Part 3 – Data Modeling in Data Warehouses, Data Lakes, and Lake Houses.

Now we are getting to the crux of the matter. I would say Data Modeling is probably one of the most unaddressed, yet important parts of Data Warehousing, Data Lakes, and Lake Houses. It raises the most questions and concerns and is responsible for the rise and fall of many Data Engineers.
This is what really drives the difference between the”big three”, Data Modeling.
Part 1 – What are Data Warehouses, Data Lakes, and Lake Houses?
Part 2 – How Technology Platforms affect your Data Warehouse, Data Lake, and Lake Houses.
Part 3 – Data Modeling in Data Warehouses, Data Lakes, and Lake Houses.
Part 4 – Keys To Sucess – Idemptoency and Partitioning.
Part 5 – Serving Data from your Data Warehouse, Data Lake, or Lake House.
Data Modeling in the “new” world.
This is probably the biggest area of ambiguity today in the data engineering world, I see questions and confusion all around this topic. The literature and documentation have not kept up very well with the new age of Big Data and its new tech stacks like Delta Lake or Iceberg.
I see some version of this question at least once a week …
“Can I still use star schema in my data lake? Does the Kimball data model still apply? How do I model my lake house or data lake?”
– people on the internet
What is the confusion and what are people trying to articulate as the core issue?
The question centers around file based data models (think Delta Lake and Iceberg) vs relational database (Postgres, SQL Server) models.
(read my previous blog post on this topic)
Why is this so tricky?
Because in the new world of Lake Houses and Data Lakes, driven by tools like Delta Lake and Iceberg … the interface is still SQL-based, given the illusion of being no different from Postgres for example, but underneath the hood, it is quite different.
Why can’t I just use the same old data model … Kimball …?
Some people might ask the question, “Well, if they both use the same ANSI SQL interface, why does it matter, can’t I just model the same way I always have?”
Yes and No.
The problem is that between typical relational SQL databases and new Data Lakes there are two major differences …
- the backend processinge engines are completely different
- the size the data is usually completely different
So yes, sure, you don’t have to change your data model, but things probably won’t work that well … I mean you can drive your Ford Geo over the Rocky Mountains, but do you really want to do that?

Enough chit-chat, let’s dive into the specifics of data modeling for Lake Houses and Data Lakes vs Data Warehouse.
Data Modeling in Relational SQL Databases.
I won’t spend a lot of time here, this dead horse has been beaten enough over the last 20 years. But, let’s review the basics so we can in turn see the major differences between this style of data modeling and modeling in Data Lakes and Lake Houses.
For time and memorial, the Kimball and star style schema for Data Warehouses has reigned supreme and still does in many instances. It consists of the following typical points …
- Data is broken into many Facts and Dimensions.
- Data is very normalized and de-duplicated.
- Data usually fits on single database instance (we will call this a few TBs of data or less).
- Most of the data is very tabular and uniform.
- Data transformations are easy-medium difficulity level.
- Mainly for analytics, doesn’t support Machine Learning etc very well.
- Driven by primary and foreign keys.
This type of data modeling is very well known and practiced and has been in use for years.
How does this differ from Data Lakes and Lake Houses?
Data Modeling for Lake Houses and Data Lakes.
This is where things start to get a little hairy and vague. We know we need good data models for these new data stores, but we struggle to understand what model to use and most importantly … why.
What are the challenges with Data Lakes and Lake Houses and how is it different from the past?
- Hundereds of TB’s of data+
- Data comes from variety of sources, isn’t as uniform or tabular.
- Data is processed on clusters with tools like Spark, Presto, BigQuery, Athena, EMR, Redshift, blah, blah, blah.
- Data transforms tend to be more complex, medium to high difficulty.
- Supports analytics, but also Machine Learning and other outputs.
Practically for Data Engineer’s what does this mean?
Assertions about Data Models for Data Lakes and Lake Houses.
I’m going to make a few assertions about data models for Data Lakes and Lake Houses, then we will dive into each one.
- Data model isn’t as normalized, you will have less tables/data sinks.
- Data model is driven by partitions.
Data Models will have less tables and sinks in Data Lakes and Lake Houses.
One technical implementation for folks that work with Spark and other Big Data technologies have dealt with for a long time is the “small file problem.”
Many of the Big Data processing tools have hardships with data sets that are made up of many small files. There are multiple reasons for this, but what it really boils down to is that all technology behind the clusters running our compute were designed for large data sets. These tools scale well with big data … sure, they can work on data sets that are GB’s in size, but that isn’t where they shine.
