Airflow vs Dagster

Dagster, the first few times I read the name, I just couldn’t take the tech stack seriously …. it’s still kinda hard. Today I want to compare Airflow vs Dagster, mostly explore what Dagster is and does. But I want to compare it to the popular Apache Airflow project so people have some context for it. It’s kinda hard keeping up on all the new stuff these days, I usually just wait till I see enough articles and tweet floating around about it, then I know it’s maybe worth a peak. Let’s crack open Dagster, and see if it’s better then the name chosen for it.
All about Dagster
So Dagster seems like it’s a relative new comer to the data movement and orchestration space. I keep hearing and seeing random things about it on and off. It doesn’t seem like it’s picked up much speed, kinda hard to do with Airflow might be your competition. What is Dagster?
“…. data orchestrator for machine learning, analytics, and ETL”
dagster website
Reading the landing page on the Dagster website gives me the following insights, so off which I understand, some I don’t ….
- build pipelines in other tech (Spark, etc) (apparently you can write code in whatever, and bring it into Dagster?)
- unify view of pipelines, ML, and tables (they don’t tell you what tables, SQL? who knows)
- local development, then deploy (how’s this any different from any other tool?)
At a high level Dagster lets you define data pipelines, or data flows between solids. A Solid in Dagster is some computation, when you combine different solids you get a Pipeline.
Dagster is a Python tool pip install dagster, and a solid is just some code with a @solid decorator applied.
A Pipeline in Dagster is just another decorator that is added to a function that that holds the calls to the different solids.
Still with me? I’m not sure I’m with me, but whatever.
Does Dagster come with a UI? Why yes by Dagit.
Most data orchestrators are not of much use without a nice UI. There is something about complex pipelines that needs a UI to help people grasp what’s going on and interact. Dagster also has a UI called Dagit. pip3 install dagit
Dagster in Summary.
As far as I can tell Dagster appears to be a Python based pipeline orchestration tool, complete with a UI. At least that is my first impressions.
Reminder about Apache Airflow.
Airflow is so popular I feel like I don’t need to talk about it much. Maybe I do? I’ve written about it here and here if your new to it. Here is my few sentences about Airflow.
Airflow is a Python based tool in which you write DAGs to define data pipelines, and it comes with a UI. Airflow uses Operators (similar to the Solid concept of Dagster), and you bring together multiple Operators to define a DAG (pipeline).
Airflow vs Dagit
I don’t know if Dagster was/is supposed to compete with Apache Airflow. I mean a Python library to define data pipelines, with a UI, I’m not sure how its not supposed to be a little bit of a battle in the end. Let’s write a simple pipeline with both Dagster and Airflow just to get a general sense of what it would take to write a simple pipeline between the two.
This code and data used are available on GitHub.
Our simple Pipeline
Our pipeline we will build in both Airflow and Dagster will be simple
- read csv file, filter it.
- aggregate some metrics, write metrics.
Since both Dagster and Airflow are Python tools, and execute Python code, we can write the same computations and re-use them in both Airflow and Dagster. This makes life simpler and gives us a view into Dagster vs Airflow. On the surface they really don’t seem all that different. I’m sure there could be a feature war between them both, but in the end most people care about what it takes to actually implement a Pipeline in a tool.
Simple pipeline functions.
Here we have on function to read in some raw data and filter it, and write out results. Also we read in those results and do a simple group by with a count. We are trying to find how many bike trips happened from each station. A contrived example, but it will do.
The data looks like such.
