Old Dog Learn New Tricks? Starburst (Trino) Galaxy and other thoughts.

Sometimes I think Data Engineering is the same as it was 10+ years ago when I started doing it, and sometimes I think everything has changed. It’s probably both. In some ways, the underlying concepts have not moved an inch, some certain truths and axioms still rule over us all like some distant landlord, requiring us to pay the piper at a moment’s notice. Still, with all those things that haven’t changed, the size, velocity, and types of data have exploded. Data sources have run wild, multiple cloud providers, and a plethora of tooling.
So yes, maybe in a lot of ways Data Engineering has changed, or at least how we do something is a new and wild frontier, with beasts around every corner waiting to devour us in our ignorance. Never mind the wild groups of zealots roaming around seeking converts to their cause and spitting on those unwilling to bend.
Probably like many of you, I’ve had a healthy skepticism of all things new, at least until they have proved themselves out over some time. This is both a good and a bad habit. It can protect you from undo harm and foolishness, but can also be lost opportunity when you pass over the diamond in the rough. I for one, think that if something is worth its weight in salt, it is usually clear, and its obvious value can be discerned quite readily.
The Problem.
Lest ye be under any other impression, no this is not a sponsored blog post, nor have I been paid to write this. Simply the confessions of a data guy.
It’s not often I review SaaS products in my musings and traveling through the Data Engineering world, usually, I have a specific reason to do so. Maybe something gets popular, people are talking about it on Reddit, and I take a gander at something new. Today I’m going to talk about Starburst Galaxy (Trino) because I want to talk about a particular problem at a higher level.
I want to step back for a minute and take a survey of the current Data Landscape … on the ground … in real life. There is a particular problem I’ve encountered and observed, and it bleeds into why I want to talk about Starburst and Trino.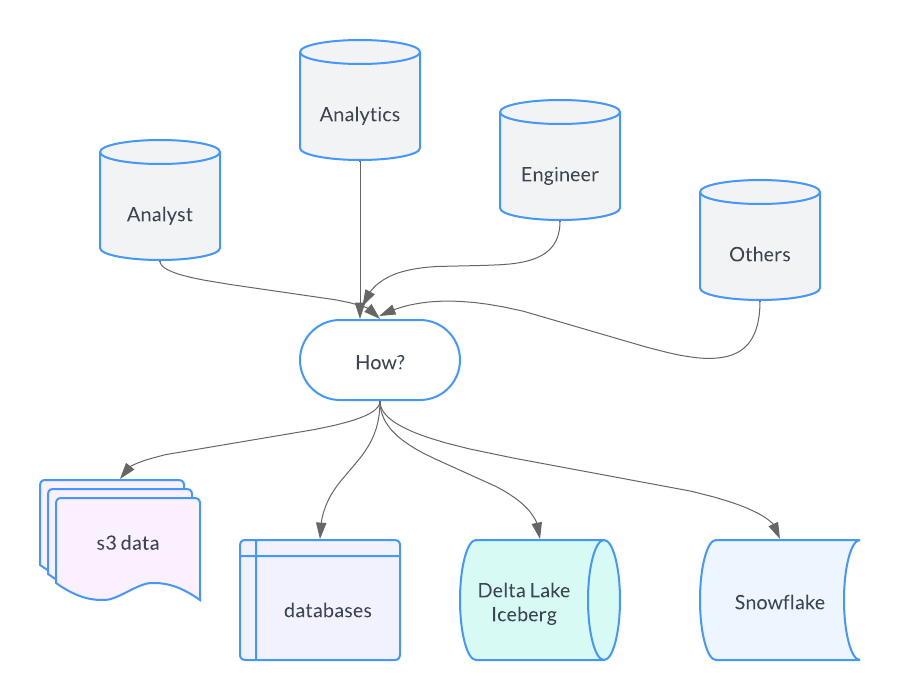
This simple diagram explains more or less, the problem I’ve seen over the years. Sure, in the beginning, it might have been SQLServer, some files stored somewhere, another Postgres database, or maybe some MongoDB. Today it’s the same thing with different technology. Data Lakes in Databricks, Snowflake, Redshift, Postgres, s3, and the list goes on.
What I’m trying to say is that it’s extremely common for data to be dispersed in many different places, and it’s also true that a wide variety of data persons constantly need to analyze data very often, and the final challenge, at scale!
The other big that has changed over the years is the type and amount of Data Workers.
Many years ago it was pretty much two people munging around on data. Probably a Business Intelligence Engineer and a Data Developer, sometimes fighting, other times best friends, solving the world’s data problems one day at a time. Then things changed.
