Concurrency in Python Data Pipelines – Async, Threads, Processes … Oh My.

Concurrency in Python is like the awkward group of middleschool boys gathered in the corner of the dance floor all pointing to the girls in the other corner. Everyone talks a big game, pretending like they totally understand the other group and could easily handle the pickup if they wanted to. Mmmhmmm.
When push comes to shove and you actually have to pick the girl to take to the dance floor, it all the sudden becomes this wierd and strange shuffle of interactions that sometimes works out, and sometimes doesn’t. That is Python concurrency in data pipelines for most folk.
I’m really not that concerned with the most perfect explanation of Async, Threads, and Processes, if you care about that I would suggest you go troll around stackoverflow to find some poor soul you can unleash your brilliant mind on. Let’s talk concurrency. The idea is enticing in data pipelines. We process data, what could be better than processing more data, more quickly, and impress people while we are at it?
True concurrency would be running “parts” of a “program” at the same time, concurrently. The idea is kind of loose in Python, considering the GIL. I understand some C packages like numpy can release it, but in general I just treat it as a rule of thumb. I can’t learn every single third party package and which methods would release the GIL. I always keep this in mind when writing data pipelines. Let’s start with the basics.
Here’s how I catalog things in my mind. I have three options.
import concurrent.futures.ThreadPoolExecutor
import concurrent.futures.ProcessPoolExecutor
import AsyncioThat’s it, so I can mix and match the three, us none, use one, maybe two. So the next question is which for what? I put threading and async in one bucket with processes in another. These are loose explanations and should be held lightly because they might push you to not think outside the box. One track minds are never helpful.
Threading/async should be used when your program has spots that sit around and wait. Like making an HTTP call and waiting for the response, a database call, etc. Its usually called IO, input/output. Think of it like letting your code do something else while another piece is waiting for an outside force to respond or react. Waiting on something you can’t control is a sure way to slow things down for no reason.
Separate Python processes on the other hand are typically used to solve more CPU bound problems. Calculating or transforming data for example. If you have a bunch of data you need to apply the same transformation, obviously the more CPUs doing that the better.
The pitfall I’ve seen in the implementation of concurrency in Python data pipelines is twofold. Either the wrong type is chosen or a type is chosen for the whole pipeline when not every part of the pipeline fits that model. A little hint, I’ve rarely run across a data pipeline that would not benefit from both threading/async and processes. The trick is the size and amount of data typically. Is there enough data to make the overhead of uses processes worth it?
Let’s look at a concrete example. What we are looking at is downloading a bunch of text files, books written by Martin Luther, from Project Gutenberg, through a FTP mirror, open up the files and remove the references to Project Gutenburg, which is acceptable if you don’t want to have to reference them in the distribution of the files. The complete code can be found on GitHub.
import aiohttp
import asyncio
import csv
import os
from ftplib import FTP
from ftplib import error_perm
import glob
import time
class Gutenberg():
def __init__(self):
self.request_url = ''
self.csv_file_path = 'ingest_file/Gutenberg_files.csv'
self.csv_data = []
self.cwd = os.getcwd()
self.ftp_uri = 'aleph.gutenberg.org'
self.ftp_object = None
self.download_uris = []
self.file_download_locattion = 'downloads/'
def load_csv_file(self):
absolute_path = self.cwd
file = self.csv_file_path
with open(f'{absolute_path}/{file}', 'r') as file:
data = csv.reader(file, delimiter=',')
next(data, None)
for row in data:
self.csv_data.append({"author": row[0],
"FileNumber": row[1],
"Title": row[2]})
def iterate_csv_file(self):
for row in self.csv_data:
yield row
def ftp_login(self):
self.ftp_object = FTP(self.ftp_uri)
self.ftp_object.login()
print('logged into gutenberg ftp mirror')
@staticmethod
def obtain_directory_location(file_number: str):
"""Files are structured into directories by splitting each number, up UNTIL the last number. Then a folder
named with the file number. So if a file number is 418, it is located at 4/1/418.