Think about it, if you have 50GB of data, and you split that data into 10 different tables of 5GBs each, this means that all the transforms, tables, and queries are working on small datasets, most likely split into small files (if you’re working with data this size it means your probably ingesting files with KB’s of data, and that you don’t know about partitioning or compaction so all the files are tiny.
You think Spark will shine, and that designing a Data Lake for your small data will solve all your problems … but it won’t.
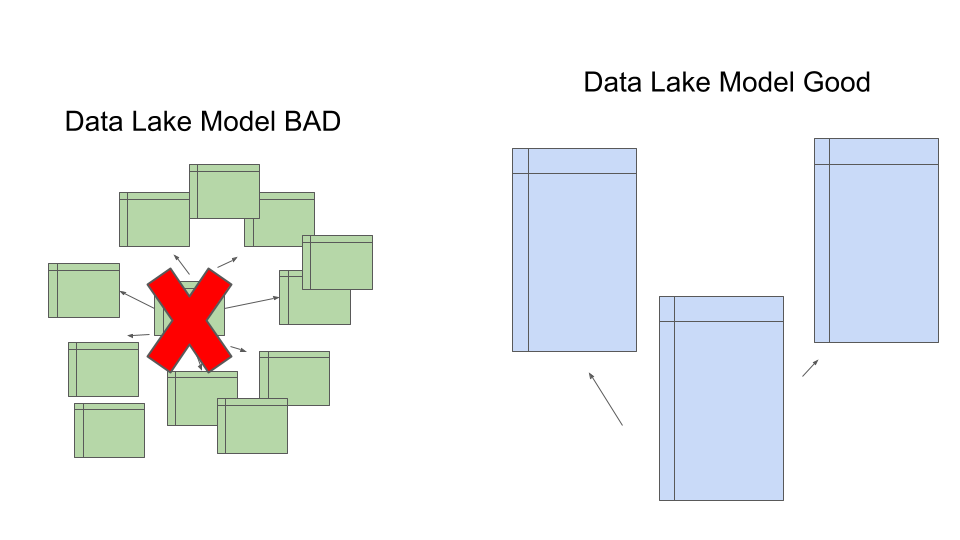
In the classic relational SQL database model, you focused on data deduplication, data normalization, and star schema to the extreme. Typically in the Data Lake and Lake House world, we would not model our file-based data sink in this manner.
We would instead focus on keeping data sources intact through our process … transforming them from raw to target ready to consume. For example … in the classic Data Warehouse world, we would most likely receive customer information with address information. We might go from a single data file to three or four tables where we commonize address information.
customer_id | customer_name | address_1 | address_2 | city | state | zip | country
123DADF645 | Billo Baggins | 123 Bag End | Hole 4 | Hobbiton | The Shire | 456 | Middle Earth
CREATE TABLE common_customer (
customer_id BIGINT,
address_key STRING,
city_key STRING,
.... etc.
)
CREATE TABLE common_address (
id_key BIGINT,
address_1 STRING,
address_2 STRING
)
CREATE TABLE common_city (
id_key BIGINT,
city STRING
)
CREATE TABLE common_state (
id_key BIGINT,
state STRING
)
.... etc, etc.You will probably not find the above type of very minute and extreme normalization and de-duplication in many Data Lakes. Never say never though.
Data Lakes and Houses will contain Accumulators and Descriptors, not nessesiarly Facts and Dimensions.
The only reason I don’t like to call Fact tables Fact tables in Data Lakes, and Dimensions as Dimensions, is because of the historical context around Fact and Dimensions and all that entails. It gives a certain impression about the Data Model under discussion, and I like to make distinctions.
Accumulators
Accumulators in a Data Lake aggregate or accumulate the transactional records, pretty much like a Fact table would have in the past. The main difference will be that the Accumulator table will probably contain fewer “keys” that point to other tables, that would most likely have been stripped out and put into a Dimension table in the classic SQL Kimball model.
CREATE TABLE transaction_accumulator (
transaction_id BIGINT,
transaction_description STRING,
amount FLOAT,
product_id INT,
product_description STRING,
product_category INT,
customer_id INT,
customer_name STRING,
customer_address_1 STRING,
.. etc , etc.
)The Accumulator above is similar to a Fact table but isn’t stripped of all its descriptors with that data being normalized out into a myriad of other tables.
Descriptors
The Descriptors in the new Data Lake or Lake House are exactly like Dimensions, again they are just less broken up and normalized, there are just fewer of them. If the business requires say some distinct list of addresses, that would just be done an additional sub table probably run and filled much like a Data Mart or analytic further downstream. It wouldn’t be built into the Descriptor Tables and given keys that are referenced in an Accumulator table.
