
SparkSQL is Destroying your Pipelines
It’s true, even if you don’t want it to be. SparkSQL is destroying your data pipelines and possibly wreaking havoc on your entire data team, infrastructure, and life. In your heart of hearts, you’ve probably known it for years. With great power comes great responsibility. We all know that even us Data Engineers are human and fallible.
Once those tentacles of SparkSQL get their hold on you, the probability of survival is low. Sure, there are a few wizened old engineers with enough battle scars to make it through unscathed. The rest of us will be maimed.
SparkSQL is Destroying your Pipelines
It’s a pretty bold statement, isn’t it? Before you sharpen your axe and take off to the chopping block, hear my last plea and cry. Stop using SparkSQL so much.
Why?
Well, let me spin you a story, weave you a tale of days far gone, back when SQL Servers roamed the land and Oracle was for the high and might. Back when you went to work uphill both ways, taming thrashing and angry stored procedures and triggers.
We can boil it down pretty simply.
Thousands of lines of untamble SQL, sub queries upon subqueries, nested CASE statements, SQL files flung far and wide, no ryhm or reason, business logic repeated hundreds of times over.
DBA’s all red eyed and gone made, fighting dead locks and 4 hour queries trying to bring down their servers. Teaming hoards of Business Intelliegence Engineers and Analyts screaming and foaming about data models, producing mountains of inconsistent analytics, culminating in the mistrust of that cursed “Single Source of Truth.”
You may be young, but this is where many of us old-timers come from, this is our legacy. This is what wakes us up a night in a sweaty nightmare, the sound of an on-call phone going off, some deadlock somewhere just waiting till 2 a.m.
What was the root cause?
I will tell you what it was. Too much SQL.
- No tests
- Logic reproduced and spread everywhere.
- Business logic is scattered and inconsistent.
- Overly complicated queries.
- No rhyme or reason, other than the mood of a developer that day.
This is the logical end of all data systems built solely on SQL, with no guardrails.
It all starts fine, with stars and unicorns shining in the eyes. Some beautiful data models and DDL seem bulletproof. Then reality happens. Tight deadlines, bugs cropping up, the business getting nasty, lots of quick fixes, people coming and going.
And then you have it. The SQL spaghetti of our forefathers, in all its glory. After a few years, the only option is to start over and burn it all down.
The rise of Data Engineering and programming.
At some point, maybe about 10 years ago something happened. People got tired of it all.
Data Teams and managers kept looking longingly over their shoulders at those sexy software engineers with all their tests, CI/CD, processes, PR’s, systems, and generally greener grass. People started to ask … why can’t data be this way?
That led to something good … a flood of classic Software Engineering principals and people spilling over into the “Data World.” With that came good practices and programming.
Folks realized there was more to life than SQL. Spark got popular, Python took off in the data world, and things changed for the better. We had SQL, and we always will, but we had something else, another tool, code.
Things are coming full circle.
But alas, I wring my hands with displeasure and consternation. It’s coming full circle. Hey, I can sympathize with folk, SQL is the 7th wonder of the world. We would be crazy not to use it. It just fits the data. It lowers the bar.
Take SparkSQL for example.
Take an analyst, give them hundereds of TB’s of data, toss them over into a Databricks Notebook, spin up that cluster, and slap on the back and say good luck.
They will get it done. So much power, so easy, just a little SQL. What’s the problem?
It no longer takes someone with 5 years of experience with Big Data to drive insights, tune clusters, do ETL, and work on data models.
What’s the problem?
We start with good intentions.
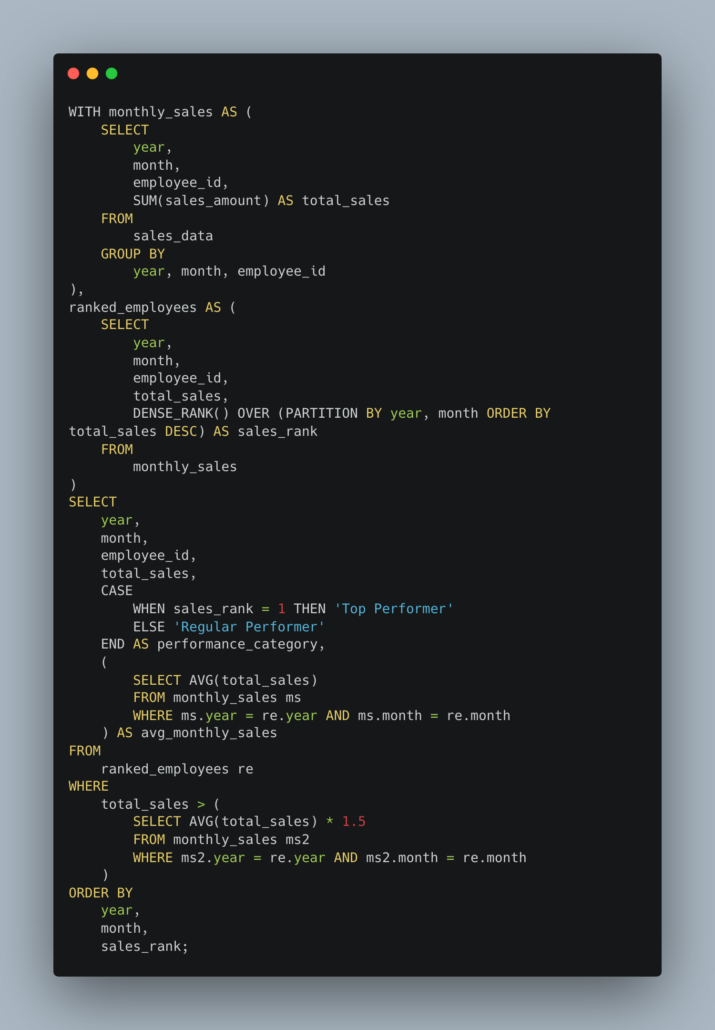
Something starts like this, then over time things get added, changed, and updated, it grows and morphs into something impossible. And it’s not just one of these, there are ten, twenty, thirty of them.
