SQL Database (RDBMS) Design for Data Engineers

Database design… hmmm. There is probably nothing more all over the board in tech. Data warehousing, analytics, OLTP… everyone with their own “defend this hill to the death” ideas. Kimball vs Inmon. Hmmm.. what to do, what to do? After defending my own hills to the death over the years and arguing over whiteboards I’ve come to a conclusion. The right answer is somewhere in the middle. Understanding a few basic design principals will help any data engineer master writing DDL for anything from a Data Warehouse to a high load OLTP systems… across all RDBMS platforms.
Two things every Data Engineering should know about database design.
There are a lot of topics in all those online courses that others will say you need to know as someone who is in charge of databases/design/SQL. Some of it will be true and a lot of it will be fluff. Don’t get me wrong here, I’ve spent years filling out my SQL skills, working on Data Warehouse teams, tuning queries in high volume OLTP systems etc. You can never have to much knowledge and experience when it comes to RDBMS databases. But, when you boil all that knowledge down there are a few things that if you understand from the beginning, will save you lots of headaches… and make you smarter then 80% of the other engineers lurking around on StackOverflow.
- OLAP (Online Analytical Processing)
- OLTP (Online Transactional Processing)
You need to understand that in general there are two different types of databases you will run into or have to design and query. Those are Online Transactional Processing and Online Analytical Processing. Those are fancy names, don’t worry about it.
All it means is that some databases (OLTP) and by extension the applications they support, are designed more for high volume transactional type data flows ( say tons of small and fast inserts )…. thinking manufacturing widgets, customer orders, or financial transactions.
Then you have the OLAP databases… this would be common in Data Warehousing and Business Intelligence… those are the databases that are designed to collect and report some sort of metrics about the data. The queries hitting this databases are usually large and “complex.” Aka queries that my be grouping, filtering, join whole large tables over all records.
This is a little oversimplified, but below, in general, is what I’m talking about. It’s the overall point here that matters.
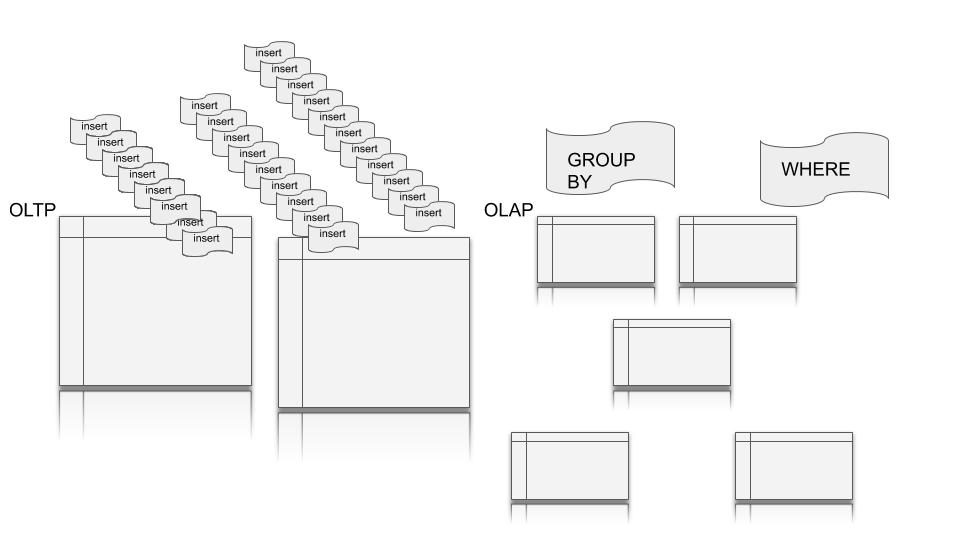
The difference between OLTP and OLAP
So what, how should the idea of OLTP and OLAP impact my database design?
Yes, the idea behind OLTP and OLAP should impact your database design. These are things Data Engineers should understand at a fundamental level. Just as when writing code for a ETL or Big Data pipeline, you usually ask what is the expected end, what are we trying to do here, who are we supporting with this data?
- It’s ok to apply OLTP and OLAP ideas to different tables in the same database.
- Are you writing DDL that needs to support a high number of transactions with low friction? (maybe tons of inserts and delete)
- Are you writing DDL that needs to support fewer queries that will be analyzing the data stored in the database?
- Do you have an understanding what the queries/transactions coming into the database will look like?
You should be able to answer these questions before embarking on any database/table design project.
The real world impact of OLTP and OLAP on DDL.
OLTP tables and databases will most likely have fewer, wider tables. OLAP tables and database design will most likely include many shorter tables requiring more joins and less data redundancy.
- If you have a lot of transactions/queries that are “simple” entering the database it makes sense to have say a single large table that all the data can be inserted into for example.
- If you have fewer but larger and complex queries that need to summarize and aggregate large amounts of data, for performance reasons it probably makes sense to normalize the data structures/tables into some sort of star schema that will allow the RDBMS to more effectively gather and processes the data.
A Real World Example.
Someone comes to you and says the company is building a new website where all the customer orders will be entered. They are selling a hot new widget and expect a million orders a day, the web Devs need a database to send the orders to.
They give you a sample JSON that will be sent to you.
