The Wild West of Parallel Computing – Review of Bodo.ai

It truly is the Wild West of parallel computing these days. It seems that big data has brought out an onslaught of companies trying to either take advantage of making it easier to use any number of big data platforms or making up their own. Most of them usually take shots at tools like Spark and Dask, probably two of the more well-known big data engines. Of course with Python’s rise, especially in Data Science and ML, many of these tools target that audience.
One such newcomer is Bodo.ai, and I’ve seen them pop up on places like r/dataengineering. Fortunately, they have a free community edition, so let’s kick the tires and see what’s going on.
Bodo.ai – at a glance.
What is bodo.ai? It’s hard to get a concrete statement on their website. Basically, they say …
- use plain ole’ Python
- zillion times faster then “alternatives”
- works at “massive” scale.
It appears the target person(s) are those working in the AI and ML space.
While the community version is paired down (apparently 4 core max on your local machine), we can get a good idea of what is going on. Let’s run some sample workloads on a laptop and compare it to plain old Pandas. See which one is easier to use.
Install bodo.ai community version.
The first thing to note is you can only install the Python package using Conda, with no pip option. I’ve used packages like this before, and I sorta get it, but it still leaves a bitter taste in my mouth. If you’re going to be a Python tool … get on the pip install train. Everyone else is on it, the more things that set you apart sometimes the worse things get.
I’ve spent my fair share of time working on Data Science projects that heavily used Conda, trust me, it isn’t all rainbows and unicorns.
I digress. Install.
Install conda if you don’t have it. Then bodo.
conda create -n Bodo python
conda activate Bodo
conda install bodo -c bodo.ai -c conda-forgeHappily, all went according to plan. Easy to set up and install.
Using bodo.ai
So using bodo.ai is apparently as simple as adding @bodo.jit into your code.
Sounds like Black Magic to me, something out of Mordor. Let’s try it.
We are going to be working on a measly 676.7 MB of data. Open source bike trip data from Divvy.
Let’s write some Pandas code to mess with this data and test a few different scenarios, with bodo.ai and without. Of course with economies of scale, I might see more of a difference with a large dataset, but I should see something.
What’s a typical DS workflow … well unfortunately those Data Scientists love that ol’ Pandas too much. They read files and smash them together. Let’s do the same. Count the number of bike rides per starting station name. See what locations are the most popular.
import bodo
import pandas as pd
from datetime import datetime
from glob import glob
def gather_files(data_loc: str = 'data/*.csv') -> list:
files = glob(data_loc)
return files
def read_data_files(files: list) -> list:
dfs = []
for filename in files:
df = pd.read_csv(filename, index_col=None, header=0)
dfs.append(df)
return dfs
def one_big_frame(dfs: list) -> pd.DataFrame:
dframe = pd.concat(dfs, axis=0, ignore_index=True)
dfs = None
return dframe
def calc_metrics(df: pd.DataFrame) -> None:
results = df.groupby(['start_station_name']).count()
print(results)
def main():
t1 = datetime.now()
fs = gather_files()
dfs = read_data_files(fs)
df = one_big_frame(dfs)
calc_metrics(df)
t2 = datetime.now()
x = t2-t1
print(f"it took {x}")
if __name__ == '__main__':
main()
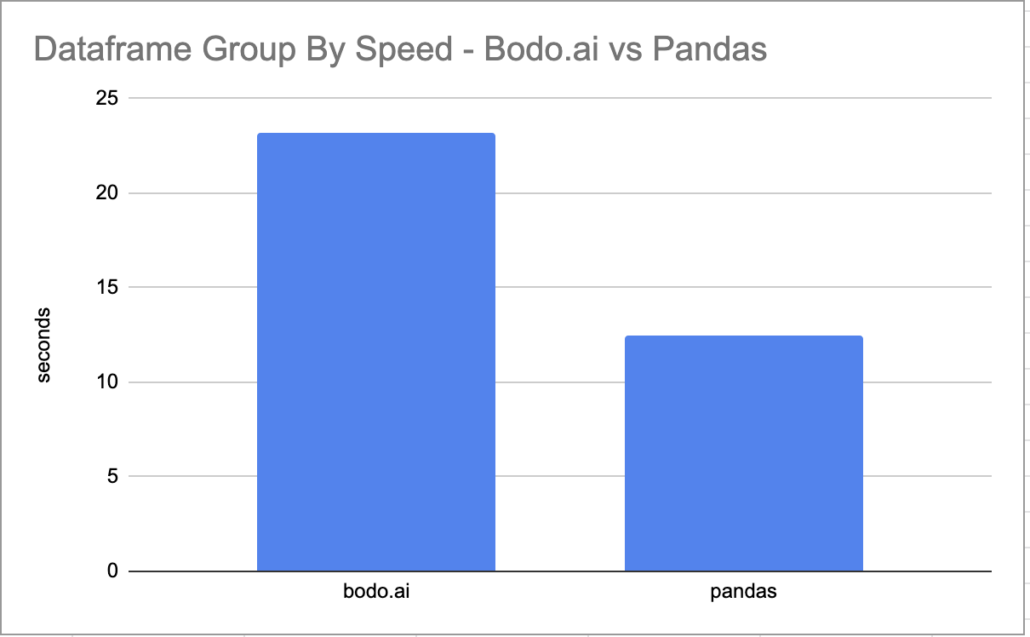
Not bad.
