AWS Lambda MicroVMs: The Compute Nobody Asked For?
When AWS announced Lambda MicroVMs, I was genuinely excited. After years of incremental services and endless feature releases, it finally looked like AWS had built something that filled the awkward gap between Lambda and EC2. On paper, it sounded perfect. You get VM-level isolation, more memory, persistent state, and startup times measured in milliseconds, all without managing infrastructure. If you’ve ever wished Lambda had fewer limitations or EC2 required less babysitting, this looked like the answer.
Then I actually built something with it. Needless to say, I felt betrayed, lied to, and taken for a ride. Not a happy camper am I.

The idea is compelling enough. Instead of running untrusted code within shared infrastructure, each user or workload runs its own isolated Firecracker virtual machine that can remain active for hours and resume where it left off. That makes a lot of sense for AI agents, coding assistants, and other workloads that need more than a traditional Lambda can offer. AWS is clearly betting that this is where the next generation of applications is headed.
I’ve loved AWS Lambda and EC2 for a long time. They each give you exactly what you need for different use cases. I’ve used both in production for years.
Lambda
- fast
- light weight
- conceptual easy
- high concurrency
- small memory footprint (10GB max)
- 15-minute runtime
EC2
- 600+ options
- slow
- mid-level complexity
- long running
- flexible
- customizable
The problem is that for MicroVM, the developer experience falls apart remarkably fast. A Lambda function is wonderfully simple; write a handler, deploy it, wire up a trigger, and move on with your life. A MicroVM is an HTTP server packaged inside a Docker image, uploaded to S3, converted into a MicroVM image, started, authenticated, triggered over HTTPS, monitored, suspended, resumed, and eventually terminated. Somewhere along the way, you realize you’ve recreated a tiny application platform just to run a single workload.
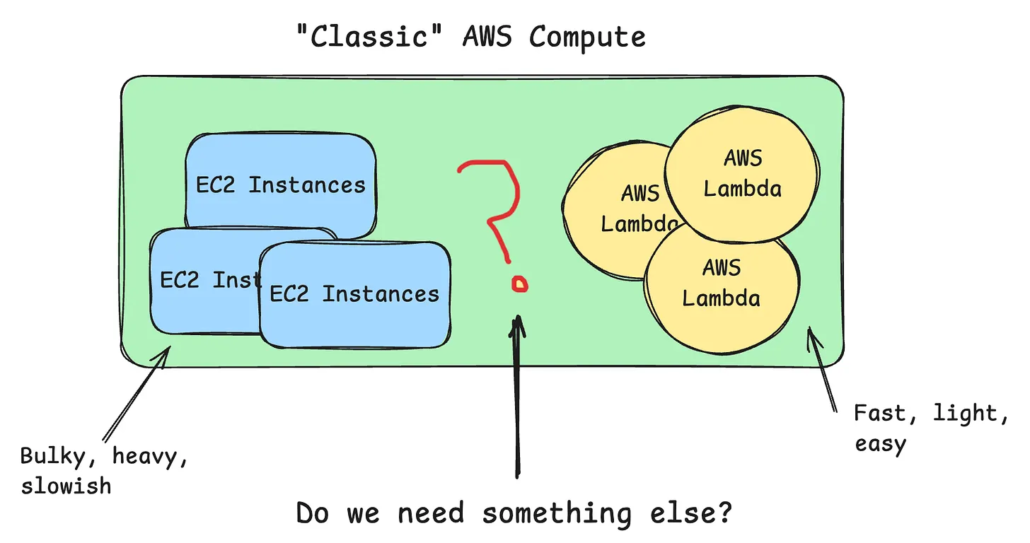
After spending time with it, I came away thinking Lambda MicroVMs solve a very real problem for a very small audience. If you’re building secure AI execution environments, they make a lot of sense. For the other ninety-nine percent of engineers, there’s an awful lot of complexity in exchange for capabilities you’ll probably never need. Most workloads are still better served by Lambda if they’re small, or EC2, ECS, or Fargate if they are not.
Check out my complete GitHub repo showing how to use and deploy MicroVMs. It’s a beast.
The concepts of AWS Lambda MicroVMs are a little overwhelming and strange. It’s like EC2 and Lambda had a baby behind the barn, and what came out was MicroVMs.
- VM isolation: Every workload runs inside its own Firecracker virtual machine.
- Serverless: AWS manages the infrastructure, scaling, and lifecycle.
- Persistent state: A MicroVM can suspend and resume with its memory intact for up to eight hours.
- Long-running workloads: Unlike Lambda, they are designed to stay alive rather than execute a single short request.
- HTTP-based: Applications run as HTTP servers and are accessed through dedicated HTTPS endpoints instead of Lambda event handlers.
- Docker deployment: Applications are packaged as Docker images, which AWS converts into MicroVM images before execution.
- Lifecycle management: MicroVMs are created, started, suspended, resumed, and terminated rather than simply invoked.
AWS deserves credit for trying something different, and the underlying technology is genuinely impressive. I just think they combined the complexity of EC2 with the programming model of an HTTP service while quietly leaving behind the elegance that made Lambda so successful in the first place. Maybe I’ll change my mind after another year of using them, but for now I’ll happily keep reaching for plain old Lambda until AWS gives me a much better reason not to.