Intro to Apache Druid … What is this Devilry

Apache Druid, kinda like that second cousin you know about … but don’t really know. When you see them for the first time in 10 years you kinda look at them out of the corner of your eye. That’s how I feel about Apache Druid, I’ve always known it has been there, lurking around in the shadows, but it rarely pokes it head out and I have no idea what, why, how it is used. Time to change that, for the better or worse. Let’s take 10,000 foot survey of Druid.
Introduction to Apache Druid
Just what we need, another distributed analytics engine to add to the long list …. sigh.
“Apache Druid is a real-time analytics database designed for fast slice-and-dice analytics (“OLAP” queries) on large data sets.”
Apache Druid website
If you read the Apache Druid documentation etc you will basically find that it is touted as very fast, distributed analytical tool used to ….
- feed front end or backend applications that need “analytics” or aggregations
- appears to prefer “event-oriented data” .. although this isn’t a hard-and-fast rule.
- overall Business Intelligence tool.
- batch or streaming
If you keep reading about Apache Druid the documentation starts to talk about using “columnar” storage, uses indexes. This is confusing because initially reading the documentation you start to compare Druid to Apache Spark … seeing just as a processing engine, not necessarily a storage engine.
I guess I missed the “database” part of the analytics engine in the first quote. So in my mind I’m thinking of Apache Druid like combination of Spark and Parquet, rolled up into a single system.
What they say Apache Druid isn’t good at.
Sometimes it helps to look at the bad end.
- high insert volume, not much for updates. If your updating data a lot, not a good choice.
- most queries are over a single table, don’t need lots of big joins.
- if your looking for an offline BI reporting system where query speeds don’t matter much.
Reminds me a little of Presto.
What I think Apache Druid would be used for
I really see Apache Druid has a great high volume incoming stream event analytics distributed database engine. Near-real time analytics dashboard and the such seem like a perfect fit for Druid.
Also, something not to be driven past is the fact that Apache Druid says nothing about ETL or transformations … it’s different from Spark, Beam and others in the fact that its a database for analytics, it doesn’t seem to be selling itself as a ETL and analytics tool in one …. like Spark.
What I’m not so sure about, and I had the same thoughts about Presto, is that Druid talks a lot about Business Intelligence and analytics, but at the same time says joins are not its strong suit. As someone who has worked in data warehouses and business intelligence for years, I get it, but I don’t get it.
Not being able to support things like large joins seems to narrow the field to very specific use cases.
Is it worth it to use a new tool and infrastructure just to solve the problem of real time analytics for large single datasets? Probably for some massive enterprises …. but probably not for 80% of the Business Intelligence uses cases.
Exploring Apache Druid
You can start to explore Apache Druid concepts by using their official Docker image. Also, a nice docker-compose file is provided here, use also the provide environment file provided here. Place the docker-compose.yaml file and the environment file from the above links into a location on your machine, then run docker-compose up.
Another option to play around with is just to install in locally. Running the below will give you a UI located at http://localhost:8888/unified-console.html
curl https://mirrors.ocf.berkeley.edu/apache/druid/0.21.0/apache-druid-0.21.0-bin.tar.gz --output apache-druid-0.21.0-bin.tar.gz
tar -xzf apache-druid-0.21.0-bin.tar.gz
cd apache-druid-0.21.0
./bin/start-micro-quickstartDruid the database.
The documentation doesn’t talk about the backend of Druid (database) that much. It calls the backend file storage a “segment(s)” and says it stores a “few million” records per segment. It calls the process of ingesting data into Druid “indexing.” It talked about something called a “middlemanager” which appears to be what manages loading the data.
It can of course support both streaming (kafka, etc) and batch data ingest. It appears based on the UI you can load batch data from about anywhere your heart desires.
