Review of Airbyte for Data Engineers

It’s hard to keep up with the never-ending stream of new Data Engineering tools these days. Always something new around the next bend. I find it interesting to kick the tries on the new kids on the block. It’s always interesting to see what angle or pain point a new tool tries to hone in on. I mean if you think about Data Engineering in general, the fundamentals really haven’t changed that much over the years, the tools change, but what we do hasn’t. We are expected to move data from point A to point B in a reliable, scalable, and efficient manner.
Today I’m going to be reviewing a tool called Airbyte. When I review a new product I’m usually incredibly basic about what I look for and I try to answer some easy and obvious questions. How easy is it to set up and use? What does the documentation look like? When I run into a problem can I solve it? Is the overhead of adding this new tool to a tech stack worth what features it offers? This is how we will explore Airbyte.
So … what is Airbyte?
This might sound like a simple question, but I always try to figure this out first to set expectations. Every tool is always trying to solve certain problems, and trying to figure out what is at the heart of some technology, where it excels, is core to understanding how to best use it and what to expect from it.
So, how easy is it to answer this with Airbyte?
“Open-source data integration for modern data teams.”
Airbyte website.
I know that’s not much but It does say a couple of things to me. It says “we are good at data transformations.” To me, it says connect to any data source and run some transform or ETL/ELT (don’t get me started on this argument … I mean seriously.)
So Airbyte is about pipelines.
Wait… I did see something sly slipped into their verbiage that made me take a pause.
“Transform raw or normalized, with dbt-based transformations.”
Airbyte website
Why did this make me pause? Because when I was first reading about Airbyte I was thinking general pipeline tool for everything, something like Airflow maybe.
In my mind that is a massive difference. I mean dbt is SQL-based, and there are lots of data transformations that are not SQL-based. I mean you kinda need to know that up front with a tool, is it for SQL, or can it handle my parquet and avro files?
I guess time will tell.
Installing and using Airbyte.
Apparently, you get Airbyte by using docker , which is always a good sign. That means no issues with packages and dependencies.
Supposedly as easy as running…
git clone https://github.com/airbytehq/airbyte.git
cd airbyte
docker-compose upWell …. a big old nothing. That’s disappointing.
My docker-compose command gives a bunch of java errors and a message about waiting for a server … and the UI that is supposed to come up on port 8000 is dead.
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage._apply(RoutingStage.java:86) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage._apply(RoutingStage.java:89) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage._apply(RoutingStage.java:89) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage._apply(RoutingStage.java:89) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage._apply(RoutingStage.java:89) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage.apply(RoutingStage.java:69) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.internal.routing.RoutingStage.apply(RoutingStage.java:38) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.process.internal.Stages.process(Stages.java:173) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.ServerRuntime$1.run(ServerRuntime.java:245) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.internal.Errors$1.call(Errors.java:248) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.internal.Errors$1.call(Errors.java:244) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.internal.Errors.process(Errors.java:292) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.internal.Errors.process(Errors.java:274) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.internal.Errors.process(Errors.java:244) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.process.internal.RequestScope.runInScope(RequestScope.java:265) ~[jersey-common-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.ServerRuntime.process(ServerRuntime.java:232) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.server.ApplicationHandler.handle(ApplicationHandler.java:680) ~[jersey-server-2.31.jar:?]
airbyte-server | at org.glassfish.jersey.servlet.WebComponent.serviceImpl(WebComponent.java:394) ~[jersey-container-servlet-core-2.31.jar:?]
airbyte-server | ... 30 more
airbyte-scheduler | 2021-10-13 20:30:33 INFO i.a.s.a.SchedulerApp(waitForServer):181 - {workspace_app_root=/tmp/workspace/scheduler/logs} - Waiting for server to become available...
2021-10-13 20:32:39 WARN o.e.j.s.HttpChannel(handleException):600 - {workspace_app_root=/tmp/workspace/server/logs} - /api/v1/health
airbyte-server | javax.servlet.ServletException: A MultiException has 1 exceptions. They are:
airbyte-server | 1. java.lang.NoClassDefFoundError: Could not initialize class com.github.slugify.SlugifyOh boy… what now?
