Apache Airflow for Data Engineers

On again, off again. I feel like that is the best way to describe Apache Airflow. It started out around 2014 at Airbnb and has been steadily gaining traction and usage ever since, albeit slowly. I still believe that Airflow is very underutilized in the data engineering community as a whole, most everyone has heard of it, but it’s usage seems to be sporadic at best. I’m going to talk about what makes Apache Airflow the perfect tool for any Data Engineer, and show you how you can use it to great effect while not committing to it completely.
Classic Concerns about Apache Airflow
“Airflow is a platform to programmatically author, schedule and monitor workflows.” source.
I’m sure you already have at least some idea of what Apache Airflow is. It’s a tool for writing, scheduling, and managing workflows and pipelines. When I was first introduced to Airflow as a possible tool for writing pipelines I was skeptical. Probably the same reason you might be skeptical too.
- Do I really need another “specialized” tool to solve my data problems?
- I don’t want to to commit to a technology and lock myself into something that might not fit all my needs.
- Is there enough support and documentation for when I run into trouble?
- Is it stable enough?
I can say from personal experience that all of these concerns I were unfounded and didn’t play out. For one, Airflow is all about Python, written in python and the scripts are written using Python. That can pretty much belay any fears about Airflow being too specialized or too narrow. Usually tools written in Python are flexible and have decent support.
3 Reasons Data Engineers Should use Apache Airflow
There are three reasons that every data engineer should consider using Apache Airflow for their next data pipeline project.
- Airflow makes data flow dependencies simple.
- Airflow makes data pipelines visual with zero effort.
- Airflow gives you monitoring and scheduling “free.”
These items may seem inconsequential but are integral parts of any enterprise level data pipeline system. Without a simple way to make sections code dependent, usually some home-baked design is used to chain code together. Without some visual aspect, complex pipelines become only obvious to those person(s) who wrote it and without a README with graphs, everyone becomes lost. When towards the end of a data pipeline project, someone realizes the complexity calls for monitoring and scheduling, people fall back to unambiguous cron jobs and strange monitoring and logging solutions.
Apache Airflow Dependencies…. enter the DAG.
“In Airflow, a
DAG– or a Directed Acyclic Graph – is a collection of all the tasks you want to run, organized in a way that reflects their relationships and dependencies.” – source.
Airflow DAG’s is where it is at for written data pipeline dependencies. It’s as simple as writing Python script that looks something like this.
from airflow import DAG
from airflow.operators import PythonOperator
from some.code.base import download_csv_files
from some.code.base import push_to_database
default_args = {
'start_date': datetime(2020, 1, 11),
'owner': 'Gandalf'
}
dag = DAG('dagnabit', default_args=default_args)
get_data = PythonOperator(task_id='download data',
python_callable=download_csv_files.main,
dag=dag)
push_data = PythonOperator(task_id='push data',
python_callable=push_to_database.main,
dag=dag)
get_data >> push_dataNow it really doesn’t take much thought to see what’s going on here. I have two Python modules i wrote called download_csv_files and push_to_database, both with a main( ) function I can call. There are few default DAG arguments I setup at the beginning. Then it’s a matter of setting up two PythonOperators that point to the codebase, and then simple set the dependency using >>.
Obviously this is a simple example but it shows the power of Airflow dependencies, and the simplicity of setting them up. Then you could easily see your complex pipeline in the Airflow UI.
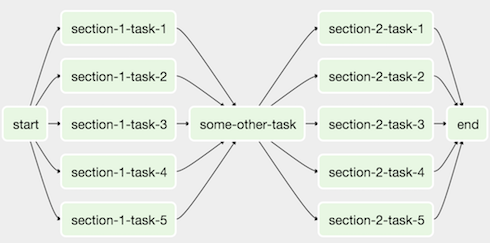
Any data engineer knows you usually have to pay money to get this kind of ETL tool. SSIS, Data Services, Talend, Informatica etc. People use those tools because of the ease of setting up complex data flows and being able to visualize and monitor large scale, complex pipelines.
Check out all of these out-of-the box Operators that Airflow provides. Seriously.
- BashOperator
- PythonOperator
- EmailOperator
- SimpleHTTPOperator
- MySQLOperator, SqliteOperator, PostgresOperator, JdbcOperator, etc.
- Sensor (watching and waiting for something to happen somewhere)
- DockerOperator
- HiveOperator
- S3FileTransformOperator
- SlackAPIOperator
- and the list goes on.
So, yes you can pretty much do anything you want with a DAG.
