
Agent Bricks and the Commoditization of AI Systems
I recently spent some time poking around Agent Bricks from Databricks, and it’s a pretty good representation of where we are in the AI cycle right now. Whether you’re skeptical or all-in, it’s hard to ignore the fact that agent-based systems are no longer theoretical. They’re here, and they’re being used to automate real workflows.
I’m not particularly interested in the hype, though. What matters is whether something useful can actually be built. We’ve reached a point where building AI systems is no longer technically difficult. Tools like Claude can generate large portions of the code, frameworks are maturing quickly, and platforms like Databricks are packaging everything into approachable interfaces. The barrier to entry has dropped significantly. The real question now is not whether you can build an agent, but whether you can build one that delivers value.
This is where Agent Bricks fits in. Databricks has taken a familiar approach, one they used successfully with Spark, and applied it to AI systems. Instead of requiring teams to stitch together infrastructure, they provide prebuilt agent categories that handle common use cases. You can build document parsers, information extraction systems, knowledge assistants, AI-powered BI tools, and even multi-agent workflows directly from the UI.

There’s nothing fundamentally new about these capabilities. What’s new is how accessible they are. The companies that will win in this space are those that simplify infrastructure and make these systems easy to build and operate. That’s always been Databricks’ strength, and Agent Bricks is a continuation of that strategy.
Document Parsing
- Parse and visualize document structure with AI.
Information Extraction
- Extract key information and insights into structured JSON.
Knowledge Assistant
- Turn your docs into an expert AI Chatbot.
AI/BI Genie
- Turn your tables into an expert AI Chatbot.
Supervisor Agent
- Design a AI system with Genie, agents, tools.
Custom LLM
- Specialize an LLM to perform custom text tasks.
Code Your Own Agent
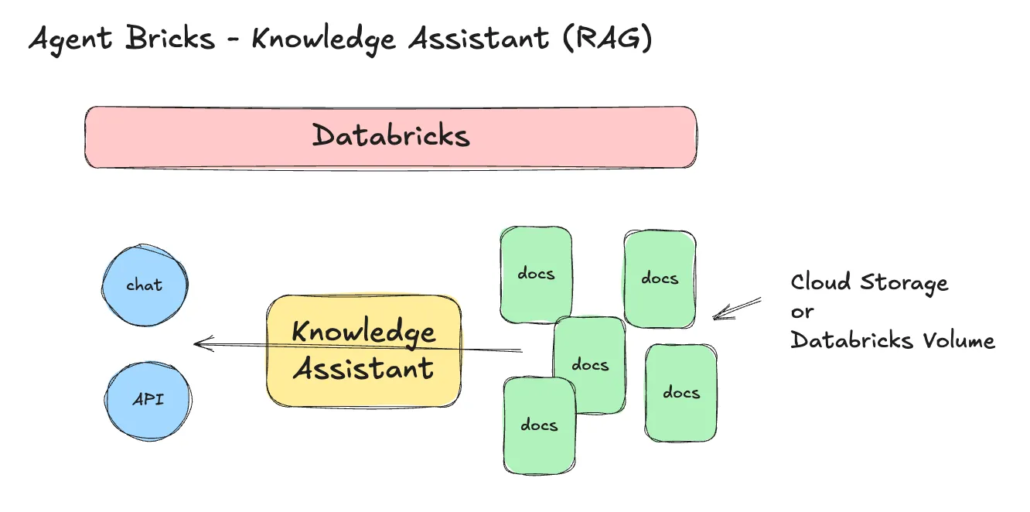
- Build with OOS libraries and Agent Frameworks. To make this concrete, I walked through building a Knowledge Assistant using some of my own blog content. At a high level, what you’re really building is a managed RAG system, but most of the complexity is hidden. You upload documents into a Databricks Volume or cloud storage, create the assistant, point it at your data, and let the system handle indexing and retrieval. From a user perspective, it’s just a few clicks.
That simplicity is both the appeal and the point. A few years ago, building a RAG system required stitching together multiple components—embedding pipelines, vector stores, APIs, and custom orchestration logic. Now, much of that is handled for you. The system abstracts away the hard parts so you can focus on the outcome.
Screen Recording 2026-02-22 at 8.03.33 AM
That said, the ease of building these systems can be misleading. A Knowledge Assistant is only as good as the data behind it. Most organizations have knowledge scattered across documents, systems, and people’s heads. Simply pointing an agent at a folder of PDFs is not enough. There’s real work involved in collecting, organizing, and curating that knowledge so it can be used effectively.
Once that groundwork is done, the rest is straightforward. You create the assistant, connect it to your data source, and let it sync. After that, you can interact with it through a chat interface or programmatically via an endpoint. It can be embedded into applications or combined with other agents to form larger systems. The mechanics are simple, but the usefulness depends entirely on the quality of the inputs.
This is a pattern we’ve seen before in data engineering. As tools mature, complexity gets pushed down into the platform, and what used to require deep expertise becomes accessible to a much broader audience. AI systems are following the same trajectory. What was once complex and experimental is quickly becoming standardized and commoditized.
That doesn’t mean the underlying problems disappear. If anything, they become more important. Behind every “simple” agent is a stack of infrastructure concerns: how documents are stored and managed, how embeddings are generated, how models are served, how systems are monitored, and how costs are controlled. These are still engineering problems, even if the platform hides them.
The opportunity for data engineers is not going away. If anything, it’s expanding. The role is shifting toward building and managing the systems that enable these agentic workflows, rather than implementing everything from scratch. Understanding the trade-offs between ease of use and flexibility, and knowing when to rely on platform abstractions versus custom solutions, becomes critical.
Agent Bricks is a good example of this shift. It makes building useful AI systems easier than ever, particularly for common use cases like knowledge assistants. At the same time, it reinforces the idea that the hard part isn’t building the agent—it’s preparing the data and understanding the system around it.
We’re in a phase where AI is no longer out of reach. These tools are accessible, relatively easy to use, and capable of delivering real value. The challenge now is not getting caught up in the novelty, but focusing on building systems that actually solve problems.

