Part 4 – Keys To Success – Idempotency and Partitioning.

As the road winds on we come to Part 4, of our 5 Part Series on Data Warehouses, Lakes, and Lake Houses. Finally, we are getting to some fun topics after all the boring stuff. Today I want to talk about the two keys to success in your Data Lakes … Idempotency and Partitioning. I firmly believe these two concepts are the cornerstones of the new exciting, or not-so-exciting world of Data Lakes and Lake Houses, without which your data and pipelines go the way of the dodo.
Part 1 – What are Data Warehouses, Data Lakes, and Lake Houses?
Part 2 – How Technology Platforms affect your Data Warehouse, Data Lake, and Lake Houses.
Part 3 – Data Modeling in Data Warehouses, Data Lakes, and Lake Houses.
Part 4 – Keys To Sucess – Idemptoency and Partitioning.
Part 5 – Serving Data from your Data Warehouse, Data Lake, or Lake House.
Why Idempotency and Partitioning, and not Keys, Constraints, Quality etc?
Some astute observer might wonder why when exploring the topics of Data Warehouses, Data Lakes, and Lake Houses I’m deciding to talk about idempotency and partitioning, and not primary keys, foreign keys, surrogate keys, constraints, data quality, and a myriad of other topics.
The reason is simple.
I’ve been really focusing on Data Lakes and Lake Houses, with file-based storage (even if it’s Delta Lake or Iceberg) and how they differ in many respects to the classic Data Warehouse that’s still worshipping at the feet of Kimball, making sacrifices of data developers souls.
“Topics like primary keys, foreign keys, surrogate keys, constraints, and dimensional modeling have been ground into the dust over and over again. These topics are well known and documented.”
– Me
Frankly, the new world of Lake Houses and Data Lakes requires a different skillset and thought process. It ain’t your grandma’s same ole’ SQL Server no more. Those days are gone.

Idempotency for Data Engineering.
What is idempotency in Data Engineering and why is it so important?
“Idempotence means that applying an operation once or applying it multiple times has the same effect. Operations that produce the same result every time.”
– Stackoverflow
Sometimes it’s easy to glazed over eyes when talking about high-level concepts like idempotent operations, I get it. What does it actually mean in the real world, and why should data pipelines be idempotent?
Data pipelines will and always will fail, data pipelines have to be run multiple times because of failures or other bugs. For various reasons, it’s extremely common for the pipelines and transformations that data engineers work on to be run and re-run. Maybe an upstream service went down, maybe some piece of business logic was wrong, the list goes on.
Idempotence is an important part of Data Engineering because the data being pumped into Data Lakes and Data Warehouses is so important, and the downstream impacts to the business that relies on the data and analytics are the real deal.
- Data reloads and re-runs have to be an option.
- Trust is hard to build around Data Lakes and Data Warehouses. If something goes wrong, it has to be fixed.
- Data Engineering is complex, transformations are complex, idemptoency makes those easier.
- Debugging and troubleshooting are a big part of Data Engineering and Data Warehouses/Lakes.
What happens if you re-run a pipeline and get a different answer each time?
- You can’t reproduce data.
- It becomes extremely hard to find problems in business logic and transformations.
- Re-runs and re-loads have to be done manually, or not at all.
Idempotency and Code.
Rather than argue with people about what true idempotency means in data operations, I would suggest a more pragmatic approach, wherein the Data Engineer starts their architecture and code design with idempotency in mind.
What is the simplest Non-Idempotent vs Idempotent data operation we can look at with a code example?
What do you see when looking at this query?
def main() -> None:
spark = SparkSession.builder.appName('Non-Idempotent').enableHiveSupport().getOrCreate()
new_records = spark.sql("""
SELECT *
FROM production.some_staging_table
WHERE CAST(transaction_time as DATE) = CAST(now() as DATE);
""")Queries like this are very common, right? I mean you’ve got a big backlog of JIRA tasks to work on, you’re working on an “easy” one to pull new data from a staging table and load them into a fact table. Simple, done, on to the next task.
Is this idempotent? Can I run this data load multiple times and get the same result? No. This is a simplistic example, but what happens when we run this a day later? We get a different result. So by definition, from the very start, this isn’t going to make the cut down the road of being an idempotent data operation.
Idempotent data pipelines are about your attitude and thinking about loading data in a repeatable manner, being able to trust that every time you run the pipeline you will get the same results, not a failure, not duplicated records, just the correct answer every time.
What would be a good first step in that direction?
def main(run_date: str) -> None:
spark = SparkSession.builder.appName('Non-Idempotent').enableHiveSupport().getOrCreate()
new_records = spark.sql(f"""
SELECT *
FROM production.some_staging_table
WHERE CAST(transaction_time as DATE) = CAST('{run_date}' as DATE);
""")Not much of a change, but it does solve some problems on the surface. Can we now trust that we will get the same answer every time we run this, over and over? Why yes we can! Passing in the run date to our pipeline, we can ensure we are able to always get the same set of records from the pipeline for the date we are trying to run, whether it’s today or some other date.
Taking Idempotency Even Further.
I know the example above was quite simple, but the point I’m trying to make is how important idempotent concepts are to Data Engineering, and it’s mostly about having a shift in mindset about developing patterns that support and lean towards idempotency as much as possible.
Maintaining Data Lakes, Lake Houses, and Data Warehouses can be a stressful experience, with bad data loads, failed loads, reloads, bad files, changing requirements. What can make you lose all your hair and look like me, is when your not only fighting these hard battles but also fighting poorly designed data pipelines that make dealing with these problems even harder.