At least they have a troubleshooting document on the web.
I guess I will try docker-compose down and docker-compose up again. But when has that ever fixed anything? No such luck. Still not working.
Pulling the Docker logs gives me what the problem is java.lang.NoClassDefFoundError: Could not initialize class com.github.slugify.Slugify
But who knows what to do? I’m just trying to run the tool and I already have problems? This doesn’t inspire confidence. Either the setup even with Docker is too complex and not stable, or something else. How are you supposed to reliability host this yourself in production?
I mean being able to actually run the tools is pretty core to trying something out.
I also tried docker restart airbyte-server airbyte-scheduler
Well …… I’ll be, that did the trick! It’s up and running!
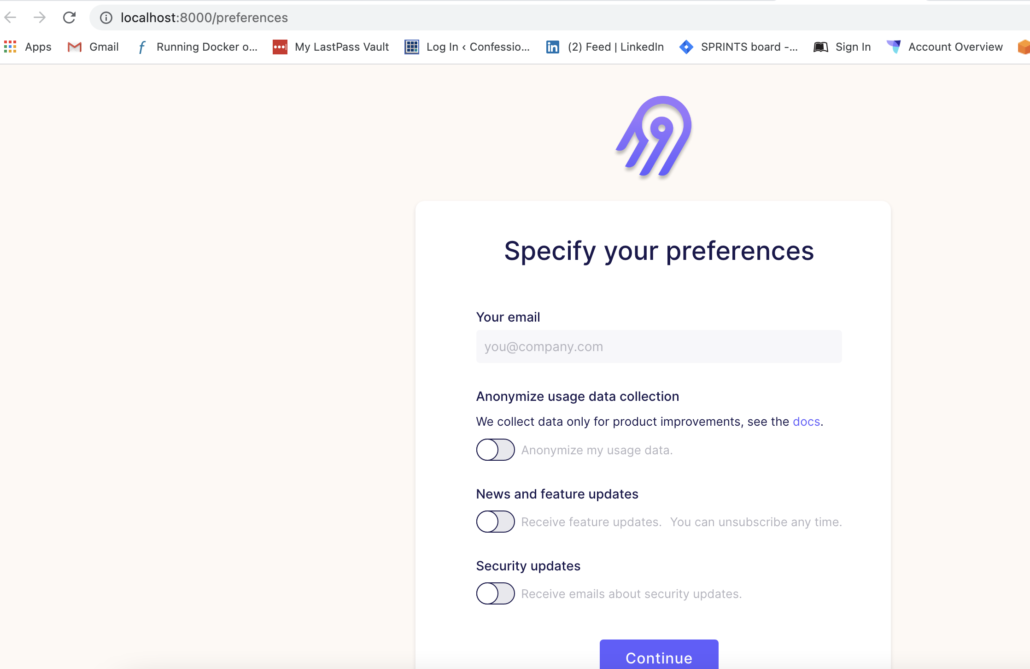
So now we have the beast running, let’s try to understand the major components of Airbyte.
Understanding Airbyte and its componets.
As you can see from the UI screenshot below, it appears there are a few obvious topics we should know about.
