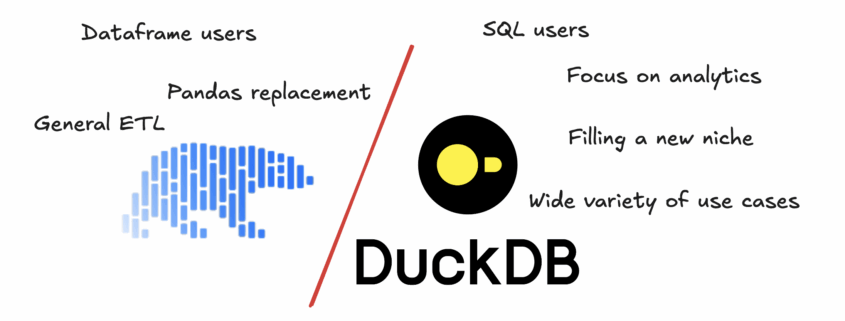

So, the classic newbie question. DuckDB vs Polars, which one should you pick?
This is an interesting question, and actually drives a lot of search traffic to this website on which you find yourself wasting time. I thank you for that.
This is probably the most classic type of question that all developers eventually ask at some point in their sad and depressing lives. Isn’t that the same story that is as old as time? This stick is better than that rock. Rust is better than C. Databricks better than Snowflake. You know, Delta Lake better than Iceberg.
And so the world keeps turning and grinding away.