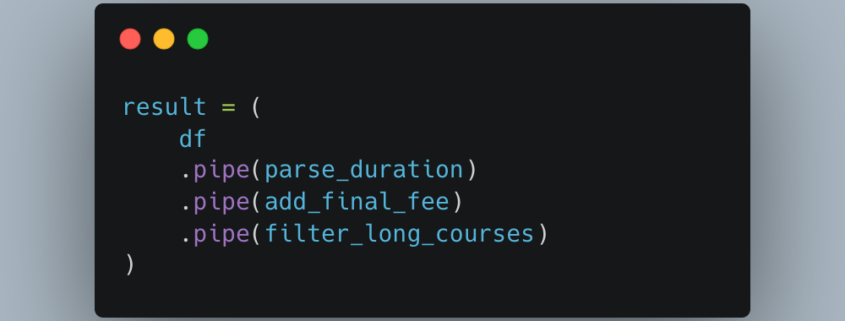
It seems we have several cadres of people when it comes to “clean code.” I know there is a lot of previous baggage that comes with that nomenclature, good and bad. But, I think we can think about “clean code” from a simplistic point of view. It doesn’t have to be that complex.
We live in the Age of AI, in relation to the generation of code, of products, features … the software developer’s role has shifted. We can argue how it’s shifted, but it has.
If the generation of most of the mundane and everyday code is given to our AI peons like Cursor and Claude, then what value can you bring to the table?
You can bring a sense of good architecture from a systems perspective and from a “these modules of code” perspective. This data pipeline. Sure, some places, businesses just want you to churn out bits and bytes as fast as those tokens will let you, I feel bad for you. Many places still recognize the business context and keep the product running well … leading to happy customers who give us money … is extremely important.
There is an argument to be made that you should ensure you, or your AI, is producing clean code.
Read more