- Connections
- Sources
- Destinations
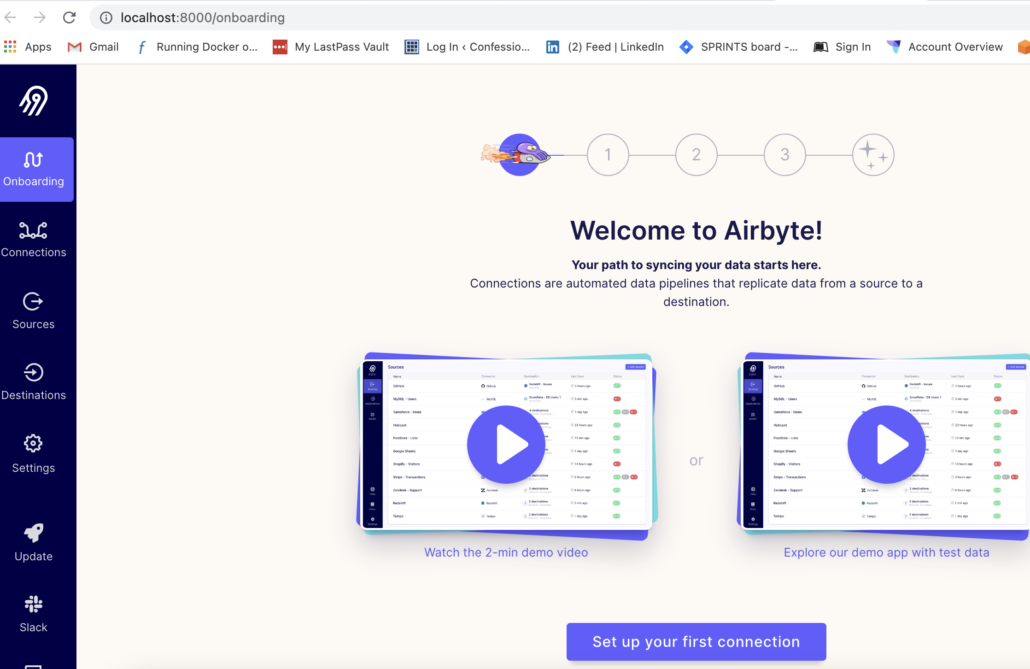
One thing of note that comes to my mind right away is that Airbyte appears to be very UI-driven. For some Data Engineers and orgs, the option that everything is code-driven, infrastructure as code, so It can be committed to source control is key. It probably depends on your organization as to how hard this rule is, for me, it’s hard to imagine storing connections and such to data sources in just a UI, and not be able to put something into Git source control.
I mean I know nothing about Airbyte so maybe I will get there.
Setting up a simple File source, HTTPS or s3.
Now, I do have to say, out of the box it does seem like the list of dropdown options for Sources and Connectors is very big. Meaning there is a lot of built-in ready data sources, which is always nice.
The first problem I ran into was that I could not set up a simple File source. I got the below error, something about being unable to fetch connector.
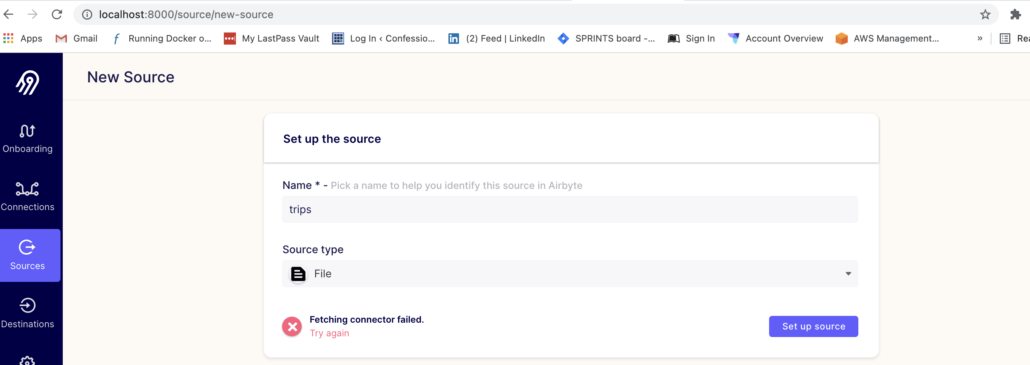
When I click on set up source it just goes to a Blank screen.
The second time was a charm, finally, I got something to pop.
I setup a HTTP file connection to a CSV file I had in my GitHub account. each/theos.io/blob/main/Gutenberg/ingest_file/Gutenburg%20files.csv / https://github.com/danielbeach/theos.io/blob/3c8d64555c9137e4edeb119356c0277b00f47eae/Gutenberg/ingest_file/Gutenburg%20files.csv
For the life of me, I couldn’t get the connection to take. I also tried to get a s3 connection to work and got the same error.
