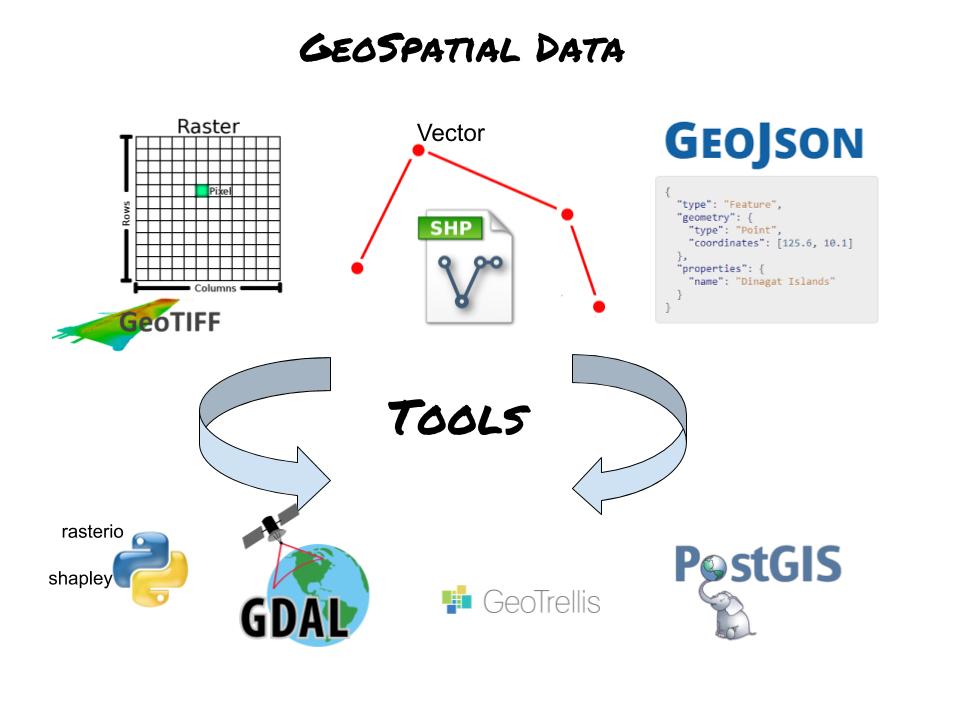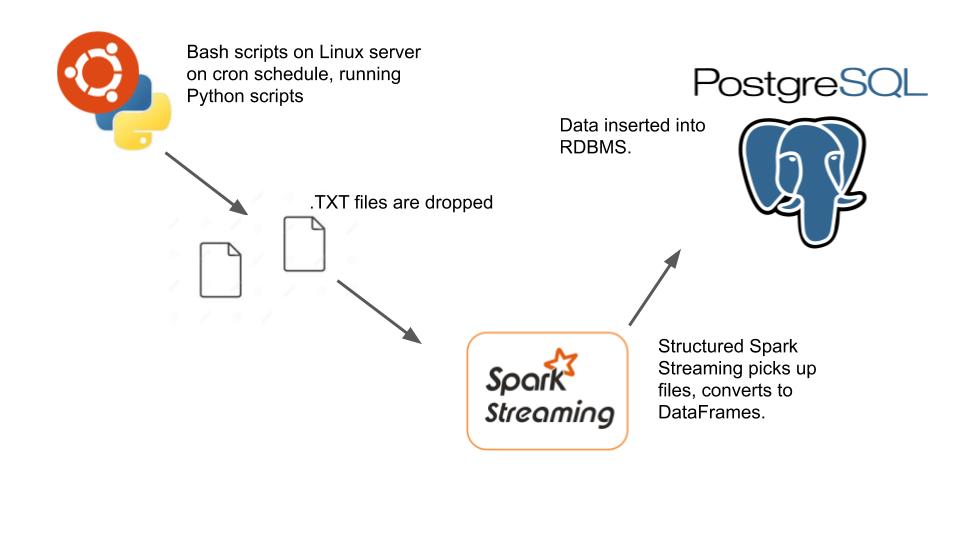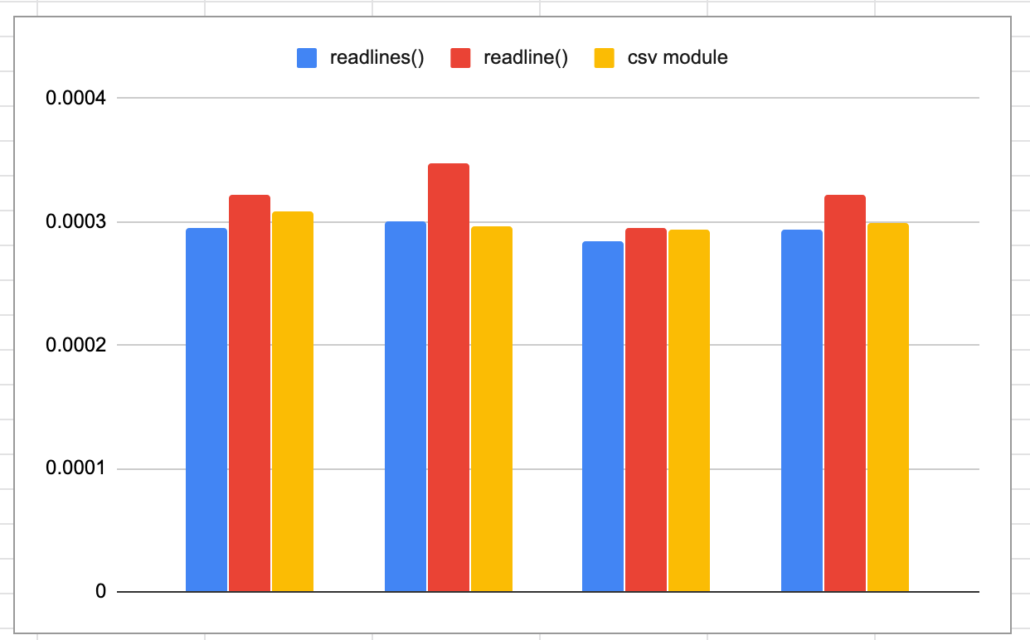
Ah. What a classic. The one piece of code that I end up writing over and over again, you would think I would have stashed it away by now. Not going to lie I usually have to Google it, while thinking, is this the right way? Should I just open the csv file and iterate it? Should I import the csv module? Should I just use Pandas? Does it matter? Probably not.
Read more