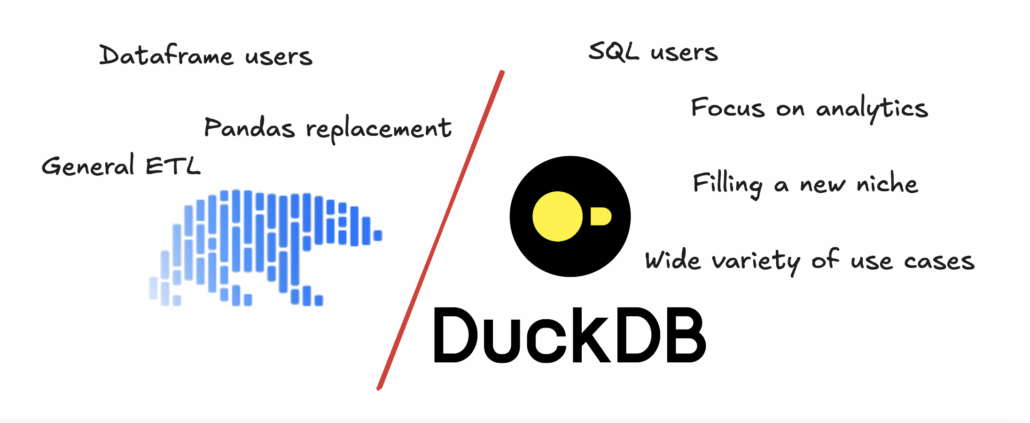
DuckDB vs Polars. Wait. DuckDB and Polars.

So, the classic newbie question. DuckDB vs Polars, which one should you pick?
This is an interesting question, and actually drives a lot of search traffic to this website on which you find yourself wasting time. I thank you for that.
This is probably the most classic type of question that all developers eventually ask at some point in their sad and depressing lives. Isn’t that the same story that is as old as time? This stick is better than that rock. Rust is better than C. Databricks better than Snowflake. You know, Delta Lake better than Iceberg.
And so the world keeps turning and grinding away.
DuckDB vs Polars? That’s the wrong question.
I hate to pop your little bubble you giant baby. Well, maybe I do enjoy it a little. If you have come here, to this lonely and foresaken spot in the interwebs to find out which is better, Polars or DuckDB … I ain’t going to do it Sunny Jim. You can’t make me. There is no “this one is better than that,” over arching answer.
Is Polars better than DuckDB? Is DuckDB better than Polars. IT DEPENDS ON THE CONTEXT.
Let’s first take a very high level 10,000 foot view of Polars and DuckDB to set the record straight.
What DuckDB Is
DuckDB is an open-source, in-process analytical database. Think of it as “SQLite for analytics”: instead of running as a separate server, DuckDB is an embedded library that you link directly into your application or use as a simple command-line tool. Its sweet spot is OLAP (online analytical processing)—fast, ad-hoc queries over large datasets—rather than high-volume transactional workloads.

DuckDB is small and easy to install via whatever way you want, binary, bash, Python pip, etc. I think a key concept to grasp here is that DuckDB calls itself a “database,” among other things. You will hear no such claim from Polars, and you need to hark back to the reason why you are here. This is a hint. What is should I use, DuckDB vs Polars?
What is DuckDB known for?
- blazing fast
- lightweight easy to install
- plethora of extensions (integrations)
- SQL centric

