
DuckDB + Delta Lake (the new lake house?)
I always leave it to my dear readers and followers to give me pokes in the right direction. Nothing like the teaming masses to set you straight. Recently I was working on my Substack Newsletter, on the topic of Polars + Delta Lake, reading remove files from s3 … I left a question open on my LinkedIn account.
I had someone jog my leaky memory in favor of DuckDB. I haven’t touched DuckDB in some time, and I’m sure it’s under heavy development what with that Mother Duck and all.
So, it’s time to talk about DuckDB + Delta Lake.
The Duck … Cometh
Why? Because it’s real. For all the Hufflepuff people spill, I enjoy trying things for real. No local storage, like data actually stored in s3 in the cloud. That’s real because that’s what people actually do.
What makes DuckDB even more interesting in the context of Delta Lake is the new Spark API compatibility they released. This seems to be an underrated feature to me and a direct shot across the bow of Databricks.
“DuckDB’s Python client offers a Spark-compatible API. The API aims to be fully compatible with the PySpark API, allowing you to use the familiar Spark API. All statements are translated to DuckDB’s internal plans using our relational API and executed using DuckDB’s query engine.” – DuckDB
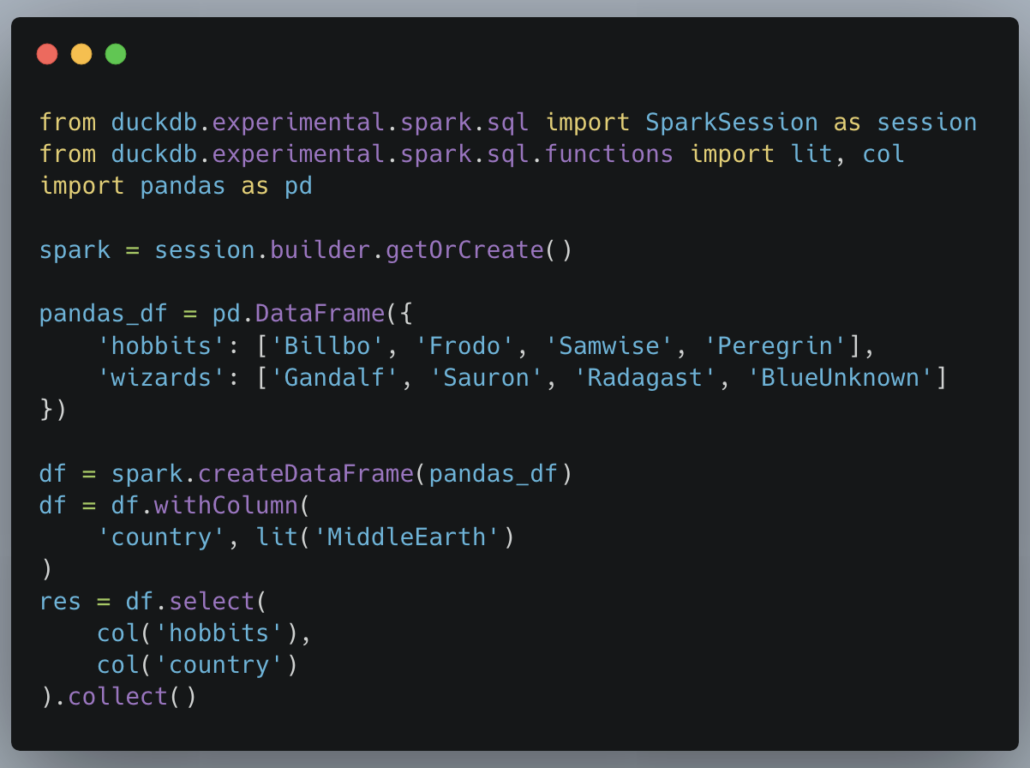
Why is this such a big deal? Well, we’ve known for some time now that DuckDB is the fastest thing around these here parts. It’s also all SQL, so basically anyone can use it. It also can be pip installed. Seriously. But with all these rainbows and unicorns it makes me ask a question.
