple web urls and retrieve the data you want. Since Python has the famous GIL problem, asyncio was one of the communities response to deal with that issue. aiohttp is the async compatible version of the popular requests package. What’s that look like?
import asyncio
from aiohttp import ClientSession
from bs4 import BeautifulSoup
from textblob import TextBlob
from datetime import datetime
import os
async def fetch(url, session):
async with session.get(url) as response:
return await response.read()
async def run():
urls = ['http://www.cnn.com',
'http://www.foxnews.com',
'http://www.nbcnews.com',
'http://www.abcnews.com',
'http://www.usatoday.com/news',
'https://www.bbc.com/news/world']
tasks = []
async with ClientSession() as session:
for url in urls:
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
responses = await asyncio.gather(*tasks)
return responses
def get_response_text(response):
if response:
soup = BeautifulSoup(response, 'html.parser')
page = soup.find().getText()
return page
def get_sentiment(text):
opinion = TextBlob(text)
return opinion.sentiment[0] #polarity 1 very postive, -1 negative
if __name__ == '__main__':
date = datetime.now()
cwd = os.getcwd()
filename = 'news-{year}-{month}-{day}-{minute}'.format(year=date.year, month=date.month, day=date.day, minute=date.minute)
file = open("{cwd}/doomsday/{file_name}.txt".format(cwd=cwd, file_name=filename), "w")
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(run())
responses = loop.run_until_complete(future)
setiment_list = []
for response in responses:
text = get_response_text(response)
output = get_sentiment(text)
setiment_list.append(output)
for setiment in setiment_list:
file.write(str(setiment) + ' \n')
file.close()Few things I want to point out. If you’re new to async in Python it’s really not that bad. Any function you want to be called asynchronously just needs the async keyword in front of it. Also, think about what you want don’t want to sit around waiting for. You would await that, so a example from above. I want to asynchronously retrieve URL’s, because some websites might be faster or slower than others, then I want to await the response.
async def fetch(url, session):
async with session.get(url) as response:
return await response.read()The other important part of asyncio is the event loop. I suggest some light reading on the subject.
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(run())
responses = loop.run_until_complete(future)Let’s quickly talk about how easy bs4 is to use. So now that I was retrieving the homepage for the news sites, I wanted to get the text from them and do simple sentiment analysis. I mean does it get any easier?
soup = BeautifulSoup(response, 'html.parser')
page = soup.find().getText()Then finally getting the sentiment from the text, using TextBlob of course, another credit to human-kind for creating something so easy to use.
def get_sentiment(text):
opinion = TextBlob(text)
return opinion.sentiment[0] #polarity 1 very postive, -1 negativeFYI. I’m also downloading the threat alerts from DHS. The script is very similar and can be found on GitHub, it’s also pumping the results to a text file. Let’s move onto Spark (pySpark) structured streaming next. Let’s just see the code and then talk about it. (FYI, its not really production code, it does some dumb things like open a connection to the database for every row in a dataframe.)
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
import psycopg2
from datetime import datetime
fileschema = StructType().add("column1", StringType(), True)
def insert_record(record):
try:
connection = psycopg2.connect(
user = "XXXXXX",
password = "",
host = "45.79.XX.XXX",
port= "5432",
database = "doomsday"
)
cursor = connection.cursor()
except (Exception, psycopg2.Error) as error:
print(error)
query = "INSERT INTO threats (threat, insert_date) VALUES (%s, %s);"
data = (record, datetime.now())
try:
cursor.execute(query, data)
connection.commit()
cursor.close()
connection.close()
except (Exception, psycopg2.Error) as error:
print(error)
spark = SparkSession \
.builder \
.appName("StructuredThreats") \
.master("local[*]") \
.getOrCreate()
threatsDataFrame = spark \
.readStream \
.csv(path="file:///home/hadoop/doomsday/threats/",
schema= fileschema,
sep=",",
header=False)
query = threatsDataFrame.writeStream.foreach(insert_record).trigger(processingTime='5 seconds').start()
query.awaitTermination()Spark Streaming has been around for awhile, it produces a DStream of RDD’s, which can be transformed. It is a powerful system, yet a lot of people complain about missing features known to Spark SQL and DataFrames. People love dataframes because it’s very similar to a Pandas dataframe in the way it acts. Also, Spark’s Structured Streaming abstracts away a lot of the detail and lets the developer focus on the data and what they want to do with it. I’m a fan. After getting your Spark session up and running, it’s really as simple as follows.
threatsDataFrame = spark \
.readStream \
.csv(path="file:///home/hadoop/doomsday/threats/",
schema= fileschema,
sep=",",
header=False)
query = threatsDataFrame.writeStream.foreach(insert_record).trigger(processingTime='5 seconds').start()We basically .readStream, it’s text files so we can use .csv , feed the path and schema (with Structured Streaming you have to tell Spark the schema before hand).
Then it’s really what do we want to do with the streaming query, well .writeStream for sure! Using the .foreach allows us to apply a function or object to each row in the DataFrame batch in the stream. In my case insert_record , which of course just takes the record and inserts into PostgreSQL. Again, don’t copy this code as it opens connections for each row in the DataFrame and it’s just a lot of unnecessary overhead.
query = "INSERT INTO threats (threat, insert_date) VALUES (%s, %s);"
data = (record, datetime.now())
try:
cursor.execute(query, data)Here were my simple DDL statements for the tables in PostgreSQL.
CREATE TABLE threats (threat_id SERIAL, insert_date timestamp, threat varchar(30));
CREATE TABLE news (news_id SERIAL, insert_date timestamp, sentiment decimal);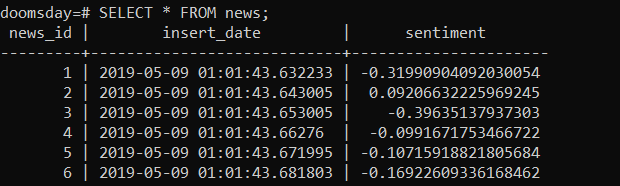
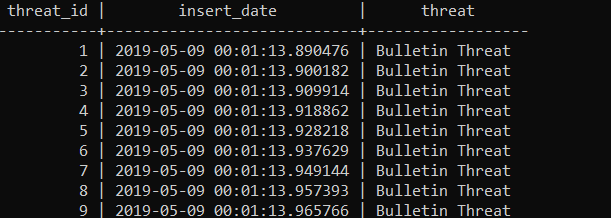
Above you can see the results of the Spark Stream that got inserted into the database. I have yet to maybe pull in some data from the financial markets, global warming index etc etc. Once I get those values into the database I should have enough to do some simple calculation to make my doomsday clock and beat the zombies. More to come in Part 2!