Data Engineers, Data Analysts, Business Analysts, Analytics Engineers, and even the C-suit people want to write SQL and mung data. So yes, times have changed.
Starburst Galaxy (Trino)

This finally brings me to Trino and Starburst Galaxy. What is it?
The Modern Data Lake is here.
A single platform to help you activate all the data in and around your data lake.– Starburst
In all fairness, this is a problem. Sort of. Sure, you could ingest everything into Snowflake or Redshift. But that ain’t going to happen. Neither the time, resources, or gumption exists to do this at any organization of size. It just isn’t feasible. Well, what are the other options?
I guess you could read everything with Spark and crunch it on Databricks with Spark. The truth is that that would be a lot of engineering work, and the output would still be out of reach from the average data user who isn’t a Data Engineer.
What does Starburst do from my point of view? Sure you can look at the marketing material below.
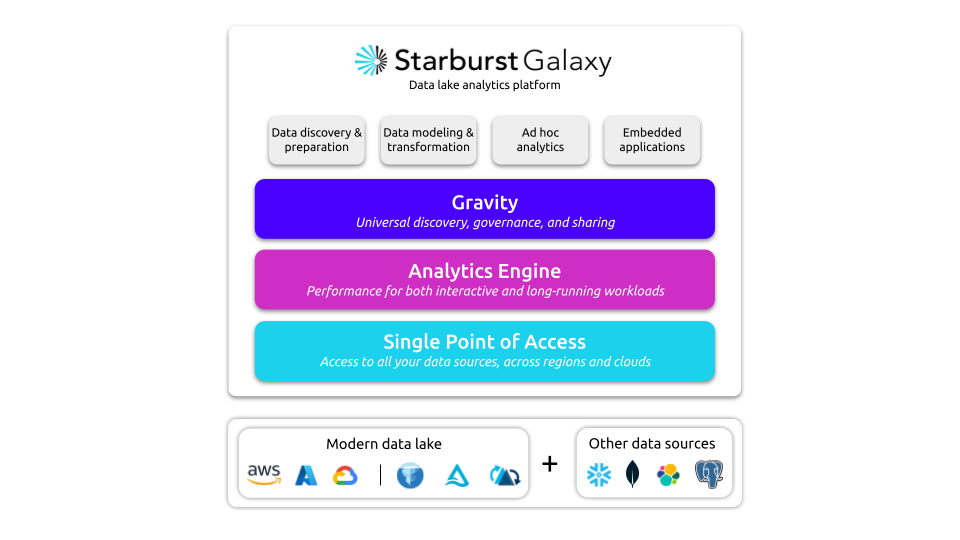
But again, I think the most important part to me as an average Data Engineer who’s been around the block a few times, is the fact that Starburst provides …
- A single place to connect disparate and wide-ranging data sources.
- The ability to simply use SQL to interact with all this data.
- To do the above at scale!
I guess maybe you were expecting fireworks, a parade, much trumpeting, and fanfare. Sorry. Keeping it simple around here. Yes, there are many nice and in-depth features available from Starburst, like any other tech and SaaS company, but at the core, I think you need a more compelling reason to give something your time and attention, other than fancy x, y, z feature, valuable though it may be.
It needs to fit. Have a purpose, have a reason to exist, and be used.
This isn’t really a technical blog post, showing you how to use Trino and Starburst, maybe later? These are just thoughts about the changing industry over the years, the continued rise of data into the upper echelons of every business, and how the data problems have gotten bigger and more dispersed.
This is simply one possible answer to the initial flow chart I showed you. Various data sources are scattered, gobs of data, and the need to throw serious compute and some SQL to bring together everything into a sweet little package that can be sliced and diced to the very whim and desire of the product manager, or whoever it may be.
Sure, I’ve seen a lot of tools capable of doing this, IF you decide to use them as the central source, ingest everything into their format on their platform. But that just isn’t a feasible solution. You need something like Starburst, plug and play, at scale, across data sources, with SQL.
Simple, easy, efficient, delivering value without doing mental backflips to justify a problem that doesn’t exist.
Maybe look for more content in the future on the nuts and bolts of Starburst Galaxy, and how they are solving real data problems at scale, with simplicity and SQL.
Will this work as a delta table querying tool instead of bricks? Will it be faster cheaper?
hi Pablo – I’m a developer advocate for Starburst. Yes, we do work as a Delta table querying tool! Here’s example of one of our customers talking about their experience. Let me know if you have any questions.
https://www.starburst.io/resources/building-a-data-analytics-platform-with-a-lakehouse-at-7bridges-datanova-2023/