What’s been keeping people away from DuckDB in production?
DuckDB is currently designed, for now, as an in-process single-node engine. In one word scalability. People worry and think about scalability. Even if they don’t need it.
But DuckDB has an answer for all the Spark and Databricks enthusiasts like myself. And it’s called … you addicted … cut yourself off. And they are trying to make it easy and tempting … PySpark API compatibility!
The Cost Cometh.
What does it all boil down to?
“DuckDB is correctly recongizing the high costs associated with Databricks and Snowflake type products. They also rightly recongizinze many companies have lots of datasets that do not require Spark. – me
This is all very try and hard to argue with. SQL is everywhere, and DuckDB is easy to run and install. It has support for the cutting technology we all love like Delta Lake and Spark, they are trying to make it so easy to include DuckDB in your architecture that it’s almost a crime if you don’t.
But what’s the reality of the situation?
The problem is that people are busy, data teams are busy. People are sorta burned out with the Modern Data Stack as well, tool burnout if you want to call it that. We start to get eyes that are glazed over when we hear about another tool that is going to save our lives and pocketbooks.
Also, it’s about the simplicity of architecture. Like it or not, most good Data Platform teams try to minimize the number of tools they use in their pipelines. It narrows the focus, reduces pain and brain points, and is easier to debug and work on.
Sure, we might have some data that doesn’t need Spark or Databricks … but for the sake of simplicity and architecture … we simply run it all on Databricks. Why not. We have the money, we don’t have the time, we like things simple. So off down the yellow Brick road we go with no thoughts of turning right.
“But eventually the Cost Man Cometh. At some point cost becomes a factor and cooler heads prevail.”
We could all probably do with a little cost savings, a little DuckDB + Delta Lake. Why not? How hard could it be?
