Delta Lake without Spark (delta-rs). Innovation, cost savings, and other such matters.

The intersection of Big Data and Not Big Data.
An interesting topic of late that has been rattling around in my overcrowded head is the idea of Big Data vs Not Big Data, and the intersection thereof. I’ve been thinking about SAAS vendors, the Modern Data Stack, costs, and innovation. A great real-life example of all these topics is Delta Lake. Delta Lake is the child of Databricks, officially or not, and at a minimum has exploded in usage because of the increasing usage of Databricks and the popularity of Data Lakes.
Delta Lake, Hudi, Iceberg, all these ACID/CRUD abstractions on top of storage for Big Data have been game changers. But, as with any new popular tech, it comes with its own set of challenges. Specifically for Delta Lake … if you want to use it 99.9% of people are going to have to use Spark to do so, which can be costly, in terms of running clusters, and add complexity, in terms of new tooling, data pipelines, and the like. Anytime you only have one path to take with a tool, innovation is stifled, and barriers arise. Enter delta-rs the Standalone Rust API for Delta.
Is there a problem, and what is it?
So what’s the problem? Why can’t everyone just use Spark and Delta Lake together and move on with life? Well, that answer has to do with real-life Data Engineering and not just the marketing and sales content that is endlessly being pushed into the Data Space with ever-increasing velocity.
“Not every data project or data team is the same, we don’t always need or want to use
– MeSpark, pipeline costs are coming more into focus. Data Engineers need flexability and outside the box solutions to control cost and complexity.”
I’m a big fan of Delta Lake and Databricks, they are game changers for Big Data processing and storage. They can bring Machine Learning, Analytics, and Transformations to a massive scale with relatively low effort and complexity. But, there is always a sort of gotcha that can happen with these or any tools. What are some of these gotcha’s, and are there any real-world solutions Data Engineers can use to make a real difference in cost and complexity?
- You don’t always have to use Spark for some data sizes in certain situations.
- You pretty much have to use Spark + Delta Lake together.
- Using Spark for everything you do with Delta Lake ends up costing a lot.
- Innovation is stifled when you have to use a single tool to do a thing.

delta-rs : Solution to the Delta Lake + Spark problem?
So how could a Data Engineer save a company some real money? How could a Data Engineer innovate and solve more problems in a different way when working on the Delta Lake storage system? This is where the Rust “standalone” Delta Lake API comes in. What does this really mean?
You no longer need Spark to interact with and use Delta Lake. Below is a summary of how everyone uses Delta Lake today, sure it’s open source and you technically don’t need to use Databricks … but the reality is, below is what is happening today.
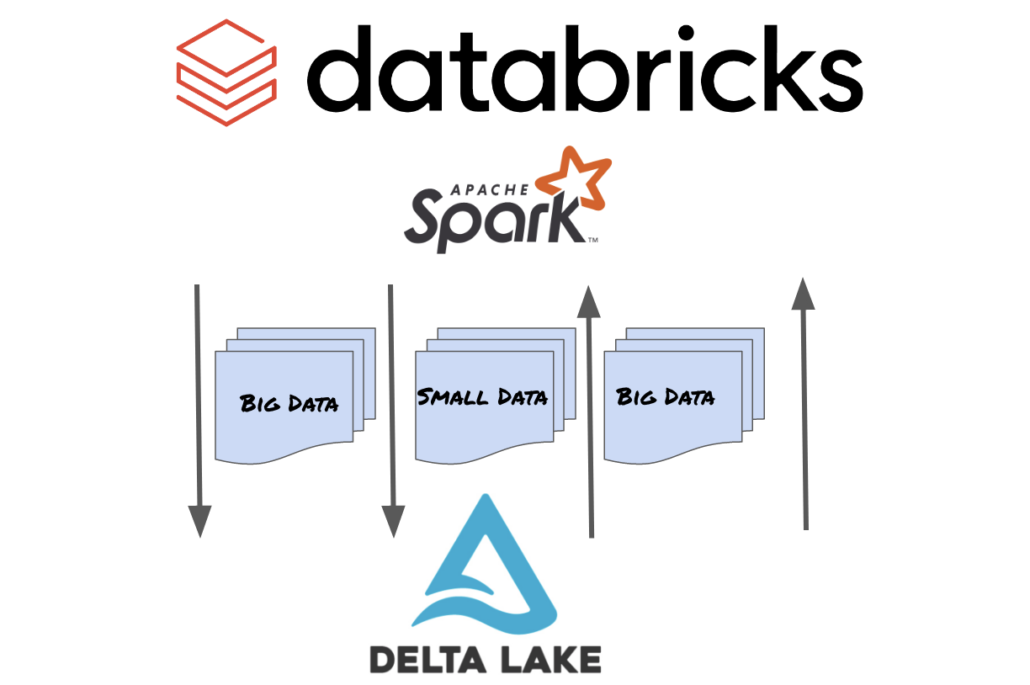
What else does the above picture show? Money, money, money. When your Data Architecture is based around Delta Lake as a storage system, that usually means everything has to be done with Spark … regardless of the data size in question … because that’s the only way you can interact with Delta Lake.
