Httpx vs Requests in Python. Performance and other Musings.

Someone recently brought up the new kid on the block, the httpx python package for http work of course. I mean the pypi package
requests has been the de-facto standard forever. Can it really be overthrown? Is this a classic case of “oh how the mighty have fallen”? I want to explore what the new httpx package has to offer, but mostly just …. which one is faster. That is what data engineers really care about.
Below is an affiliate link, I receive compensation if you buy 🙂
Starting with the simple http get call.
Ok, so where do we start? On the surface both packages look to implement the basics fairly the same. The httpx package claims to be “a high performance asynchronous client…”. Well, we figured out last time async, especially in HTTP is pretty much a silly and way slower idea then other options. My guess would be httpx probably implemented most common function similar to requests, knowing it would make a easier transition for most people.
Writing code as a data engineer I usually want things to be simple and fast. New isn’t always better if it offers nothing special besides a new set of errors.
# HTTPX
r = httpx.get('https://www.confessionsofadataguy.com’)
print(r.content)
# REQUESTS
r = requests.get('https://api.github.com/events')
print(r.content)I figured the first thing to do is test is just test the performance of the classic .get() call in both packages. This is what most people are doing 90% of the time. Let’s make 50 calls to this website, seeing how long each call takes. Yes, I know that some of that is server side response, but I figure if we sleep between each call, try it at 50 gets, then 100, we should get some idea of performance in the same or different between requests and httpx.
Performance on httpx get() calls.
import httpx
from timeit import default_timer as timer
from time import sleep
# get web page 50 times, measure time it took, sleep between calls
def make_httpx_call(url: str):
t1 = timer()
r = httpx.get(url)
sleep(.1)
t2 = timer()
secs = t2 - t1
return str(secs)
def main():
url_list = ['https://www.confessionsofadataguy.com'] * 50
father_time = map(make_httpx_call, url_list)
for timerson in father_time:
print(timerson)
if __name__ == '__main__':
main()
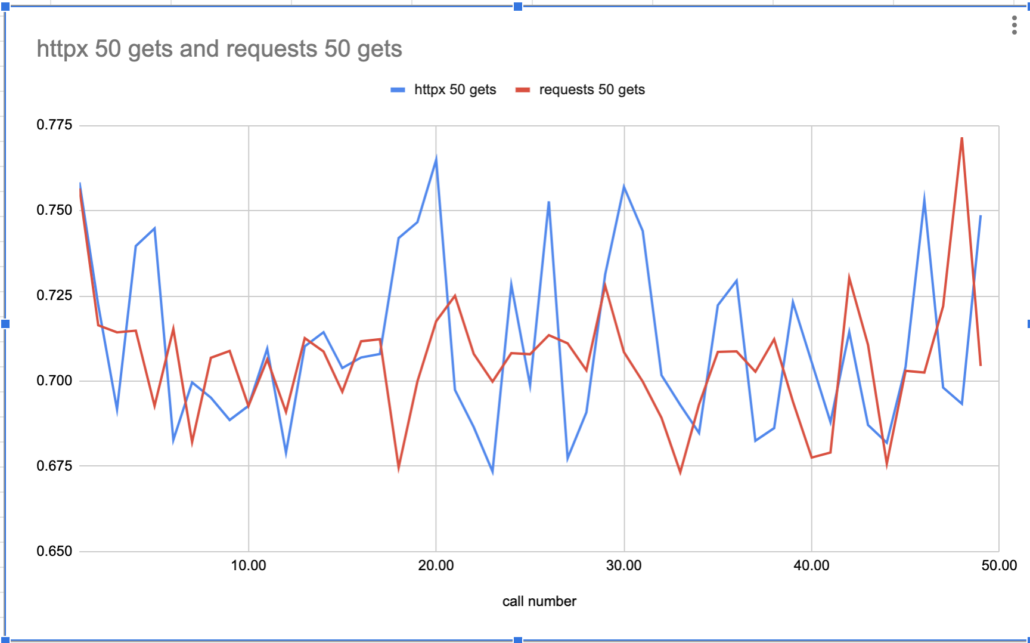
Strangely enough based on appearances, httpx seems to be a little more all over the place than requests. I see nothing about “high performance in this chart. Just incase let’s do it again with 100 calls, see if anything changes.
The requests package code looks the same, of course.