2021-10-13 21:21:11 INFO () TemporalAttemptExecution(get):94 - Executing worker wrapper. Airbyte version: 0.30.20-alpha
2021-10-13 21:21:12 INFO () TemporalAttemptExecution(lambda$getWorkerThread$1):148 - Completing future exceptionally...
io.airbyte.workers.WorkerException: Error while getting checking connection.
at io.airbyte.workers.DefaultCheckConnectionWorker.run(DefaultCheckConnectionWorker.java:80) ~[io.airbyte-airbyte-workers-0.30.20-alpha.jar:?]
at io.airbyte.workers.DefaultCheckConnectionWorker.run(DefaultCheckConnectionWorker.java:27) ~[io.airbyte-airbyte-workers-0.30.20-alpha.jar:?]
at io.airbyte.workers.temporal.TemporalAttemptExecution.lambda$getWorkerThread$1(TemporalAttemptExecution.java:145) ~[io.airbyte-airbyte-workers-0.30.20-alpha.jar:?]
at java.lang.Thread.run(Thread.java:832) [?:?]
Caused by: java.lang.RuntimeException: java.io.IOException: Cannot run program "/tmp/scripts1800018584036152158/image_exists.sh": error=0, Failed to exec spawn helper: pid: 146, exit value: 1
at io.airbyte.workers.process.DockerProcessFactory.checkImageExists(DockerProcessFactory.java:155) ~[io.airbyte-airbyte-workers-0.30.20-alpha.jar:?]
at io.airbyte.workers.process.DockerProcessFAt this point, I’m not really sure what I can do to test this stuff out.
Using my imagination to explore Airbyte.
Since I cannot seem to get Airbyte working locally or otherwise, I’m going to use the docs on their website to understand what Transformations might look like with Airbyte.
Reading about Transformations in Airbyte I’ve come to some conclusions, wrong or otherwise.
- Airbyte is made to pull data from Source and put it into a Destination.
- You can use straight SQL or DBT to actually transform the data.
Per Airbyte the main thrust of what it provides is ….. “At its core, Airbyte is geared to handle the EL (Extract Load) steps of an ELT process.”
Also, it says that what happens under the hood is “producing a table in the destination with a JSON blob column.”
So, since you can’t really use JSON data for most Data Engineering and analytical workloads, you absolutely will have to have some sort of Transformation running if you push and pull data with Airbyte.
Can I get the code for a transformation?
Apparently, the SQL-type DBT transformation files are output into a folder, so you could technically browse to them and get them. This would enable you to add them to source control, although this process seems like it would most likely fall apart very quickly.
My Musings on Airbyte
I wish I could have gotten Airbyte to work a little better so I could have played around with it more. But, at least now I understand what Airbyte is, and what it’s trying to do.
It’s attempting to make the pulling of data from various data sources and pushing them to various sinks, easy and done through a nice UI.
From all appearances, it’s tightly coupled to SQL and DBT workflows and pipelines. If you don’t have workloads that currently use DBT or fit well into that model, this probably isn’t the tool for you.
The other big question I have is hosting. You are probably going to have to pay to host this platform somewhere, based on my experience maybe if you are a Kubernetes wizard with nothing else to do you could make your own deployment, but that’s probably way more hassle than it’s worth.
Honestly, I’m asking myself when would someone use Airbyte and when wouldn’t they as a Data Engineer?
- use Airbyte if your already extensivly using DBT.
- use Airbyte if your into GUI work and transformations, and their isn’t a lot of complexity in your pipelines.
- Orgs that are into code as infrastructure with highly complex pipelines will probably not find any feature worth it for the added technology and complexity.
If I was working in a Data Engineering position that had a high amount of external datasets located in Salesforce, s3, API’s blah blah, and needed to pull that data with some moderate transformations and land them in my Snowflake data warehouse …. would I use Airbyte?
Maybe. Maybe not. I personally would be worried about hosting such a solution myself, and if I had to pay someone else to host it, I’m not sure if that would be worth it or not. With the rise of tools like Airflow and their many and ever-expanding community-supplied Operators, maybe I would just go that route?
I mean if I really just wanted to write a bunch of DBT transforms and automate them … I could probably find a simple way to do that.