Below 10 is just 0/filenumber."""
file_location = ''
for char in file_number[:-1]:
file_location = file_location+char+'/'
return file_location+file_number
def iterate_directory(self, file_location: str) -> iter:
try:
file_list = self.ftp_object.nlst(file_location)
yield file_list
except error_perm as e:
print(f'Failed to change directory into {file_location} with error ...{e}')
exit(1)
@staticmethod
def find_text_file(files: iter, row: dict) -> object:
for file in files:
if row["FileNumber"]+'.txt' in file:
print('file name is {file}'.format(file=row['FileNumber']))
return file
elif row["FileNumber"]+'-0.txt' in file:
print('file name is {file}'.format(file=row['FileNumber']))
return file
elif '.txt' in file:
print('file name is {file}'.format(file=row['FileNumber']))
return file
print(f'No file found for {row}')
def download_file(self, file, filename):
try:
with open('downloads/'+filename+'.txt', 'wb') as out_file:
self.ftp_object.retrbinary('RETR %s' % file, out_file.write)
except error_perm as e:
print(f'failed to download {filename} located at {file} with error {e}')
@staticmethod
def iter_lines(open_file: object, write_file: object) -> None:
lines = open_file.readlines()
start = False
end = False
for line in lines:
if 'START OF THIS PROJECT' in line:
start = True
if 'End of Project' in line:
end = True
elif end:
break
elif start:
if 'START OF THIS PROJECT' in line:
continue
write_file.write(line + '\n')
@property
def iter_files(self):
for file in glob.glob(self.file_download_locattion+'*.txt'):
with open(file.replace('.txt','-mod.txt'), 'w', encoding='utf-8') as write_file:
with open(file, 'r', encoding='ISO-8859-1') as open_file:
self.iter_lines(open_file, write_file)
def main():
t0 = time.time()
ingest = Gutenberg()
ingest.load_csv_file()
rows = ingest.iterate_csv_file()
ingest.ftp_login()
for row in rows:
file_location = ingest.obtain_directory_location(row["FileNumber"])
file_list = ingest.iterate_directory(file_location)
for file in file_list:
ftp_download_path = ingest.find_text_file(file, row)
ingest.download_file(ftp_download_path, row["FileNumber"])
ingest.iter_files
t1 = time.time()
print(t1-t0)
if __name__ == '__main__':
main()This little beauty runs in about 18 seconds. A little slow for the small number of files (13). Now I find this quite amazing. When you look at the code, you would assume all the code working and iterating through the lines of the text files, checking if statements etc would be where bottleneck is. Not at all! 17.5 seconds were spend waiting on network IO, calling the FTP folders to list the files and downloading them. Crazy. This just goes to show the importance of understanding what is actually blocking the code, and where to focus efforts.
So now we know the issue is IO, we have two options to solve this problem, Async or Threading. Let’s give aioftp a try. The idea here would be to use our new found knowledge that making all the calls to the FTP server is chewing up all the run time. If we could await each call to the FTP server and hand control over to another thread to continue on down the line instead of waiting for that call to finish, we could probably squeeze some speed out! Here goes nothing.
import aioftp
import asyncio
import csv
import os
from ftplib import error_perm
import glob
import time
class Gutenberg():
def __init__(self):
self.request_url = ''
self.csv_file_path = 'ingest_file/Gutenberg_files.csv'
self.csv_data = []
self.cwd = os.getcwd()
self.ftp_uri = 'aleph.gutenberg.org'
self.ftp_object = None
self.download_uris = []
self.file_download_locattion = 'downloads/'
def load_csv_file(self):
absolute_path = self.cwd
file = self.csv_file_path
with open(f'{absolute_path}/{file}', 'r') as file:
data = csv.reader(file, delimiter=',')
next(data, None)
for row in data:
self.csv_data.append({"author": row[0],
"FileNumber": row[1],
"Title": row[2]})
def iterate_csv_file(self):
for row in self.csv_data:
yield row
def ftp_login(self):
self.ftp_object = aioftp.Client()
self.ftp_object.connect(self.ftp_uri)
self.ftp_object.login()
print('logged into gutenberg ftp mirror')
@staticmethod
def obtain_directory_location(file_number: str):
"""Files are structured into directories by splitting each number, up UNTIL the last number. Then a folder
named with the file number. So if a file number is 418, it is located at 4/1/418.