Every aspect of loading data into your sinks should be idempotent. Let’s look at one more example. A very common task would be loading data from a staging table into a fact table, similar to the above example.
What does it mean to have the same result every run, when loading a single day’s worth of data from a staging table into a fact table?
By definition, we know we want whatever records exist fo X date in the staging table to be pushed into the fact table for X date, nothing more nothing less.
Well, that’s not that hard, is it?
MERGE INTO production.some_fact_table
USING some_staging_table
ON some_fact_table.primary_key = some_staging_table.primary_key
WHEN MATCHED THEN UPDATE SET
some_fact_table.some_column = some_staging_table.some_column, .....
WHEN NOT MATCHED THEN INSERT
(primary_key, some_column, ....)
VALUES
(some_staging_table.primary_key, some_staging_table.some_column, ...);Again, this is not rocket science. We have a staging table, some_staging_table and we are trying to MERGE into some_fact_table the records we pulled in the previous example. On the surface it seems very idempotent. If we run this twice on the same day, it would not INSERT new records, it would simply UPDATE them if they already existed in the fact table. But, it’s missing one key piece. What happens if we run this load, then find out later the client sent us the wrong file, after we had already run our load?
If we tried to just run the new file they sent us in, we would end up just doubling up the records, with bad and new.
This isn’t idempotent … idempotent in our case means we only wan’t today’s records in our staging table to be MERGED into our fact table. So we are missing one important piece in our MERGE logic, a DELETE.
We missed the the logic for records that are in the TARGET but not in the SOURCE. This adds a lot more complexity, but would make the our pipeline more idempotent.
Partitioning and its role in Data Lakes / Lake Houses.
The second key to success for the new world of Data Lakes and Lake Houses is the partitioning strategy. What is it?
“… process of physically dividing data into separate data stores.”
– Microsoft
Some might find it strange that I’m using data partitioning is a key to success for Data Lakes when there are so many other topics that we could talk about. I would argue that the best laid plans, with the best tools, wonderful data models, business requirements fleshed out, will all come to naught without good data partitions. The largest Spark cluster you can put together on EMR or Databricks won’t do you any good if your partition strategy is not good.
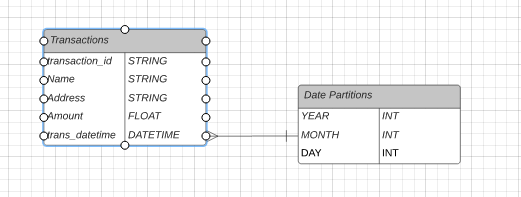
The concept of data partitions isn’t that hard to understand at all, it requires understanding two key points.
- Data access patterns.
- Data pattern on ingest.
If you think about it from a simple perspective …. let’s say you have 300 TBs of data sitting in a s3 bucket on aws. How do you find the data you need? It isn’t that hard to see that if even a very large cluster of machines had to search through all that data for some needle in the haystack, it’s going to take awhile.
This is the crux of what data partitioning provides.
The ability to more quickly find what data is needed. Many times, like in the above figure, this can take the form of some time series , like year, month, day, hour, and the list goes on. Maybe that 300TB is broken up evenly between some set of customers you have, so you partition by customer and then by date.
Data Partitioning the Obvious Way.
I would say it’s also easy to understand how data should partitioned if you understand the data even just little bit. Most likely you receive data in batches or streams, on a daily basis, so the date partition is one of the most obvious. Many business queries for data center around some sort of time series, grouping or calculating data sets of a range of days is very common.
The other pattern to look for is just to understand the data access patterns. How is this data most often used, is the data based around clients, or products, or some other value around which the business operates? May times this sort of thoughts will give insight into how data should be partitioned.
Why do Data Lakes and Lake Houses need to partitioned in the first place?
I probably should have mentioned this first, but someone who’s not familiar with Data Lakes might be asking, why do we need to partition data sets? The answer is simple, because this isn’t that age of relational databases anymore, Data Lakes, no matter the technology, (Delta, Iceberg) are really file-based storage systems.
Because of the size of the data, usually hundreds of TBs and above, along with the fact that this data is stored in files, data partitioning because an incredibly important topic.
Musings
I find it a real shame these days there is so little talk around partitioning and idempotency. I find there is a lot of technical in-depth content about particular technologies, almost too much, Spark, Kafka, Snowflake, Pulsar, blah, blah. What I’ve found, especially when interviewing more junior engineers, and even more senior folks, is that some of the basics concepts of big data and approaches to data pipelines seems to be missing.
It’s great if someone knows how to write PySpark, but that is honestly the easy part usually. If you struggle to write pipelines that are not idempotent and you fail to partition your data at all, or properly, that PySpark really isn’t going to do anyone a whole lot of good.
Back to the basics is what I say.
great bloody read! Thx for this, I wish all DEs and data specialists can read this
Great read, in desperate need of general python Data Pipeline design. Should you just worry about idempotency between the staging and target table. Or also into the initial staging table? My approach for incremental loads is normally to have a last_updated_ts and upload the difference.
It’s good to have idempotency between raw and staging tables as well. Having a last_update_ts seems to be an ok approach, although that seems heavy as the data usage grows. Many times you could partition in the incoming raw data into folders, so it is easier to understand what is new and what isn’t, or what exactly you are trying to load-reload.
Personally, I’ve used `COPY INTO` feature on Databricks to help with only loading new files, it removes a lot of the complex “only load new data” logic into the background and handles it for me.