Woodlawn Ave & Lake Park Ave 1288 1288 1288 1288 1288 ... 1288 1288 1283 1283 1288
Yates Blvd & 75th St 182 182 182 182 182 ... 182 182 177 177 182
Yates Blvd & 93rd St 78 78 78 78 78 ... 78 78 78 78 78
[747 rows x 12 columns]
it took 0:00:12.436477
Well, let’s throw that magic @bodo.jit onto our code. See what happens.
@bodo.jit
def read_data_files(files: list) -> list:
dfs = []
for filename in files:
df = pd.read_csv(filename, index_col=None, header=0)
dfs.append(df)
return dfs
@bodo.jit
def one_big_frame(dfs: list) -> pd.DataFrame:
dframe = pd.concat(dfs, axis=0, ignore_index=True)
dfs = None
return dframe
@bodo.jit
def calc_metrics(df: pd.DataFrame) -> None:
results = df.groupby(['start_station_name']).count()
print(results)Bugger. It’s never that easy, is it?
raise error
bodo.utils.typing.BodoError: pd.read_csv() requires explicit type annotation using 'dtype' if filename is not constantI thought this was supposed to be plug-and-play. Seriously? Of course the file names are not the same. Well fine then. Let’s print the Pandas dtypes and add that to call then.
df.dtypes
dtypes = {
'ride_id' : 'object',
'rideable_type' : 'object',
'started_at' : 'object',
'ended_at' : 'object',
'start_station_name' : 'object',
'start_station_id' : 'object',
'end_station_name' : 'object',
'end_station_id' : 'object',
'start_lat' : 'float64',
'start_lng' : 'float64',
'end_lat' : 'float64',
'end_lng' : 'float64',
'member_casual' : 'object'
}def read_data_files(files: list) -> list:
dfs = []
for filename in files:
df = pd.read_csv(filename, index_col=None, header=0, dtype=dtypes)
dfs.append(df)
return dfsLet’s try this again.
Bugger again.
raise error
bodo.utils.typing.BodoError: pd.read_csv() requires explicit type annotation using 'dtype' if filename is not constantWhy do I get the same error? I’m passing the dtype into that pd.read_csv() just like it’s asking. Googling this error brings up a whole lotta nothing. Digging through their documentation I find exactly what I’m looking for. You can see in their documentation they are using numpy np data types in their dictionaries.

Let’s try that.
dtypes = {
'ride_id' : np.object_,
'rideable_type' : np.object_,
'started_at' : np.object_,
'ended_at' : np.object_,
'start_station_name' : np.object_,
'start_station_id' : np.object_,
'end_station_name' : np.object_,
'end_station_id' : np.object_,
'start_lat' : np.float64,
'start_lng' : np.float64,
'end_lat' : np.float64,
'end_lng' : np.float64,
'member_casual' : np.object_
}I tried every single dtype I could, and still to no avail. Bodo wouldn’t stop throwing the same error. Obviously, it wasn’t liking something.
bodo.utils.typing.BodoError: pd.read_csv() requires explicit type annotation using 'dtype' if filename is not constant
Even changing the pd.read_csv() to default to everything to strings doesn’t work!!
df = pd.read_csv(filename, index_col=None, header=0, dtype=str)This gives me a clue that the error is probably somewhat misleading. That made me wonder if it has something to do with being unable to figure out column names?
column_names = ["ride_id", "rideable_type", "started_at",
"ended_at", "start_station_name", "start_station_id",
"end_station_name", "end_station_id", "start_lat",
"start_lng", "end_lat", "end_lng", "member_casual"]
df = pd.read_csv(filename, index_col=None, names=column_names, dtype=str)This leads to a whole new bodo.ai error.
lgek.run()
File "bodo/transforms/untyped_pass.pyx", line 122, in bodo.transforms.untyped_pass.UntypedPass.run
File "bodo/transforms/untyped_pass.pyx", line 186, in bodo.transforms.untyped_pass.UntypedPass._run_assign
File "bodo/transforms/untyped_pass.pyx", line 700, in bodo.transforms.untyped_pass.UntypedPass._run_call
File "bodo/transforms/untyped_pass.pyx", line 1326, in bodo.transforms.untyped_pass.UntypedPass._handle_pd_read_csv
ValueError: None is not in list
At this point, I’m losing patience. This is supposed to be easy, your normal Python code running easily and quickly. I’m going to make it easy on bodo.ai.
I’m just going to use my current code without bodo.ai to write a single CSV file and see if I can get that work.
df.to_csv('all_in_one.csv')Now, this better be fast since I’m just reading a single CSV file.
df = pd.read_csv('all_in_one.csv')
Well…. surprise surprise. Way slower.
Sayre & Diversey 7 7 7 7 7 7 ... 4 7 7 7 7 7
[748 rows x 13 columns]
it took 0:00:23.155191Even after only having to read one file, while the normal Pandas code had to read multiple and concat() them all together. But bodo.ai with the advantage of a single file and no concat takes double the time?
I’m sure I will be chastened by someone with everything I did wrong, but remember, I’m just approaching it fresh. As anyone else would be who would be researching a tool to see how it fairs and works in real life. It is what it is.