{
“order_number” : “123SDFASSDFGD1234”,
“order_details”: {
“order_start_timestamp”: “2016-06-22 19:10:25-07”,
“order_end_timestamp”: “2016-06-22 19:12:30-05”,
“total_items”: 4,
“total_value”: 20.00
“currency”: “USD”
},
“items_ordered”: {
“product_123”: { “quantity”: 1,
“price”: 5,
“product_group”: 1A,
“description”: “widget A”
},
“product_456”: { “quantity”: 1,
“price”: 5,
“product_group”: 1B,
“description”: “widget AB”
},
“product_789”: { “quantity”: 1,
“price”: 5,
“product_group”: 1C,
“description”: “widget C”
},
“product_100”: { “quantity”: 1,
“price”: 5,
“product_group”: 1O,
“description”: “widget O”
}
},
“customer_information”: {
“first_name”: “Frodo”,
“last_name”: “Baggings”,
“address”: “The Shire, Bag End.”
"customer_id": 12345
}
}Most likely in a high volume situation with a high number of inserts for customer orders flying into the database, you are probably just going to flatten the JSON and insert directly into a single customer orders table. Most likely something like this.
CREATE TABLE customer_orders
(
id SERIAL,
order_number VARCHAR(150),
order_start_timestamp TIMESTAMP,
order_end_timestamp TIMESTAMP,
total_items INT,
total_value MONEY,
currency VARCHAR(20),
product_id VARCHAR(150),
quantity INT,
price MONEY,
product_group_id VARCHAR(20),
description VARCHAR(500),
first_name VARCHAR(150),
last_name VARCHAR(150),
address VARCHAR(500),
customer_id INT
)This makes sense for a high volume system to quickly processes lots of incoming orders into the database. There is no need or want to split the order data out into multiple tables… imagine added the overhead of splitting up the data into groups, inserting into different tables, trying to keep the referential integrity between the data… and what if one table insert fails… rolling back the others. As you can see, probably not a wise road to go down for this use case.
Your boss transfers you to the Business Intelligence team. They tell you the Big Cheese wants a daily summary report of sales by customer, product, product group. They want to know what items are selling the most, blah blah, blah.
This is obviously a whole different problem, more of a data warehousing and analytical style of approach is required. This will fundamentally change the way you design tables to answer these questions and the questions you know are coming.
Every data engineer should understand the concept of Third Normal Form. Ok, lets be real, you don’t need to memorize the different levels of database normalization, just the concept behind the concept.
- Reducing data duplication.
- Simplify the management of the data.
- Organize the data in ways that support the analytical queries on the data.
The extent to how far you should take these concepts probably depends on the team and project you are working on. Are you supporting a true Data Warehouse in every sense of the word? Then you do probably need to study Kimball and implement Facts and Dimensions as part of your design. Here is a far from perfect example using the above data of an approach we might take.
CREATE TABLE orders
(
order_number VARCHAR(150),
order_start_timestamp TIMESTAMP,
order_end_timestamp TIMESTAMP,
total_items INT,
total_value MONEY,
currency VARCHAR(20),
customer_id INT
)
CREATE TABLE order_details
(
order_number VARCHAR(150),
product_id VARCHAR(150),
quantity INT,
price MONEY,
product_group_id VARCHAR(20),
description VARCHAR(500),
)
CREATE TABLE customers
(
first_name VARCHAR(150),
last_name VARCHAR(150),
address VARCHAR(500),
customer_id INT
)I’m sure you can see the difference right away. Here we are more worried about putting the data into a design that supports how the data is going to be analyzed…. by customer, by product etc.
These are two trivial examples, but they show the difference between OLTP and OLAP design approaches how they should affect data engineers and their design of database systems.
The last thing every Data Engineer should know about database design.
One of the most common problem with database design at all levels, by everyone, is the failure to put thought and time into Indexing the database and tables. I would even go as far as to say that adding more than just a primary key to a database table puts you in the top 20% of data engineers.
This is another topic that people spend their whole lives working to master. That’s ok. If you can remember small number of ideas around indexing relational database tables, your database won’t bog down and your queries will be fast.
- Each table you design should have a primary key. If you can’t come up with one, your design is probably bad.
- Each table should most likely have more indexes beyond just the primary key. Unless it never gets queried. 🙂
- Columns in your tables that are used in the JOIN, WHERE, and GROUP by clauses of queries should be in your indexes.
Relational databases thrive aggregating and joining data, but they were designed to require proper indexing to do this work efficiently and effectively. Take for example the order_details table above. Most likely we would be aggregating around things like product_id, product_group_id, and price. It’s pretty obvious a non-primary key should be added to these fields.
And that is all it really takes. Understanding the queries running against your database design is an important step, how else will you know what indexes should be used?
Conclusion – The Big Picture
Notice we didn’t talk about which RDMBS system a single time. We didn’t say anything about Oracle, SQL Server, Postgres, MySQL…. and there is a reason for that. Sure, if you work with databases all day long exclusively there are nuances to each system you should learn and take advantage of. But 80% of the battle is just understanding the big picture.
What type of system am I designing for, OLTP vs OLAP. Do I need elements of both? What do the queries look like that will be used and needed to support the data coming into my database? What columns should I index that make sense in that context. These aren’t super hard or difficult concepts to figure out, but pay dividends in the backend when systems and queries are up and running. By doing the bare minimum any Data Engineer should do, you will be far ahead of the pack.