Ok, so you think this is just is just another view into what is classic DuckDB hello world code? Than you’re missing the point! What do you notice about the DuckDB docs themselves when it comes to showing HOW to use DuckDB? There are CREATE statements, INSERT statements etc.
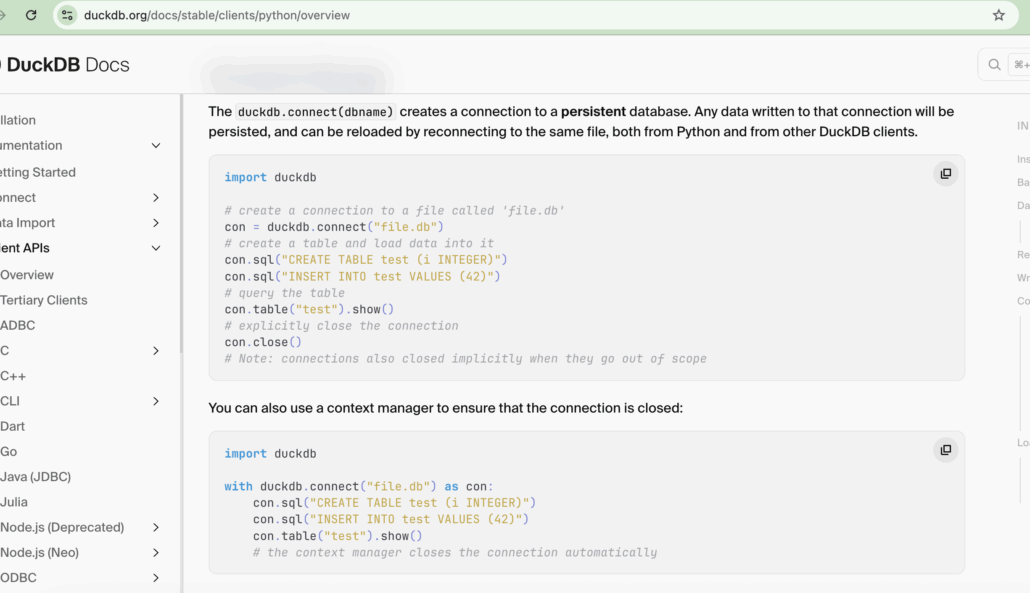
This is something you would expect from a …. DATABASE … centric tool.
Yes, you can just use DuckDB to run SQL against various DataFrames, s3 files, blah, blah, blah. But, it’s worthy of note that both in their promotion and usage of DuckDB, it is at least in part, communicated as a “database” tool.
Over to Polars.
Ok, let us change our hats and take a look at Polars.
Polars is a fast, multi-language DataFrame library for data manipulation and analytics—similar in spirit to Pandas, but designed from the ground up for speed, scalability, and parallelism.
It has native APIs for Python and Rust, plus bindings for Node.js and others.
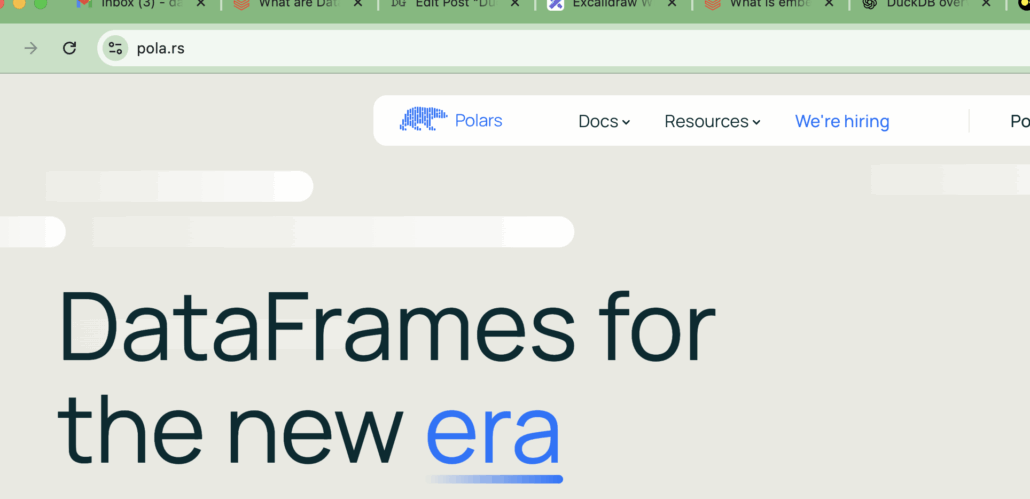
So, right off the bat we can can see the difference between DuckDB and how the Rust based GOAT Dataframe tool Polars is presented to us.
“Polars is an open-source library for data manipulation, known for being one of the fastest data processing solutions on a single machine. It features a well-structured, typed API that is both expressive and easy to use.” – Polars.
There is really no other way than to simply say that Polars wants to be the new Pandas for data professionals. No talk about databases.

This is just simple, plain, unadulterated data transformation that is fast and beautiful, that’s it. Throw Pandas to the curb, to the trash heap where it belongs, use Polars. That’s it.
Do DuckDB and Polars overlap?
I get the question of DuckDB vs Polars, at it’s core, I do. But, think it’s really not that correct question to answer if you actually stop and think about the question you are asking. Yes, you can use Polars and DuckDB to solve the same question, it’s not about those tools in particular. You can solve any problem in a myriad of ways.
That isn’t the point. The point is that you should examine more closely that problem that you are working on, and pick DuckDB or Polars based on the context in which you work.
- are you primary about using SQL or not? (DuckDB)
- do you currently use DataFrames alot, Spark, Pandas, etc? (Polars)
- what is your team comfortable with? (?)
- are you building end-to-end ETL/pipelines? (Polars)
- are you mostly doing analytics over existing datasets? (DuckDB)
- are you looking to embeed something as an engine to drive other features? (DuckDB)
There simply is no DuckDB vs Polars. They each of clearly have won the battle to become an everyday name in the Modern Data Stack, otherwise we wouldn’t be talking about this.
These tools are extremely similar, in the sense they can be data munging tools used by the masses, you can in fact use a hammer to crack your morning breakfast eggs if you so choose. It will work. But, what would a Senior+ engineer do when faced with a problem of using DuckDB or Polars?
They would simply choose the right tool for the right job.
Only you will know the answer to that question. It’s all about the problem you are solving, and the context on which you are working on said problem. Can you pick DuckDB or Polars at random and solve whatever problem you are working on? Yes, 100%. Can you and should you switch between using DuckDB and Polars depending on exactly what you are trying to accomplish? Of course.
You should not pay particular attention to benchmarking results, arguments of speed centered around which tool can save you milliseconds. It doesn’t not matter. That is the classic thinking of over zealous software engineers who deliver no business value at the end of the day.