Not every use case fits this. What if you receive smaller-sized data sets in some incremental manner, say daily, that you need to ingest into Delta Lake. Sure, you probably have to use Spark for big transformation jobs, analytics, and other massive data crunching, there is nothing better. You DON’T need Spark to ingest a CSV or other flat-file. Honestly, it’s just an expensive way to operate in the long run.
On one hand, it’s easy to want to keep things consistent and make everything uniform, and it’s easier to reason about and manage large data pipelines. But, having more flexibility to control costs and push innovation forward when working on Delta Lake datasets is also important for any forward-thinking data team. Out-of-the-box architecture, and especially not just swallowing the pills the vendors throw at you is important. Being able to break free from Spark/Databricks when it comes to Delta Lake is an important part of making sure that technology stays around, stays useful, and is cost-effective in the long run.
Real-life delta-rs solution to a Delta Lake problem.
So enough talk, let’s see what it would look like to solve a real life sort of problem with delta-rs, a standalone Delta Rust API. It wouldn’t be uncommon to have to task of ingesting some sort of flat-file(s) , anywhere from a few MB to a few GB's in size, into some Delta Lake table. Today, that would mean that pretty much every Data Engineer approaching this problem would think of only a single way to solve this problem.
- Write a
Sparkpipeline to pushflat-filerecords into Delta Lake. - Sechedule such a pipeline on Databricks, EMR, Glue, or some other Spark runner.
- Maybe try to tune cluster size to fit the need.
This is unfortunate for a few reasons.
- It’s expensive to use Spark to ingest
flat-files. - Many times ingest data size doesn’t require
Spark. - It can end up being overkill and overly complex to write a
Sparkscript for such a simple need.
There is yet a more excellent way. How could we save costs? How could we simplify such an easy task as ingesting a CSV into Delta Lake. What if we could just schedule an AWS lambda with just a little bit of Rust code and push flat-file records into a Delta table? Talk about an easy and money saving endevor.
The following code is going to show us that this is a very possible approach.
Example delta-rs usage.
The first step in our example is to create an existing Delta table based on some open source data, the Divvy Bike Trip data set. Let’s use Python to do this. Simply download a csv file and run this script.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('Example').enableHiveSupport().getOrCreate()
df = spark.read.csv("./202208-divvy-tripdata.csv", header='true')
df.write.format("delta").save("./rust_delta/trips")Easy, now we have an existing Delta table, but how can we write more records to this Delta table without Spark? With delta-rs and Rust of course.
use csv;
use deltalake;
use serde_json::json;
#[tokio::main]
async fn main() {
// Setup DELTA table.
let table = deltalake::open_table("./trips").await.unwrap();
let mut wrtr = deltalake::writer::BufferedJsonWriter::try_new(table).unwrap();
// Read CSV data to write to Delta table
let mut reader = csv::Reader::from_path("202105-divvy-tripdata.csv");
for result in reader.expect("REASON").records() {
let record = result.unwrap();
let ride_id = &record[0];
let rideable_type = &record[1];
let started_at = &record[2];
let ended_at = &record[3];
let start_station_name = &record[4];
let start_station_id = &record[5];
let end_station_name = &record[6];
let end_station_id = &record[7];
let start_lat = &record[8];
let start_lng = &record[9];
let end_lat = &record[10];
let end_lng = &record[11];
let member_casual = &record[12];
let v = json!({
"ride_id": &ride_id,
"rideable_type": &rideable_type,
"started_at": &started_at,
"ended_at": &ended_at,
"start_station_name": &start_station_name,
"start_station_id": &start_station_id,
"end_station_name": &end_station_name,
"end_station_id": &end_station_id,
"start_lat": &start_lat,
"start_lng": &start_lng,
"end_lat": &end_lat,
"end_lng": &end_lng,
"member_casual": &member_casual
});
wrtr.write(v, deltalake::writer::WriterPartition::NoPartitions).unwrap();
}
let cnt = wrtr.count(&deltalake::writer::WriterPartition::NoPartitions);
println!("{:?}", cnt);
wrtr.flush().await.unwrap();
}I mean, how easy was that? Even if you’re not familiar with Rust, like me, it’s pretty obvious what is happening and easy to see how such code be written and hardened, and put into a lambda or run on a small EC2 instance.
