


So you’re thinking about moving to Databricks. Maybe you’re frustrated with your current stack. Maybe leadership wants “AI readiness.” Maybe you’re just tired of duct-taped pipelines and brittle warehouses. Databricks is powerful. It is not magic.
Before you migrate, you need clarity. Not excitement. Not feature envy. Clarity. This guide walks through how to approach adoption or migration with discipline, not hype.

Every few years, Spark reinvents itself. First, it was Scala and RDDs. Then DataFrames. Then Python took over. Now we’re entering the era of declarative pipelines. You can complain about abstraction if you want. There’s always a small but passionate group that mourns the loss of some lower-level construct. They cling tightly to bespoke implementations and handcrafted orchestration logic as if it were sacred scripture.
But abstraction is the story of software. It always has been. I mean, look at SQL. It always comes back to win the game in the end, no matter how mad all the hardcore programmers get.
And Spark Declarative Pipelines (SDP), branded as Lakeflow Declarative Pipelines on Databricks, aren’t random. They are a response to how Spark is actually being used in the real world, making it approachable for the average Data Engineer. RDDs were not approachable for everyone.
If you don’t make things approachable, you lose your customer and user base.

It’s an interesting time to be in software and data; the world of generative AI is changing the landscape beneath our feet. I don’t see this as a bad thing for software folk, but as an opportunity to learn new technologies and BUILD / UNDERSTAND the technologies used in an LLM and AI context.
You can’t expect an LLM trained two years ago to be up-to-date on what the new and best approaches are for X, Y, Z tech.
Sure, they can do a decent job given enough context, Agents, etc, but if you’re working on the cutting edge of AI and LLM infrastructure, you are going to have to be active in the community and reading about what others are doing, who’s releasing new tools, and what those tools do.
Don’t forget, there is the whole architectural and systems design piece. One part of the LLM and AI infrastructure is vector and embedding representations.
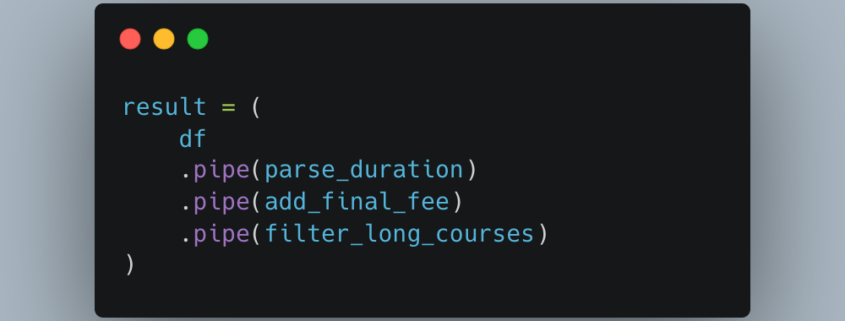
It seems we have several cadres of people when it comes to “clean code.” I know there is a lot of previous baggage that comes with that nomenclature, good and bad. But, I think we can think about “clean code” from a simplistic point of view. It doesn’t have to be that complex.
We live in the Age of AI, in relation to the generation of code, of products, features … the software developer’s role has shifted. We can argue how it’s shifted, but it has.
If the generation of most of the mundane and everyday code is given to our AI peons like Cursor and Claude, then what value can you bring to the table?
You can bring a sense of good architecture from a systems perspective and from a “these modules of code” perspective. This data pipeline. Sure, some places, businesses just want you to churn out bits and bytes as fast as those tokens will let you, I feel bad for you. Many places still recognize the business context and keep the product running well … leading to happy customers who give us money … is extremely important.
There is an argument to be made that you should ensure you, or your AI, is producing clean code.
I’ve been a Polars bro for most of the last few years. Why? It’s Rust-based, fast, DataFrame-centric, just the way I like it. It also had the excellent feature, right from the start, of Lazy Execution. A few years ago, maybe two, I actually put Polars into production, running on Airflow, working with S3 and reading Delta Lake tables.
I was in love.
Over the last few years, I’ve found myself using PyArrow more and more for everyday data engineering things. Data ingestion, reading, and writing from various data sources and sinks. Most of us are familiar with Arrow and how it underpins a lot of new tech like DataFusion, and Arrow is used as an internal memory format.
But, small and mighty though it might be, the pyarrow Python package is a force to be reckoned with. Capable of blasting through all sorts of cloud-based datasets. It’s not particularly a data transformation framework, as much as a way to represent core datasets, transferring data hither and thither over the wire from one format to another.

Something I’ve taken for granted for a long time, and then suddenly discover others are discovering for the first time, leaves me a little baffled. It makes me wonder how many folks are living under a proverbial rock. Recently, I saw a post on that infamous LinkedIn about someone excited about Polars’ lazy execution.
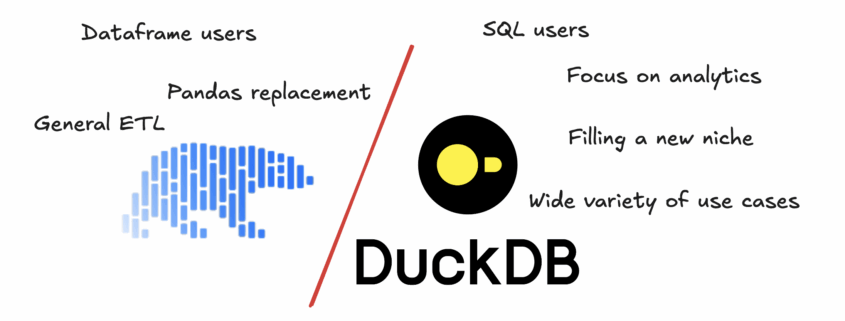

So, the classic newbie question. DuckDB vs Polars, which one should you pick?
This is an interesting question, and actually drives a lot of search traffic to this website on which you find yourself wasting time. I thank you for that.
This is probably the most classic type of question that all developers eventually ask at some point in their sad and depressing lives. Isn’t that the same story that is as old as time? This stick is better than that rock. Rust is better than C. Databricks better than Snowflake. You know, Delta Lake better than Iceberg.
And so the world keeps turning and grinding away.