Visualize, Monitor, Schedule.
It’s like the three musketeers. One of the top reasons I love working with Airflow is that while I still get to write all the code, I get an awesome UI from which I can run, schedule, and monitor large complex data pipelines.
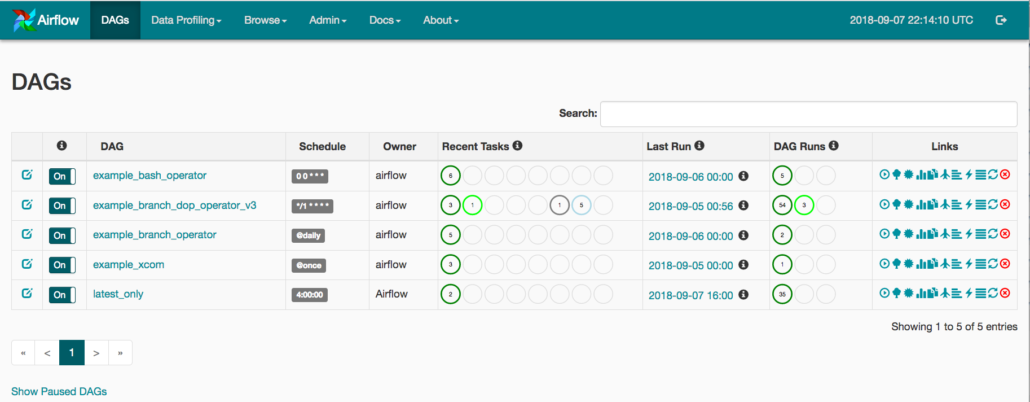
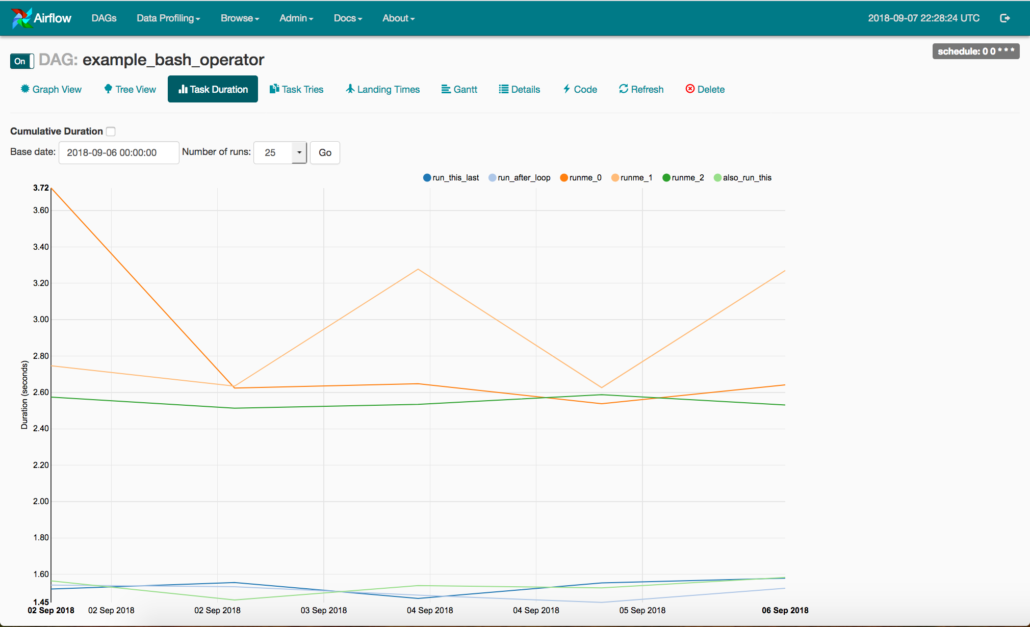
You can look at logs, inspect run times and different task duration’s, schedule runs. The Airflow UI just makes all these things easy and lets the data engineer focus on the code that is running a pipeline, instead of worrying about complex dependencies, runs, schedules, logs, and whats failing that they don’t know about.
It also opens the door for those people who may be less technical to help out. Anyone can browse to a URL and inspect a log or click run.
I hope I’ve convinced you that Airflow is the unsung hero of the data engineering world and to give it a thought next time you are designing a pipeline!
523202 843998Soon after study quite a few the websites along with your internet site now, and that i genuinely appreciate your method of blogging. I bookmarked it to my bookmark internet site list and are checking back soon. Pls have a appear at my internet page likewise and let me know in case you agree. 506370