The Fastest Way to Insert Data to Postgres
I was recently working on a PySpark pipeline in which I was using the JDBC option to write about 22 million records from a Spark DataFrame into a Postgres RDS database. Hey, why not use the built in method provided by Spark, how bad could it be? I mean it’s not like the creators and maintainers of Spark aren’t probably our version of rocket engineers.
Well, a few hours later staring at my screen, I knew something had to change. Slower than your grandma on her way to the quilt shop.
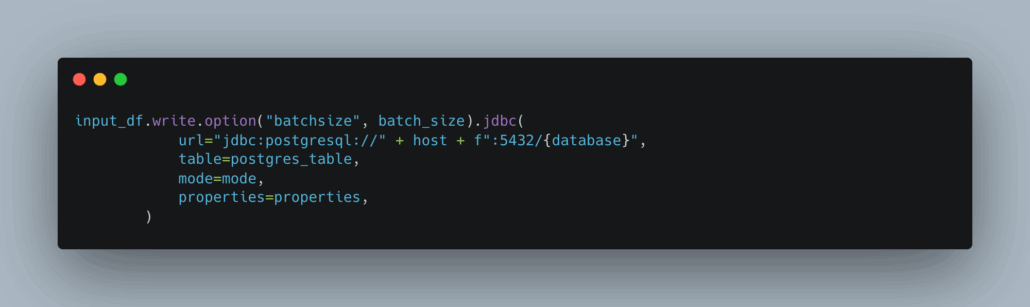
input_df.write.option("batchsize", batch_size).jdbc(
url="jdbc:postgresql://" + host + f":5432/{database}",
table=postgres_table,
mode=mode,
properties=properties,
)This is a problem as old as time. I started writing code on a Mac decades ago, cutting my teeth on Perl, PHP, and MySQL … I loved nothing more than playing around with a LAMP stack. When it comes to relational databases, nothing really has changed much … like at all.
Here I sit decades later still waiting to shove a batch of data into a RDBMS, in this case Postgres. You know what else has not changed? How flipping slow it is.
I figured by now that all those rocket engineers would have some amazing “thingy” that would magically make those relational databases ingest data faster. But no, they always end up being a bottleneck.
So, what’ s a guy to do when Spark can’t figure out how to shove a few million records into a Postgres database in a reasonable timeframe? Crack open the bag and pull out Python, and combine Spark and Python together to get the job done.
The problem is I’ve spent the last decade using distributed systems to smack around datasets in the hundreds of terabytes level. This has left my wholly unprepared for what has been happening in the Postgres world, in regards to data ingestion, which is apparently a whole lotta nothing.
Python + Spark to super charge ingestion.
So, without further ado, here is my Python code, combined with Sparks multi-processing ability to eat up large datasets and get them into Postgres at a record pace.

Of course we start with a few pip installs, nothing like the old psycopg that has been around since before Father Christmas.
Here is the magic.
Notice the configs and DataFrame at the top, in my case it was a Delta Lake table, but it could be CSV files, Parquets, Iceberg, … whatever.

In all it’s glory.
Basically, if your DataFrame isn’t overly large, 22 million records is not, we can repartition that dataset into the number of Writers we want running at once, I randomly picked 4.
At that point foreachPartition() we can pass in something to do, in our case a function that takes that partition batch and puts it inside the Postgres database.
The key here is to use the COPY approach.
COPYmoves data between PostgreSQL tables and standard file-system files.COPY TOcopies the contents of a table to a file, whileCOPY FROMcopies data from a file to a table (appending the data to whatever is in the table already).COPY TOcan also copy the results of aSELECTquery.
– Postgres
Using this method I was able to get Spark to insert 22 million (a wide table) records into Postgres in less than 14 minutes.
Why is this so fast?
Short version: using Postgres’s bulk-loader the way it was designed to be used, pushing big, contiguous chunks from multiple Spark executors straight into COPY … FROM STDIN, and you’ve removed a bunch of per-row overhead that kills JDBC.
Here’s what makes the pattern fast:
COPYvsINSERT(JDBC)- JDBC
.writeuses prepared INSERTs in batches. Every batch incurs parse/plan/execution overhead, per-row type binding, many round-trips, and transaction bookkeeping. COPYis a specialized bulk path inside Postgres. It parses a stream and stuffs pages as fast as storage and WAL allow—dramatically fewer syscalls and protocol messages than INSERT batches.- Parallel writers from Spark
df.repartition(WRITERS).foreachPartition(copy_partition)gives youWRITERSconcurrentCOPYstreams (one connection per partition). That lets you saturate CPU, I/O, and WAL bandwidth on the Postgres box—something a single JDBC connection can’t do.
You can’t beat the old school. STDIN will always win the day. COPY is the way to go with Postgres data inserts, never to INSERT with batches, just so much slower.
The End
Sometimes is pays to look into things a little bit, think outside the box. Using the parallel nature of Spark, the ability to work on partitions at the same time, applying our Python COPY logic for Postgres … is the perfect pairing of two technologies to solve an annoying problem.
It’s been awhile since I’ve had to play with a relational database in a serious way, it’s aways good to have a “new to you” problem that you’ve not worked on in awhile. Get the ole’ brain juices flowing.