Below 10 is just 0/filenumber."""
file_location = ''
for char in file_number[:-1]:
file_location = file_location+char+'/'
return file_location+file_number
@staticmethod
def find_text_file(file: object, row: dict) -> object:
if row["FileNumber"]+'.txt' in file:
return file
elif row["FileNumber"]+'-0.txt' in file:
return file
elif '.txt' in file:
return file
@staticmethod
def iter_lines(open_file: object, write_file: object) -> None:
lines = open_file.readlines()
start = False
end = False
for line in lines:
if 'START OF THIS PROJECT' in line:
start = True
if 'End of Project' in line:
end = True
elif end:
break
elif start:
if 'START OF THIS PROJECT' in line:
continue
write_file.write(line + '\n')
@property
def iter_files(self):
for file in glob.glob(self.file_download_locattion+'*.txt'):
with open(file.replace('.txt','-mod.txt'), 'w', encoding='utf-8') as write_file:
with open(file, 'r', encoding='ISO-8859-1') as open_file:
self.iter_lines(open_file, write_file)
async def download_file(gutenberg, file: str, filename: str) -> None:
async with aioftp.ClientSession(gutenberg.ftp_uri) as client:
try:
await client.download(file, 'downloads/'+filename+'.txt', write_into=True)
except error_perm as e:
print(f'failed to download {filename} located at {file} with error {e}')
async def run(gutenberg):
files = []
rows = gutenberg.iterate_csv_file()
for row in rows:
file_location = gutenberg.obtain_directory_location(row["FileNumber"])
files.append(file_location)
async with aioftp.ClientSession(gutenberg.ftp_uri) as client:
tasks = []
for file_to_download in files:
for path, info in (await client.list(file_to_download, raw_command='LIST')):
text_file = gutenberg.find_text_file(str(path), row)
if text_file:
print(file_to_download)
file_name = file_to_download[file_to_download.rfind('/')+1:]
task = asyncio.ensure_future(download_file(gutenberg, text_file, file_name))
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
def main():
t0 = time.time()
ingest = Gutenberg()
ingest.load_csv_file()
t3 = time.time()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(run(ingest))
results = loop.run_until_complete(future)
t4 = time.time()
ingest.iter_files
t1 = time.time()
total = t1-t0
downloadtime = t4-t3
print(f'total time {total}')
print(f'download time {downloadtime}')
if __name__ == '__main__':
main()
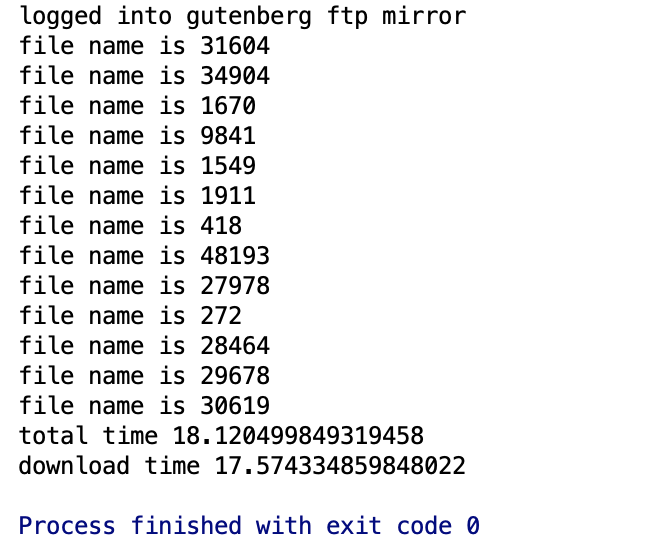
The code is all the same, except for two new async functions. Well, look at that! Cutting the program time down in half is not too shabby! My goal isn’t to teach async, go read about that yourself, it was just to show you that understanding what is blocking in your code, and choosing the right solution to add concurrency doesn’t take that much effort, and has huge payoffs. Learning something new always takes time and some frustration, but it’s worth the price.
Cool explanation of how to make data in Python more efficient! I’m looking forward to implementing some of these techniques on my next project.