
If you’re anything like me, you’re probably a little worn out by the constant flood of AI content. Every corner of the internet is filled with people claiming they’ve reached some new level of agentic enlightenment, sitting back while their swarm of digital workers magically produces perfect systems. It reminds me a lot of earlier eras, where developers believed the right IDE setup or tooling would somehow elevate them into a different class of engineer.
It’s the same pattern, just dressed up differently. Whether it’s Neovim configs in the past or Claude and Cursor workflows today, the focus is often misplaced. Real careers in this field were never built on tools alone. They were built on applying technical skills to messy, ambiguous business problems. AI doesn’t change that; it just changes the tools we use.
I’ve adopted AI into my workflow because the market demands it, and there’s no denying it’s powerful. It genuinely improves productivity across the software lifecycle, from initial idea to implementation. But there’s a big difference between using AI as a tool and building real systems that depend on it. The “Hello World” chatbot demos don’t prepare you for what happens when these systems are connected to real data and real business expectations.
- That’s where things start to get complicated.
At the core of the issue is a simple question: if you give the same input to an agentic system twice, will you get the same output? This is the idea of determinism, and it becomes a serious concern once you move beyond toy examples. LLMs are fundamentally probabilistic systems, and while you can tweak parameters like temperature, things become far less predictable when multiple agents are working together across data, tools, and workflows.
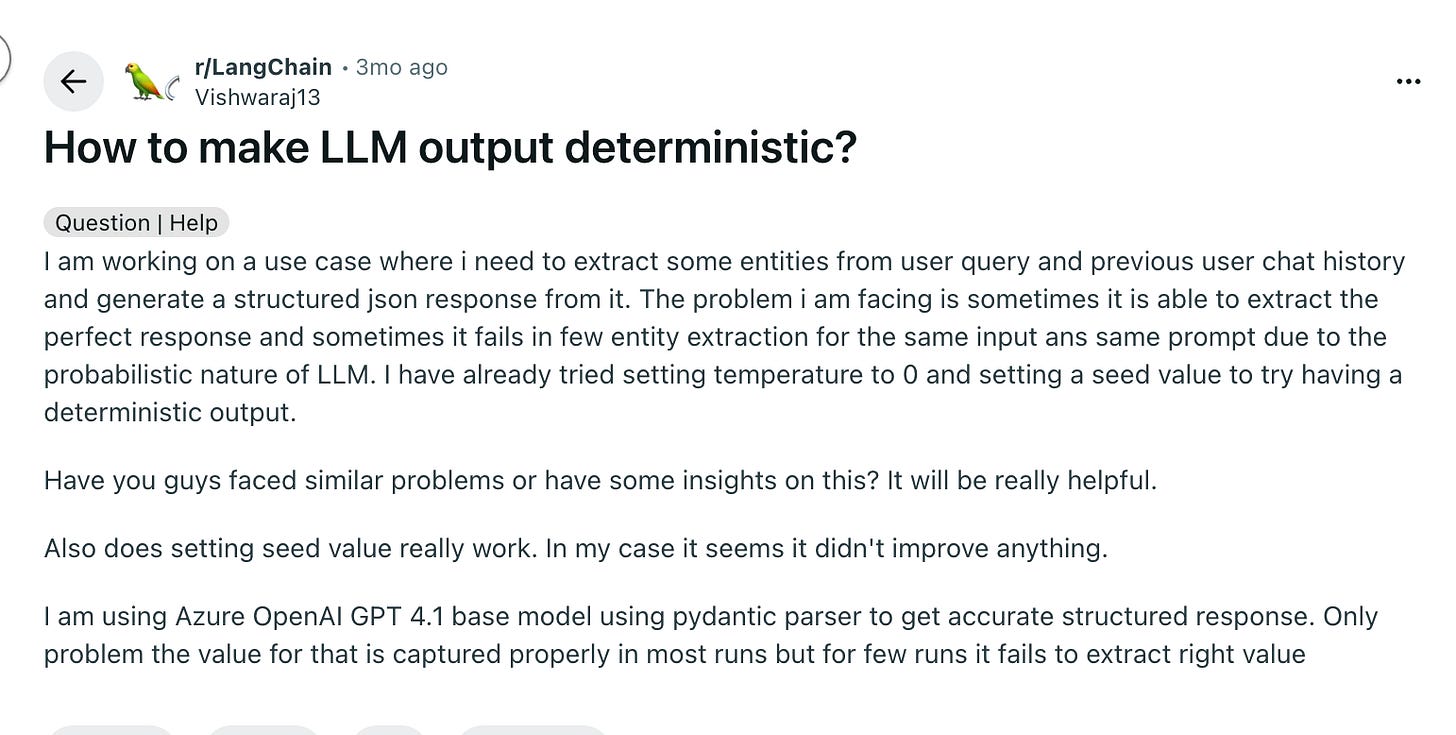
This problem is exacerbated when data systems come into play. For decades, data has been difficult enough on its own—ensuring correct joins, applying business logic, handling edge cases, and maintaining consistency across systems has always been a challenge. Now we’re layering probabilistic models on top of that and expecting reliable, production-grade results.
LLMs are excellent at generating SQL, but they are not inherently trustworthy in terms of correctness. Even with extensive context—schemas, relationships, example queries—you can’t guarantee that what’s being generated is right. If you ask a system to summarize data or generate a report, the business expectation is clear: the answer must be correct every time. “Mostly correct” is not acceptable in most real-world scenarios.