Data Partitions drive the data model.
Data partitioning is an interesting topic, with lots of tentacles, I suggest reading this Microsoft doc to get the background. This isn’t a topic often talked about in Data Engineering, because it isn’t sexy, but this topic is core to driving data models for Data Lakes and Data Warehouses.
When you work with SQL relational databases, everything you do is driven off of primary and foreign keys, and indexes. Many times these concepts only exist very “loosely” in a Data Lake or Lake House, and are implemented in the code, not part of the product (Delta Lake for example). If you want these concepts, you create them and enforce them yourself.
Big Data can only be handled with Partitions.
Big Data sources and sinks have to be broken up into pieces, or semi-logical business or query units. It really breaks down into the following problem …
How can I find what I need in this 200TB dataset? I can’t very well read every single file to get what I need, it would take too long.
Enter Partitions. And if partitions are this important and core to working on Big Data, then that becomes the core of the data model used. The tables and sinks that are designed are designed around these partitions, to make the data accessible and usable by the downstream compute.
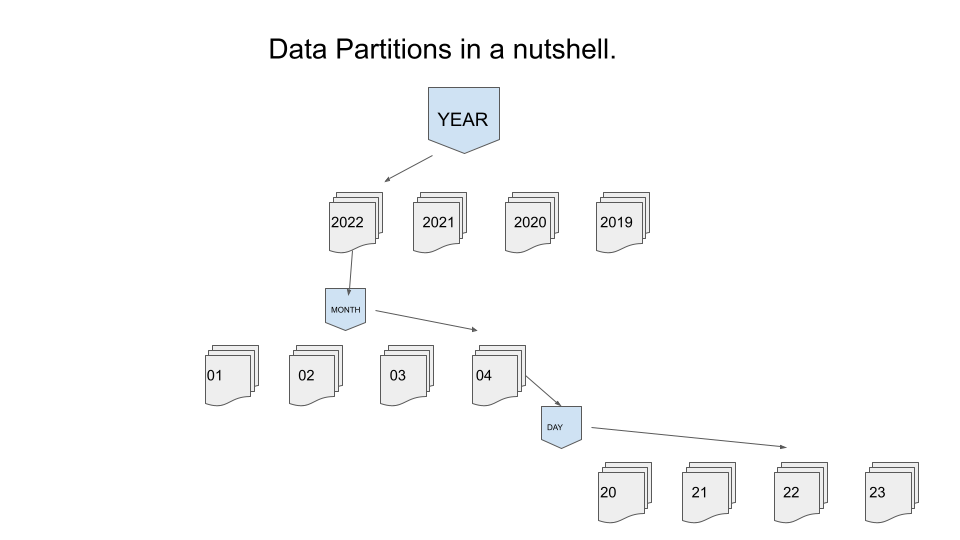
The compute somehow needs a way to find the files that contain the data needed, without reading everything, it uses partitions as that path to find the needed data. These partitions would be data points inside your data that would distribute the data for each partition fairly evenly. A common one would be many “customer”, or year, month, day if time series apply to your dataset.
So your Data Lake and Lake House tables and data model will be designed around these partitions. For a simple example …
CREATE TABLE transaction_accumulator (
transaction_id BIGINT,
transaction_description STRING,
transaction_date TIMESTAMP,
amount FLOAT,
product_id INT,
product_description STRING,
product_category INT,
customer_id INT,
customer_name STRING,
customer_address_1 STRING
)
USING DELTA
PARTITIONED BY (year, month, day);In summary, big data sets cannot be queried without a good partitions strategy, hence they drive the data model, in Data Lakes we design larger tables that are less normalized, we keep source files together, and instead of breaking them up into many small tables.
Musings
I really only scratched the surface here. Data models are complex and depend vastly on the business requirements and needs of the business. It’s been clear for a while that the classic Kimball and star schemas with data in the third normal form start to break down in the Data Lake and Data Lakehouse world.
These very normalized and distributed classic star schema Data Warehouse designs were made for relational SQL databases, with those systems in mind, relying heavily on primary and foreign keys, concepts that aren’t as solid when your using Spark and Delta Lake or just files on s3 for example. This creates all sorts of headaches.
The Kimball-style Data Warehouse has survived and still thrives because it’s bulletproof, tried, and true method of warehousing data for the last 20 years. It has many features that we need to keep control of our data sets.
I have found in my data journeys there is rarely a perfect answer for every case, I find it clear that data models must evolve to meet the needs of the new world of Spark and Delta Lake with hundreds of TBs of data. Yet I find myself needing and wishing for many of the old features and models that were “easy” in the classic data warehouse.
How do we find the middle ground?