Reading Delta Lake with DuckDB.
So, how easily can we bring DuckDB to our Lake Houses or Data Lakes … say stored somewhere in s3? Pretty easy when looking at this code.
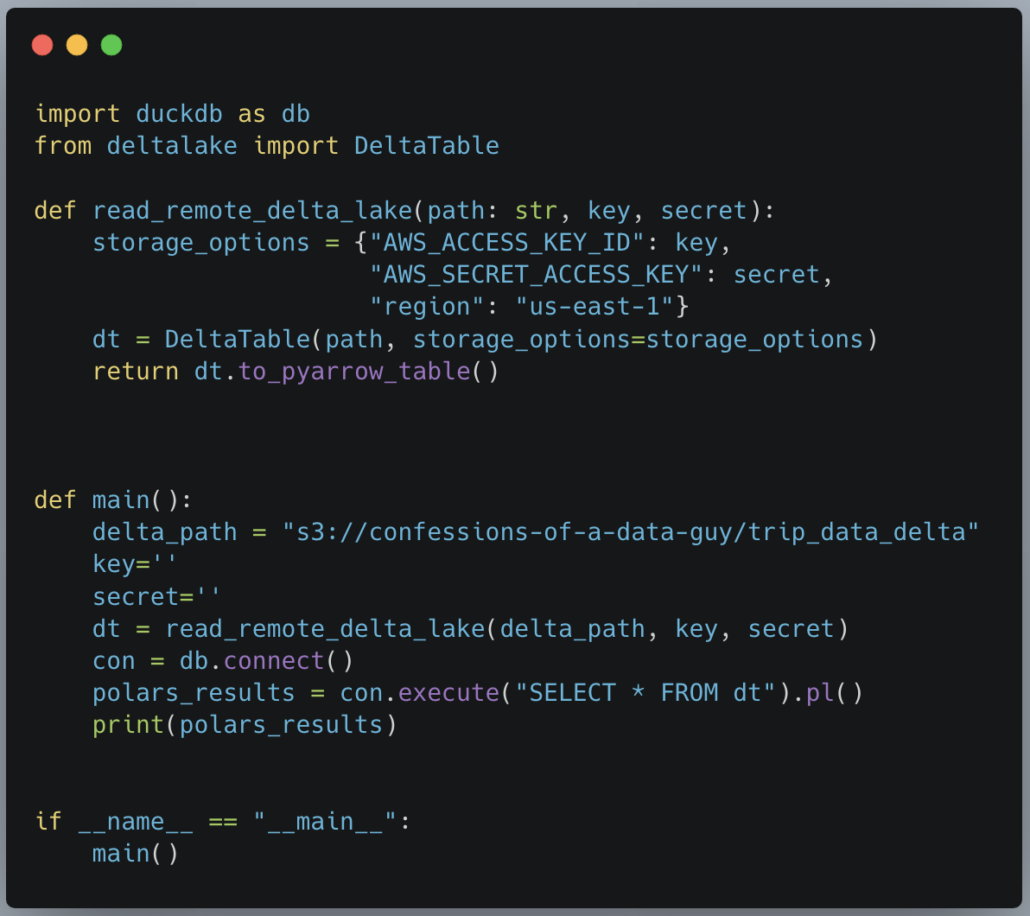
It works like a charm.
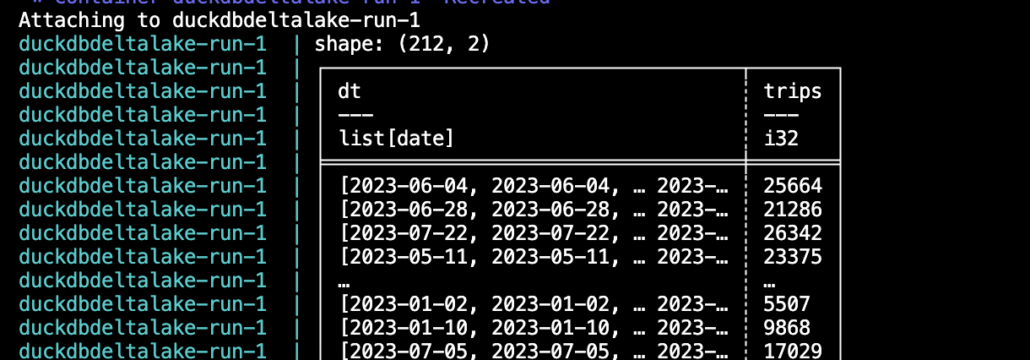
All the code is available on GitHub. One thing you will notice is all the Python packages required to make this work. It ain’t nothing. What is happening is that we are reading with deltalake , converting to pyarrow then using DuckDB to run our SQL, then converting back to polars to inspect the results.
Look at all the tools we need. Again … we have to read the Delta Table with deltalake then export it to pyarrow Table, at which point we can do our thing with duckdb. I also added Polars so I could print it nicely for debugging … as a Dataframe, and you will want to do that in real life, with Pandas or Polars, so that’s the last package needed.
The question I ask myself is …
“If I can use Polars + PyArrow to read Delta Lake and run SQL on data … do I really need DuckDB for the millisecond speedups that are faster then Polars? Not sure, probably not?
There is serious potential here.
Maybe it’s marketing, who knows? I’ve seen a lot of traffic about Polars, seems like Data Engineering folks are really starting to use it in a Data Engineering context. I myself have brought Polars into my work’s production environment, running on Airflow Workers and reading Delta Tables!
We see the potential for replacing some Spark workloads with Polars, it’s a no-brainer. But DuckDB? Not sure yet where that one will fall. Maybe if I wasn’t such a Dataframe API fan etc. I would have opted for DuckDB … not sure.
Again, many companies are married to SQL as much as possible. DuckDB has some serious potential to reduce costs by computing on data that will fit on a single node. People are crazy if they don’t at least explore the option of having some of these new tools like Polars or DuckDB take over some workloads.
Compute is money. DuckDB can absolutely replace some Snowflake or Databricks processing.
