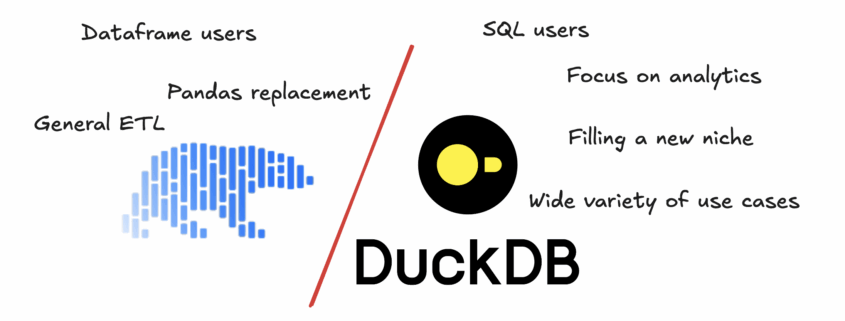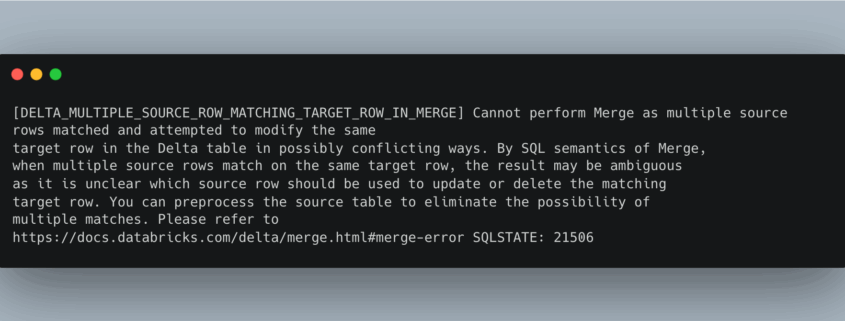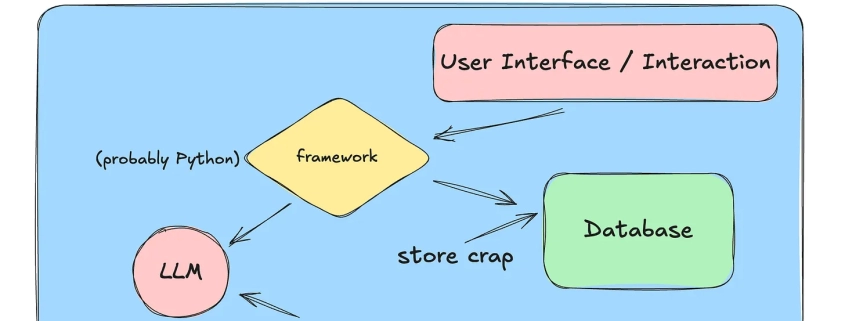
Things have changed a lot in the last year related to LLMs and AI; on the one hand, it seems the AI skeptics for coding are increasingly confined to the corners of the internet. Everyone is dancing around in the middle, not sure of where everything should fall. Clearly, if we don’t use AI at all, we will become coding dinosaurs. But a sea of junior devs relying too much on Cursor has created a knowledge crisis, and demand for Senior+ devs has skyrocketed.