DuckDB beats Polars for 1TB of data.
I’ve been a Polars bro for most of the last few years. Why? It’s Rust-based, fast, DataFrame-centric, just the way I like it. It also had the excellent feature, right from the start, of Lazy Execution. A few years ago, maybe two, I actually put Polars into production, running on Airflow, working with S3 and reading Delta Lake tables.
I was in love.
Then DuckDB came onto the scene. That SQL upstart is taking over the data world like we all knew it would. Selling SQL crack in the dark corners of the internet, the script kitties simply could never resist it. Then something strange happened; it started to grow on me. Slowly, without even realizing it.
You know what it was?
DuckDB and Mother Duck’s relentless obsession with being developer-focused, providing every integration known to man, and taking issues seriously. They knew it would pay off in the long run, with folk like me, and it did. DuckDB simply works, and works well. If something doesn’t work, they deal with it.
You know what else happened?
Polars did the opposite. I’m not sure if they lost focus while trying to spin up Polars Cloud, that piece of junk. Talk about half-baked crap, I don’t care who you are, it felt like it was made by a 12-year-old with access to Cursor, for real.
I pay attention to these things, I watch closely, how do these teams deal with open issues on GitHub, do they close them and throw up their hands saying “Not my problem, let that other tool fix it.” DuckDB doesn’t do that; it does the opposite.
The truth is, you can either say something like “this isn’t my problem,” or, like DuckDB, you can simply find a solution so the legions of engineers and future engineers to come use your tool because you go the extra mile to make it work.
DuckDB designed its execution engine to be streaming; this was foresight.
They also designed for large datasets with spill to disk as an option. You can also do something like …
SET memory_limit = '4GB';This is key for production use cases on commodity hardware, with large datasets (larger than memory), in the Lake House world we live in, this is a must.
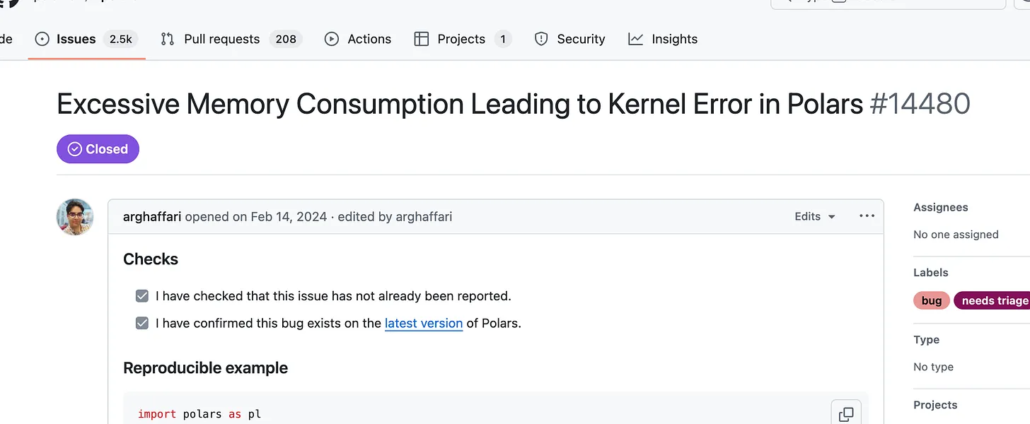
Polars has no such option; they just provide a Lazy Execution content that hopefully will work, and does with smaller datasets, but when you try to do real, production-like large datasets, say 1TB, it simply doesn’t work.
I generated 1TB of parquet files in S3, here is the code on GitHub.
Only a few columns, I wrote some simple code that would use every single column to do a simple aggregation … aka the entire 1TB would have be processed. DuckDB did fine. I used a 64GB instance, set a 54GB memory limit, and let DuckDB churn. 19 minutes later, it finished.
Polars? Lazy mode? No go, OOM on linux machine all day long no matter what.
You can see both the DuckDB and Daft code here that worked.
People have complained about this on GitHub multiple times with Polars, the inability to read and handle large Parquet datasets. Someone blames the OS and closes the issues. It’s sad.
I didn’t think this would happen years ago when I started using these tools. Polars in the new Pandas. Blowing up memory in production, and people will remember.