ride_id,rideable_type,started_at,ended_at,start_station_name,start_station_id,end_station_name,end_station_id,start_lat,start_lng,end_lat,end_lng,member_casual
A847FADBBC638E45,docked_bike,2020-04-26 17:45:14,2020-04-26 18:12:03,Eckhart Park,86,Lincoln Ave & Diversey Pkwy,152,41.8964,-87.661,41.9322,-87.6586,member
5405B80E996FF60D,docked_bike,2020-04-17 17:08:54,2020-04-17 17:17:03,Drake Ave & Fullerton Ave,503,Kosciuszko Park,499,41.9244,-87.7154,41.9306,-87.7238,member
import pandas as pd
def read_filter_csv(file_location: str = 'sample_data/202004-divvy-tripdata.csv') -> None:
df = pd.read_csv(file_location)
filtered_df = df.filter(df['rideable_type'] == 'docked_bike', axis=0)
filtered_df.to_csv('sample_data/filtered_data.csv')
def calculate_metrics(data_file: str = 'sample_data/filtered_data.csv') -> None:
df = pd.read_csv(data_file)
df = df.groupby(['start_station_id']).count()
df.to_csv('metrics.csv')Ok so let’s write our Airflow Dag. We will use two different Python Operators to call our code, and >> to define the dependencies between the two.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
import pandas as pd
def read_filter_csv(file_location: str = 'sample_data/202004-divvy-tripdata.csv') -> None:
df = pd.read_csv(file_location)
filtered_df = df.filter(df['rideable_type'] == 'docked_bike', axis=0)
filtered_df.to_csv('sample_data/filtered_data.csv')
def calculate_metrics(data_file: str = 'sample_data/filtered_data.csv') -> None:
df = pd.read_csv(data_file)
df = df.groupby(['start_station_id']).count()
df.to_csv('metrics.csv')
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
with DAG('bike_trip_data',
start_date=datetime(2021, 4, 1),
max_active_runs=1,
schedule_interval=None,
default_args=default_args,
catchup=False
) as dag:
raw_csv_data = PythonOperator(
task_id='generate_file_{0}_{1}',
python_callable=read_filter_csv,
)
transform_data = PythonOperator(
task_id='generate_file_{0}_{1}',
python_callable=calculate_metrics,
)
raw_csv_data >> transform_datafrom airflow import DAG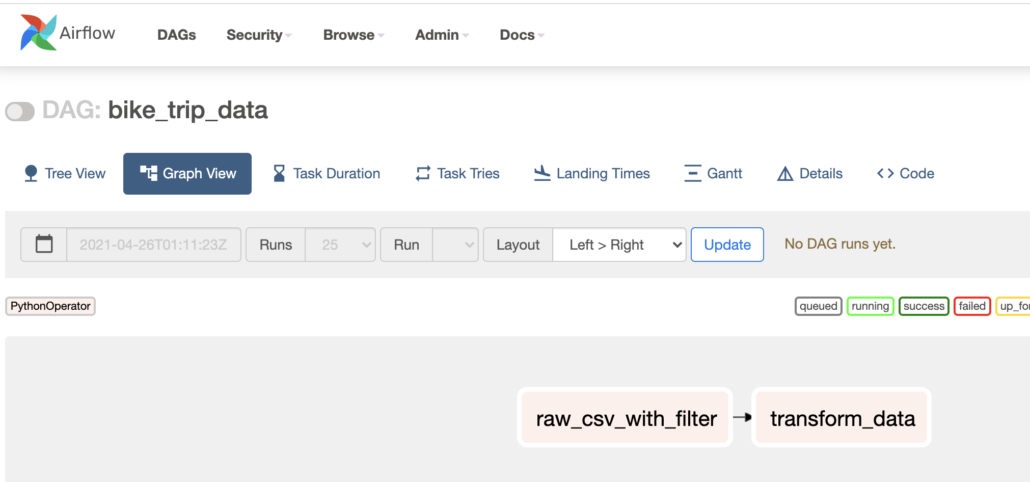
Now let’s try this with Dagster. All I’m going to do is use the same code, and apply the @solid decorator to my already written functions. Then I will write a new @pipeline function to call both those solids.
