Sometimes I get to feeling nostalgic for the good ol’ days. What days am I talking about? My Data Engineering days when all I had to worry about was reading files with Python and throwing stuff into Postgres or some other database. The good ol’ days. The other day I was reminiscing about what I worked on a lot during the beginning of my data career. Relational databases plus Python was pretty much the name of the game.
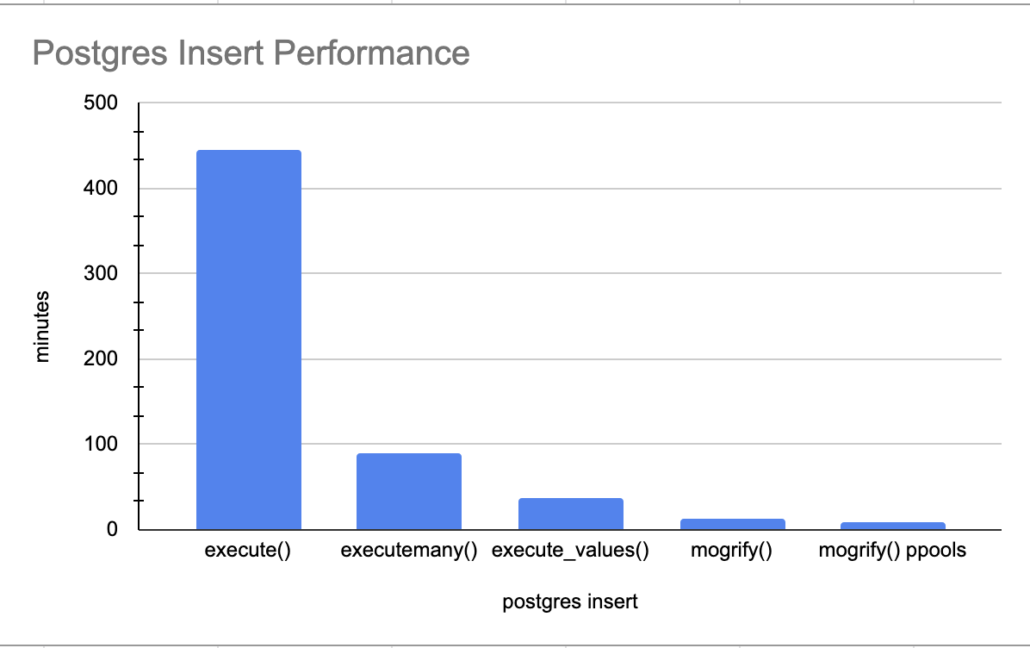
One of the struggles I always had was how fast can I load this data into Postgres? psycopg2 was always my Python package of choice for working with Postgres, it’s a wonderful library. Today I want to give a shout-out to my old self by performance testing Python inserts into Postgres. There are about a million ways and sizes and shapes to getting a bunch of records from some CSV file, through Python, and into Postgres.
I also enjoy making people mad … there’s always that. Nothing makes people mad at you like a good ol’ performance test 🙂
Read more