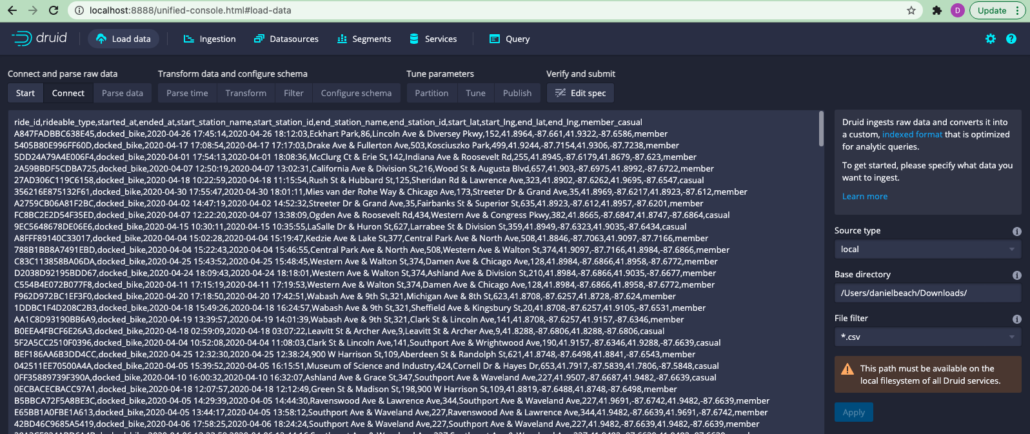
I clicked load data from “local disk.” I downloaded some of the divvy bike trip free data, in csv format. Filled in the info below and poof the data shows up in the UI.
As you walk through the UI, it asks you all sorts of questions and allows you to filter, transform, assign schema and a bunch of other tasks to the data including partitioning by time or date.
Once you have filled out everything necessary fo the datasource you hit submit and Druid starts to ingest the data into its database.
Druid Queries
At this point Druid is totally different then what I thought it was. I’m impressed with nice UI and the easy and intuitive GUI that allows you load data from many different data sources. Now I see why they call this a Business Intelligence tool.
Druid has a python package called pydruid that exposes the ability to do queries on data in Druid. When I was approaching this project as a data engineer would approach Spark, I just assumed there would not be a nice UI like this and that all the data loading etc would done via code. We data engineers love code, but this nice UI for loading data is a Business Intelligence team’s dream come true.
Once the data is loaded you get a nice workbench for funning SQL queries.
The SQL dialect is slightly different from ANSI, but easy enough. For example if I want to could the number of bike rides per day….
SELECT EXTRACT(MONTH from __time) as mnth, EXTRACT(DAY from __time) as day_of_month, count(*) as ride_count
FROM bike_Trips
GROUP BY EXTRACT(MONTH from __time), EXTRACT(DAY from __time)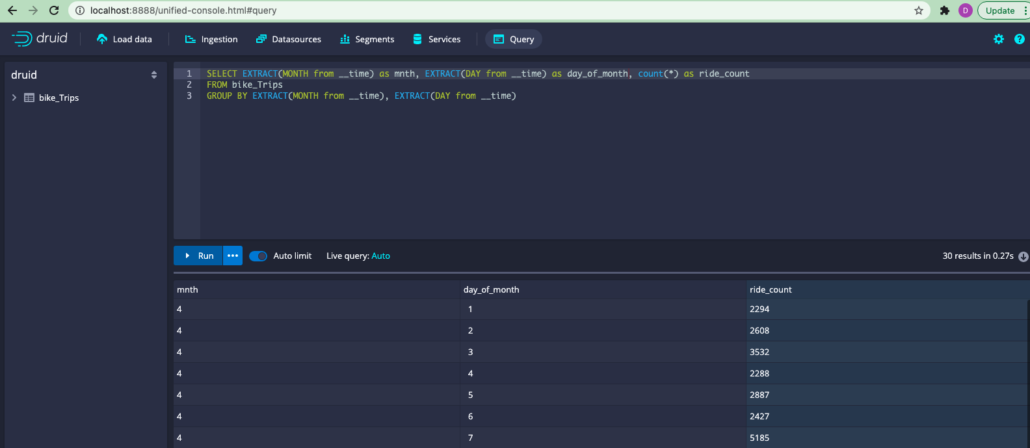
I have to be honest, back in my Business Intelligence Engineer days I would have killed for a nice tool like this. I can think of a few different situations where working with a variety of structured and semi-structured data scattered around, Apache Druid appears to be a nice tool to explore and do analytics on datasets.
In some sense it appears to be a lot like AWS Athena or Google BigQuery in the sense you can load just about any data and start running SQL queries on-top of the data.
Apache Druid Musings
I know I’ve barely scratched the surface of Apache Druid, but you have to start somewhere. I have a lot better idea of what Apache Druid is all about. It appears to be geared for high volume streaming data ingestion, which low latency SQL queries on-top of that data.
I can see its value for Business Intelligence teams wanting to get quick insights on a variety of data stored in a variety of places. I love the nice GUI and the straight forward way to load data sources, the SQL workbench is also very nice.
The web REST API’s also provided to be able to run queries seem powerful in the sense that it makes embedding Druid queries into any type of application very easy.