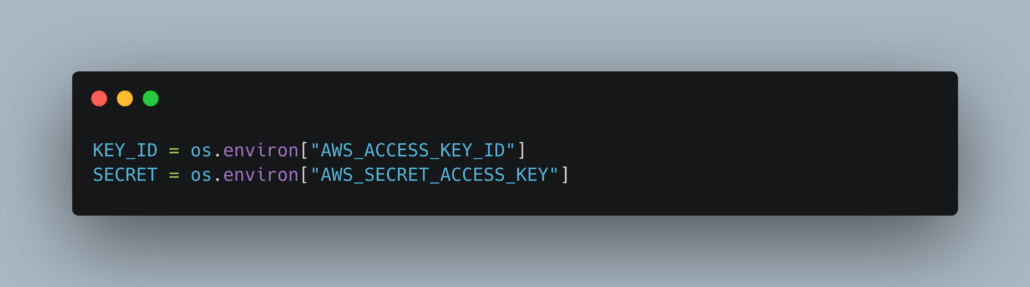
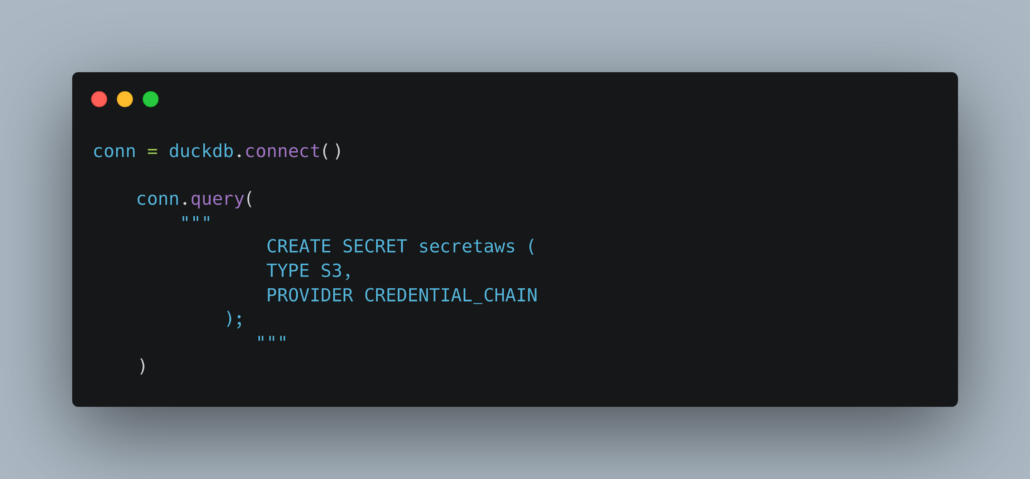
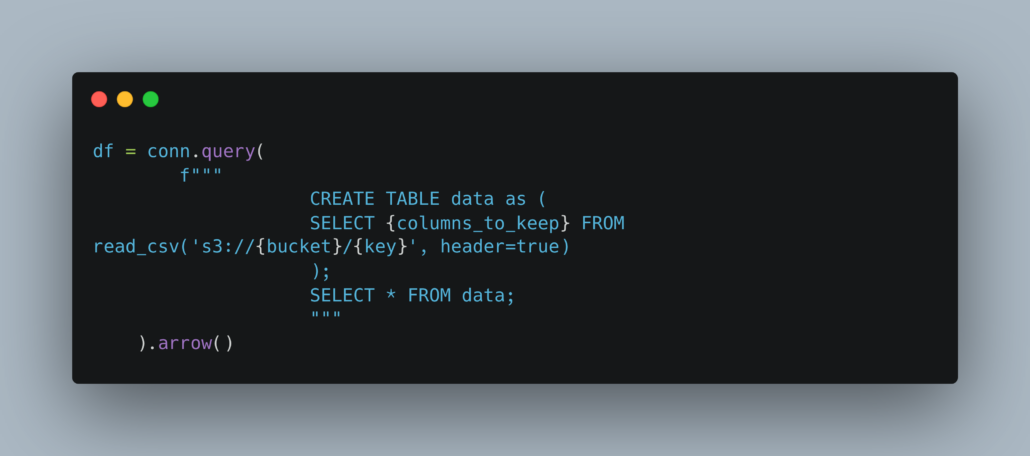
It’s an interesting time to be in software and data; the world of generative AI is changing the landscape beneath our feet. I don’t see this as a bad thing for software folk, but as an opportunity to learn new technologies and BUILD / UNDERSTAND the technologies used in an LLM and AI context.
You can’t expect an LLM trained two years ago to be up-to-date on what the new and best approaches are for X, Y, Z tech.
Sure, they can do a decent job given enough context, Agents, etc, but if you’re working on the cutting edge of AI and LLM infrastructure, you are going to have to be active in the community and reading about what others are doing, who’s releasing new tools, and what those tools do.
Don’t forget, there is the whole architectural and systems design piece. One part of the LLM and AI infrastructure is vector and embedding representations.