Lazy Execution with Polars and DuckDB
Something I’ve taken for granted for a long time, and then suddenly discover others are discovering for the first time, leaves me a little baffled. It makes me wonder how many folks are living under a proverbial rock. Recently, I saw a post on that infamous LinkedIn about someone excited about Polars’ lazy execution.
Part of me is agast that people are still unaware of the Seventh Wonder of the World, known as Lazy Execution… specifically on NON-distributed frameworks like Polars, Daft, and DuckDB.
The concept is very simple.
“Never read all data into memory, work on it in batches, in parallel even, but never all at once.”
It seems obvious, but it has taken a long time to move from tools like Pandas to the point where we are using fast Rust- and C++-based tools like Polars and DuckDB that embrace streaming data through memory, rather than loading everything at once. This makes for fast execution, and more importantly … the ability to work on larger than memory datasets.
This is critical in the age of distributed compute that is very expensive.
I recently proved a point by processing 650GB of data in Delta Lake on S3 with a 32GB EC2 machine on AWS, using Daft, Polars, and DuckDB. It worked fine.
Most engineers today have lost their sense of creativity and wouldn’t even dream of doing something like this. They would simply reach for Spark and spend the DBUs, let the CTO complain later about the cloud bills. We need to wake up from our SaaS enduced slumber and throw of the magic stupor poured into our brains by the marketing wizards.
Small, commodity-sized Linux hardware and servers can easily process large datasets that do not fit in memory. Frameworks like Polars and DuckDB are simple and easy to install; the code is very uncomplicated —it’s a no-brainer. What will it take for this sort of approach to catch hold?
Probably never going to happen. It’s only the cost-conscious startups and scrappy teams who will bother with such things. Everyone else will just lie on their digital couches, eating digital potato chips (Snowflake and Databricks), and pat each other on the back for a job well done. So it goes.
This is how easy it is to process 650GBs of data in cloud storage with a 32GB EC2 instance with DuckDB.
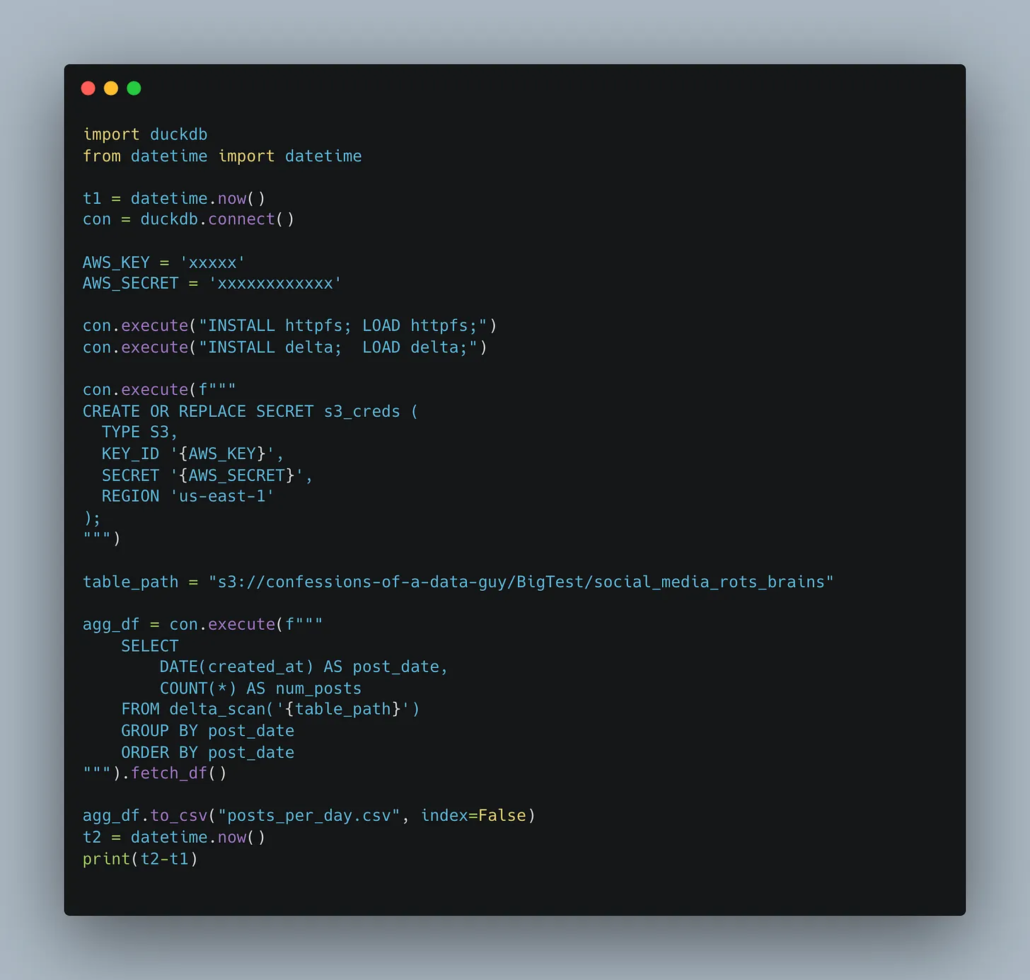
Would someone explain to me what is so hard about this?
Nothing but pure laziness would cause someone to spend money on Spark to run such things when small commodity (cheap) hardware could do the same job quickly for a fraction of the price.
As engineers, we have a duty to press the boundaries of what’s possible. We owe it to the business and the bottom line not to take the easy path at every turn; sometimes, we have to plunge off into the woods and hack our own way to glory. Being a lemming and using Spark is not glory, and it gets boring after a while.
Embrace your lazy frameworks. Use them in production.