Part 2 – How Technology Platforms affect your Data Warehouse, Data Lake, and Lake Houses.

This is a start of a 5 part series on Demystifying Data Warehouses / Data Lakes / Lake Houses. In Part 2 We are digging into the common Big Data tools and how those technologies have a direct impact on Data Models and what kind of Datastore ends up being designed.
Part 1 – What are Data Warehouses, Data Lakes, and Lake Houses?
Part 2 – How Technology Platforms affect your Data Warehouse, Data Lake, and Lake Houses.
Part 3 – Data Modeling in Data Warehouses, Data Lakes, and Lake Houses.
Part 4 – Keys To Sucess – Idemptoency and Partitioning.
Part 5 – Serving Data from your Data Warehouse, Data Lake, or Lake House.
Part 2 – How Technology Platforms affect your Data Warehouse, Data Lake, and Lake Houses.
Last time in Part 1 we talked about what exactly a Data Warehouse, Data Lake, and Lake House are. I mentioned that the technology stacks used to develop these data sinks have a very large impact on which Datastore you end up using, and which category your data model and approach to the data will fall into.
Most companies end up picking a few large Big Data tools they want to use in their stack and Data Engineering, these tools will in many cases drive the Data Model, and whether you end up with a classic Data Warehouse, Data Lake, or Lake House. Let’s dive into some of the popular Big Data tools used today and how they drive the data approach in most organizations.
Big Data Tools
This figure illustrates how I see Big Data tools and their relationship to data models. Let’s face it, the tools we use for better or worse many times lean toward and push us as Data Engineers down certain paths and data models. Whether by design or not, many data tools are “better” at some things than others, it might be because of technical implementations or limitations, they will excel at some things and fail at others.
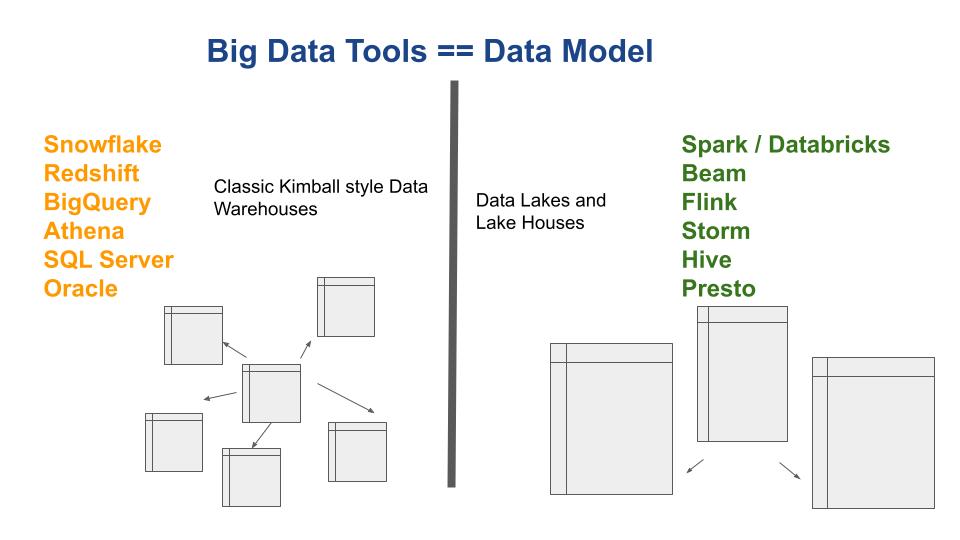
Tools Affect Data Models
SQL-centric.
Of course, this doesn’t hold true in every case, but generally, this is what I’ve seen. There are two types of tools and the drive the data model used fairly consistently. This comes back to the birth of Big Data and how companies market and who their target customers are.
On side of the fence, you have a number of very SQL-centric tools that were clearly designed to go after the classic RDBMS Data Warehouse customers. If you are an organization that has had a Data Warehouse in SQL Server, Oracle, or Postgres, there is a high likelihood that you’ve been drawn like a fly to the light towards tools like Redshift and Snowflake. They are very comfortable transitions and migrations for the most part.
They offer many of the same features and functionality as classic databases, and you interact with them in much the same way.
What does this lead to?
Data Models that are very Kimball-centric, if not exactly the same with Facts and Dimensions, with normalization, carried out to the 3rd degree. On top of this, you get the power of Big Data processing and you get to keep the Data Model you are used to working with for the last 20 years. And you can do everything with SQL, it’s less of a struggle for your engineers and developers to make this transition.
- easy transition from classic RDBMS
- SQL is the main tool
- data model doesn’t *need* to change
- power of big data processing with little hassle
Programming-Centric Tools
Again, there is can be some bleed over, but generally speaking on the other side of the aisle you have the programming-centric tools. This set of Big Data tools centers around Python, Scala, Java, and other languages.
They of course heavily support SQL, think SparkSQL, but they also branch outside that box and invest heavily in things like DataFrames, Machine Learning, and other functionality as well. It could be because of legacy, something like Hive and Spark that have been around a long time, or it could be because they are just targeting different use cases, either way, these tools are more complex and support a more complex set of use cases.
All that being said, you are less likely to see a Kimball-style classic Data Warehouse design. That isn’t to say you can’t do it, it’s just less likely. With the advent of DeltaLake and Databricks, it’s quite easy to design Fact and Dimension tables, and it’s a great tried and true Data Model. But, you’re more likely to find Data Lakes and Lake Houses with these tools. Their main focus is just to ingest and somewhat transform and cleanse the data into different Data Sinks, that are later joined for analytics by other tools or with that tool.
- hard transition from classic RDBMS
- supports more programming-centric approach
- data model will most likely skew towards Data Lake or Lake House
Review