import requests
from timeit import default_timer as timer
from time import sleep
# get web page 50 times, measure time it took, sleep between calls
def make_requests_call(url: str):
t1 = timer()
r = requests.get(url)
sleep(.1)
t2 = timer()
secs = t2 - t1
return str(secs)
def main():
url_list = ['https://www.confessionsofadataguy.com'] * 50
father_time = map(make_requests_call, url_list)
for timerson in father_time:
print(timerson)
if __name__ == '__main__':
main()
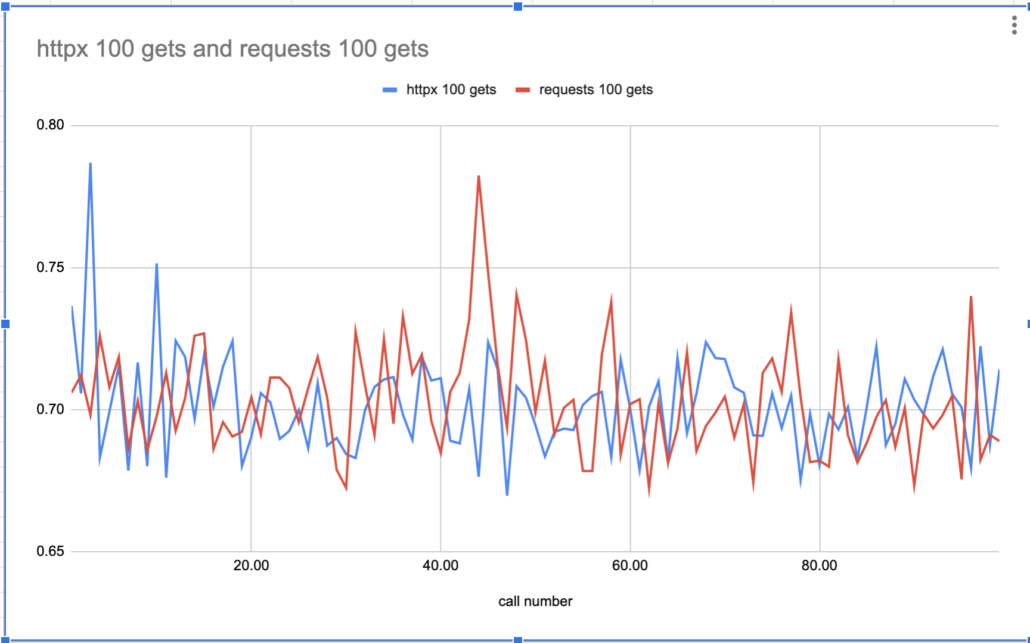
Pretty much the same story. It was probably too much to hope that a simple HTTP get call would actually get significantly faster between Python packages. But, never fear, maybe we can find something else special about httpx. They do call out a few features on their homepage like “Ability to make requests directly to WSGI applications or ASGI applications.” and “Standard synchronous interface, but with async support if you need it.” , neither of which I care about.
I will only give a slight node to the async and sync inside one package. It’s sorta nice.
Some astute Python engineer might notice I wasn’t using a Client session for either httpx or requests when making calls to the same url over and over again. Aka making different tcp connections for each call. Just to be fair I will run the tests again using a Client session in each case to see if anything changes.
import httpx
from timeit import default_timer as timer
from time import sleep
def main():
url_list = ['https://www.confessionsofadataguy.com'] * 100
father_time = []
with httpx.Client() as client:
for url in url_list:
t1 = timer()
r = client.get(url)
sleep(.1)
t2 = timer()
secs = t2 - t1
father_time.append(secs)
for timerson in father_time:
print(timerson)
if __name__ == '__main__':
main()
If you read through both the quick-starts for requests and httpx, the pretty much mirror each other.
Apparently using httpx.Client() and requests.Session() doesn’t make any difference, both are pretty much the same again.
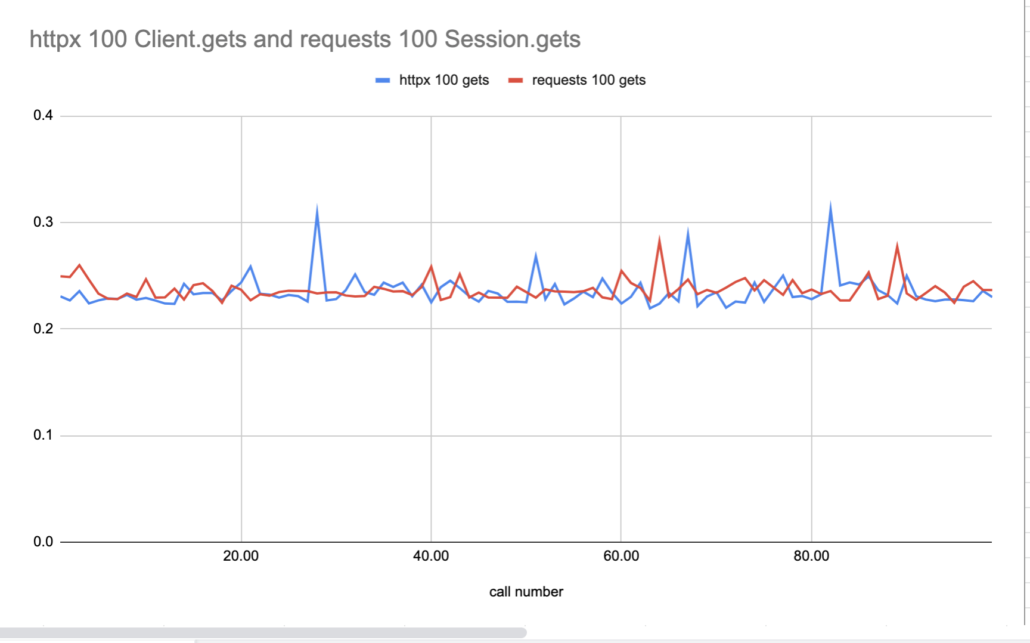
Conclusion
After reading the rest of the httpx documentation I didn’t really see the point of doing more work exploring it’s features. I mentioned above the only “nice” feature I can appreciate about this new http package is the sync and async support in one. Calling WSGI apps directly seems like something I will never care about.
It does seem like someone took their time to create this package, the documentation is nice, but I just don’t really see the point of switching. One could always test the async performance of httpx vs aiohttp, but I think I will just stick with the tried and true requests.
I think what you may be missing is that, with async, if you need to harvest 100 URLs you can comfortably send off the 100 requests concurrently, then process the data as it comes in; rather than serializing it all as you need to do in a sync approach. I often want to consume many feeds, not just one, so this might be a helpful speedup for my own apps!
Thanks Alex, I’ve found async in Python to be ok, but its usually more complex to implement and slower then using concurrent.futures ProcessPools with ThreadPools for doing multiple HTTP calls. I do like the fact that httpx comes with async and sync in one package. That’s whats requests is missing.