If you want to get more familiar with delta-rs, head on over to the docs, although good luck, they suck. But, let’s just review at a high level what is going on here.
let table = deltalake::open_table("./trips").await.unwrap();let mut wrtr = deltalake::writer::BufferedJsonWriter::try_new(table).unwrap();- Read a CSV file and iterate the results.
let mut reader = csv::Reader::from_path("202105-divvy-tripdata.csv");
for result in reader.expect("REASON").records() {
let record = result.unwrap();
let ride_id = &record[0];
let rideable_type = &record[1];
let started_at = &record[2];
let ended_at = &record[3];
let start_station_name = &record[4];
let start_station_id = &record[5];
let end_station_name = &record[6];
let end_station_id = &record[7];
let start_lat = &record[8];
let start_lng = &record[9];
let end_lat = &record[10];
let end_lng = &record[11];
let member_casual = &record[12];- Convert the records to a
JSONobject as required by thedelta-rsBufferedJsonWriter.
let v = json!({
"ride_id": &ride_id,
"rideable_type": &rideable_type,
"started_at": &started_at,
"ended_at": &ended_at,
"start_station_name": &start_station_name,
"start_station_id": &start_station_id,
"end_station_name": &end_station_name,
"end_station_id": &end_station_id,
"start_lat": &start_lat,
"start_lng": &start_lng,
"end_lat": &end_lat,
"end_lng": &end_lng,
"member_casual": &member_casual
});- Write the
recordinto thebuffer.
wrtr.write(v, deltalake::writer::WriterPartition::NoPartitions).unwrap();- Count the number of records in the
buffer, thenflushthem toparquetfiles in theDeltatable.
let cnt = wrtr.count(&deltalake::writer::WriterPartition::NoPartitions);
println!("{:?}", cnt);
wrtr.flush().await.unwrap();Of course not production ready code, but you get the idea. Most likely less lines of code than a Spark ingest script, definitely going to be way cheaper if the data ingest size is just normal flat-files. Such code could easily be wrapped into a Docker image, run with a lambda , or on a tiny EC2 and save a lot of money and complexity over deploying Spark code to a cluster to do the same work.
Musings
delta-rs seems to a great leap forward for the Delta Lake community. Espeically if the delta-rs project adds support for the Python bindings to be able to use the Writer (just reader) right now. To me it feels like the Rust and delta-rs community really need to work on the documentation, examples, and Python bindings, as well as maybe make some nice command line tools or wrappers to easy certain obvious use cases likes ingesting CSV files into Delta Lake.
The biggest barrier to this type of Rust tooling is that basically most Data Engineers who are working on Delta lakes are probably not normal Rust users. Second, you need good documentation and examples to help people grasp offered features and their use and implementation. This is too bad because doing such a simple thing as starting to migrate ingest of data into Delta from Spark clusters to some Rust program running on a EC2 or lambda would probably save some significant money for a lot of Data Teams.
Also, I’m sitting here thinking … why hasn’t anyone starting some nice command-line tools to build more cost effective and easy to use Delta ingestion tools? Seems like a no brainer, and it would be an easy and obvious cost savings. I’m excited to see what delta-rs, and it’s integrations with tools like data-fusion mean for the future of Delta Lake.
Great blog post Daniel! A couple of quick notes:
– Delta Rust Python recently included write support per https://github.com/delta-io/delta-rs/issues/575
– Check out the Delta Rust roadmap at https://go.delta.io/rust-roadmap and the overall Delta roadmap at https://go.delta.io/roadmap.
Thanks again!