I’ve been working directly on this problem, building multi-agent systems connected to data platforms with strict business requirements. These are environments where incorrect results are not an inconvenience—they’re a failure. The natural instinct is to lean into the agentic paradigm: give agents more context, more tools, more autonomy, and assume the system will improve. In practice, that approach falls apart.
It’s incredibly easy to wire up a text-to-SQL workflow. You define the schema, describe the joins, provide examples, and let the model generate queries. You can even layer additional agents to refine results or generate reports. On the surface, everything looks impressive. Queries run, results are returned, and the system appears to work.
The problem is that you don’t actually know if the results are correct.
You might avoid syntax errors by constraining generation through tools like Pydantic, but logical correctness is a different issue entirely. A query can run perfectly and still produce incorrect results due to a bad join, missing filter, or misunderstood business rule. In many cases, the only way to catch these issues is through domain knowledge, the kind that lives in people, not documentation.
This becomes especially dangerous in production systems. I’ve seen agent-generated queries produce inflated or incorrect results simply because a critical join condition wasn’t represented clearly enough in the context. The system wasn’t broken; it was doing exactly what it was designed to do. The problem was that it didn’t truly understand the data.
- That’s when it becomes clear that fully autonomous, open-ended agentic systems are not the answer for data workflows where correctness matters.
The shift, at least for me, was toward more directed, deterministic designs. Instead of giving agents unrestricted access to raw datasets and asking them to figure things out, I started constraining the problem. The idea is simple: handle the parts that require precision and domain knowledge upfront, and let the agents operate within those boundaries.
In practice, this meant precomputing datasets using exact SQL queries with all joins and business logic applied. These datasets are guaranteed to be correct because they are explicitly defined. From there, agents can operate on this curated data, often using tools like DuckDB for local analysis. This significantly reduces the risk of incorrect results because the hardest part, the data modeling and logic, is no longer left to chance.
On top of that, I introduced directed workflows. Instead of open-ended reasoning, the system follows a fixed sequence of steps: retrieve data using predefined queries, perform deterministic analysis, and then use an LLM to generate summaries or reports based on that analysis. The LLM is no longer responsible for figuring out the data; it’s responsible for explaining it.
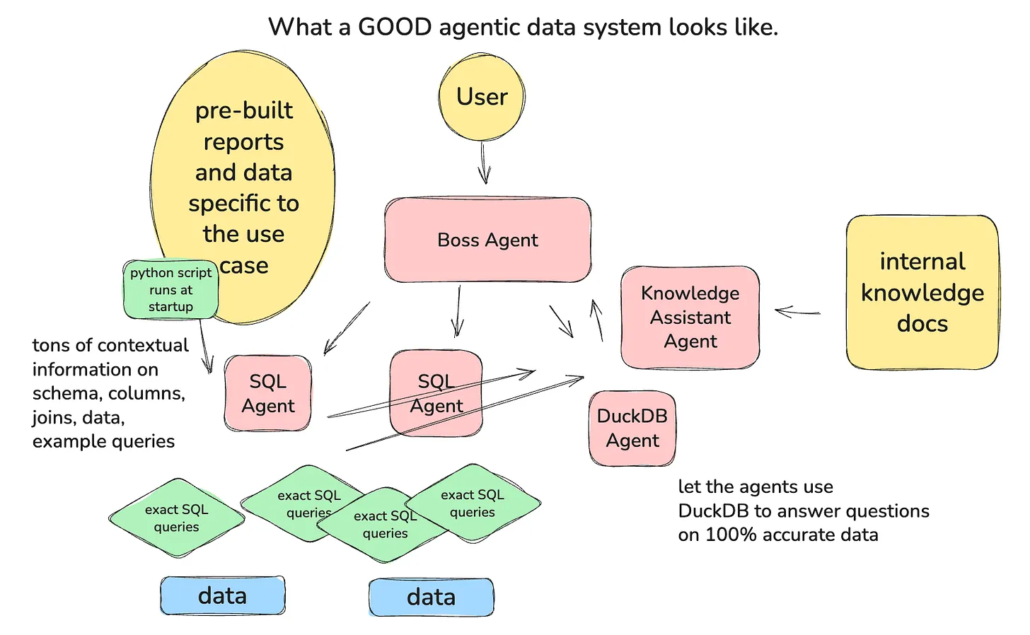
This approach dramatically improves reliability. It doesn’t make the system perfectly deterministic; there’s still some variability in how results are summarized or presented, but it brings the confidence level much closer to what’s required in production environments.
The key realization is that you can’t teach an agent everything about your business, no matter how much context you provide. That knowledge is built over time through experience, and it’s unrealistic to expect a model to fully replicate it. If you give agents too much freedom over your data, they will eventually make mistakes, and those mistakes will surface in ways that matter.
- The value in these systems doesn’t come from letting agents freely explore your data. It comes from combining human-defined correctness with machine-driven efficiency. You handle joins, filters, and business logic. The agent handles summarization, pattern recognition, and presentation.
In other words, the best agentic systems aren’t fully autonomous. They’re carefully constrained systems where each component does what it’s best at.
If you skip that upfront work, if you don’t define the data properly and enforce structure, you’ll get something that looks impressive in a demo but falls apart in the hands of real users. And by the time that happens, it’s usually too late.
That’s the tradeoff we’re dealing with. AI makes it easier than ever to build systems quickly, but it doesn’t absolve you of the responsibility of building them correctly.