from dagster import pipeline, solid
import pandas as pd
@solid
def read_filter_csv(context, file_location) -> str:
df = pd.read_csv(file_location)
filtered_df = df.filter(df['rideable_type'] == 'docked_bike', axis=0)
filtered_df.to_csv('sample_data/filtered_data.csv')
return 'sample_data/filtered_data.csv'
@solid
def calculate_metrics(context, data_file) -> None:
df = pd.read_csv(data_file)
df = df.groupby(['start_station_id']).count()
df.to_csv('metrics.csv')
@pipeline
def first_pipeline():
f = read_filter_csv()
calculate_metrics(f)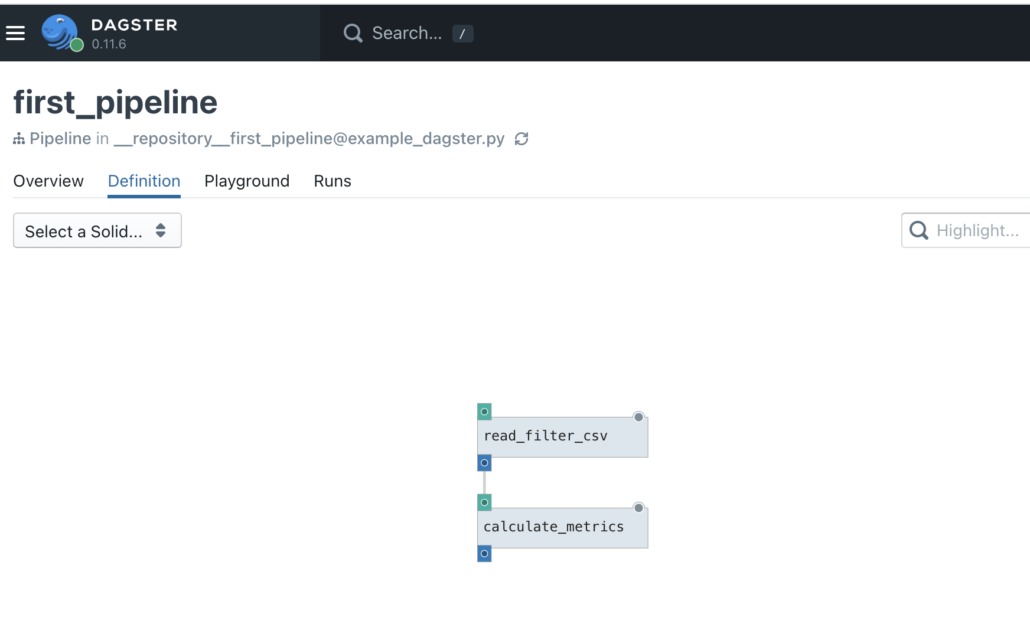
Well, gotta say, not much difference here. Nothing besides the obvious syntax anyway.
I’m sure folk on both sides of an Airflow and Dagster argument would talk up and down all day about certain features and uses that the other would have hard time doing. But, usually when someone is creative they can get a job done no matter the tool, especially when the tools are this similar.
Both of them use Python in their own ways to define a data pipeline. Both of them provide UI’s to make themselves fancy. Most of the time pipeline jobs are just a bunch of fairly common data steps and dependencies. It appears both Airflow and Dagster would easily get that job done.
Musings
From my basic perspective of pipeline orchestrator and dependency, when it comes to Airflow vs Dagster, I don’t see much difference. Obviously Airflow is the more popular and has the benefit of a massive community and every kind of third-party connector you can think of. If Dagster is really trying to get a piece of that market, maybe they will, but it’s going to take a lot.
I did appreciate the easy of just writing Python code, without a bunch of huff-a-luff and getting to the end result pipeline quickly.
I’m not sure if that makes it worth it for me, Airflow is too well known, with so much development and such a big community. I’m sure Dagster has it’s great powers, it looks fairly easy to use and has a great UI. But it will take more than that to topple Airflow.
Great article. I have a very hard time taking the name Dagster seriously too.
It feels like one difference that slipped through the cracks of your comparison might be scheduling. Clearly there is some “infrastructure” required in Airflow for declaring how often/when a DAG should start and/or run within the file itself. Meanwhile, that scheduling requirement doesn’t appear to exist in the Dagster version–at least not your example. I have to admit, the idea of decoupling the scheduling requirements from the code itself could have its advantages for a number of real world scenarios, but not nearly enough to be a “deal maker” or “deal breaker”-level feature.
Nice article.
1 thing I like about Dagster, is that you can consider a pipeline as a first class Python object. So you can do `output = my_pipeline()` in a piece of your code, and get the result back. This is useful if you have a lot of data. moving around in both pipelines and software, and don’t want to duplicate work.
Scheduling is also very easy, and automated by the Dagster daemon.