Overlapping logic, business decisions buried, re-written four times over for slightly different use cases. How do you answer a question from the business? It takes enormous effort to do the simplest things.
The worst part?
No tests, no modularity, and no reusability.
Think about, what’s a better way we could approach these sorts of problems in a more modular way, some way we can easily test our logic, reuse, mix-and-match, configure, etc.
By writing code.
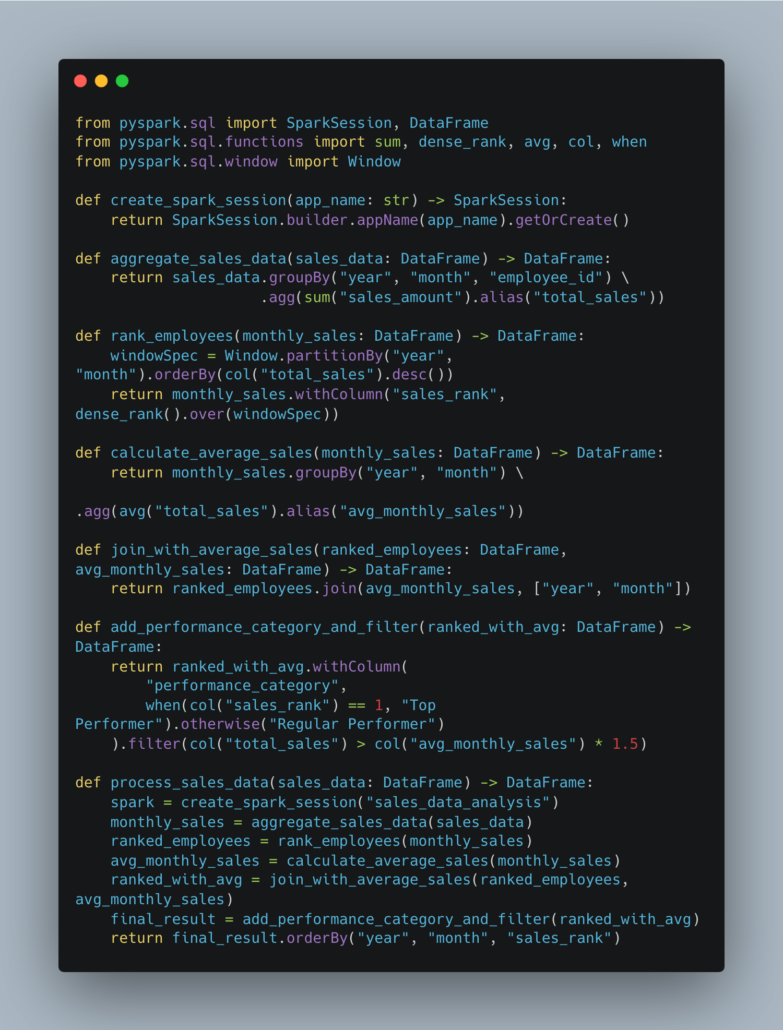
Do you want Data Pipelines you can debug? Data Pipelines that are easy to read, use, reconfigure, and reuse? Then don’t reach for SQL every single time.
Why am I coming down so hard on SparkSQL?
Because we live in the age of Databricks and the Notebook. Everyone and their cousin is writing SQL and crunching massive datasets. We take it for granted.
In our lust for getting it done and moving fast, we throw good engineering practices out the window.
The reality is there are SparkSQL functions and methods, with tools like Delta Lake, that are invaluable. I mean if you aren’t using MERGE statements in SQL you’re a silly hobbit.
But my friend, be wise. Be careful, wield that sword of SQL carefully. Be judicious in its use.

This article was written by a clown just don’t listen to this trash
But he’s right though
I agree. What bullshit
Exactly. You can modularize SparkSQL as well just like you can write one large spaghetti Python function. What a clown.
Thank you for sharing your info. I really appreciate your efforts and I am
waiting for your further post thanks once again.
This whole article confuses general bad engineering practice with the use of one specific language.
I would encourage anyone reading it to think more deeply about the techniques and tools they use than the author has.
I liked some of your articles but this one is blatantly wrong.
You could have these functions while still using SparkSQL in each of them. There’s no difference between using “.groupBy()” on a dataframe and “SELECT … GROUP BY” on a temp table. I agree with the others, bullshit article, best to ignore it.
I agree 100%. I recently shared on my Github a Databricks/PySpark template that follows this same idea for unit tests, CI/CD.
https://github.com/andre-salvati/databricks-template