Of course, these things are somewhat blurry and there are no hard lines, but I think you will agree that the difference between using Redshift vs Databricks is quite large. You may end up with the same end result, but getting there is will probably be different.
Why do these decisions happen like this?
- Leaders many times will choose what is familar and comfortable
- It depends who is in charge of the Data Model, different people will lean different ways based on past experiences
- You can get analytics from different Data Models
- The complexity of the data and the transfomations may drive the choice of tool and Data Model
Example
Let’s try to think of a contrived example, and how it would drive the Big Data tool selection and Data Model. We can look at it from both angles, the SQL-centric view or the programming-centric approach.
Case 1
Here is our basic overview. We have extracts that are provided daily in CSV format, there are 15 of them. These datasets are very different and require a lot of contexts which each other, customer files, address files, product files, order files, etc.
- CSV data sets
- 15 different tables
- many relationships
This would be a classic example you would probably benefit from choosing Redshift, Snowflake, something in the classic SQL-centric world. The data is tabular in format, very relational, and will most likely require very basic transformations. You really don’t need anything cancer.
Case 2
In our second example we get 3 different very large data dumps, the first in Parquet format containing transactions, the second we get a dump of Avro files for orders, and the third, we get a dump of JSON files with customer information. We are tasked with combing and transforming this data into features for a Machine Learning model.
- Parquet, Avro, and JSON
- Machine Learning required
- complex transformations
- minimal relationships
This would be a classic case for using a tool like Spark or Beam. We are getting dumps with lots of files, but not many, only 3 different types. We know we have to do some more complex transformations and use Machine Learning, and it would be nice to do it all in a single tool, to reduce overall pipeline complexity.
A tool like Apache Spark would shine in this scenario. Also, a Data Model that is more Data Lake centric, where we ingest and transform the data into 3 separate data sinks is probably more than sufficient to solve our use case.
Musings

Does it really have to be a fight? I don’t think so. I’ve been very annoyed with the fighting between Databricks and Snowflake as a recent example. There is room for both tools in this world, both are needed. I’m sure there are some customers who need to use both, or that have a hard time picking between the two … but I’m an advocate of the requirements driving the decision.
If you need to migrate a Data Warehouse from SQL Server that is very relational and ingest CSV files every day, then go for Snowflake, it’s a pretty simple choice. If you have programming-centric organizations with lots of Machine Learning and a multitude of file types with very complex transformations, then choose Databricks, it’s an obvious choice.
Data Models are very much affected by these choices of tools, and vice versa. The tools you choose will drive your Data Model to a large extent. Folks storing their data on Redshift or Snowflake are probably people with a Kimball background, and the Data Models will reflect that. The people who are using Spark and Beam are probably more comfortable with programming, and will lean towards Data Models are more Data Lakes in the sense they will just focus on cleaning the different data sets and storing them off in s3 or DeltaLake.
The joins that the Data Lake and Spark folks have to make are probably less and more obvious. Most likely data sets stored in Snowflake or Redshift might have many joins across a number of tables, and look like something you might see in a SQL Server or Postgres.
In the end you should examine your data and use case, choose the tool and the Data Model that fits your needs.