
What is SQLMesh and how is it different from dbt?
SQLMesh is an open-source framework for managing, versioning, and orchestrating SQL-based data transformations.
It’s in the same “data transformation” space as dbt, but with some important design and workflow differences.
What SQLMesh Is
SQLMesh is a next-generation data transformation framework designed to ship data quickly, efficiently, and without error. Data teams can efficiently run and deploy data transformations written in SQL or Python with visibility and control at any size.
So … what you are telling me is that it’s dbt … but with Python? Interesting enough concept, I should say. One would have to surmise that most people using SQLMesh would be using … SQL! Look at how smart I am.
- A data transformation tool for SQL and Python, focused on reliability, testing, and reproducibility.
- Tracks changes to transformation logic as versions, making it easy to:
- Recompute only the data affected by changes.
- Run backfills in a controlled way.
- Has built-in incremental & full refresh strategies.
- Supports multiple engines (e.g., Snowflake, BigQuery, Spark, DuckDB) without heavy boilerplate.
Project Structure
1. Project Config – sqlmesh.yaml

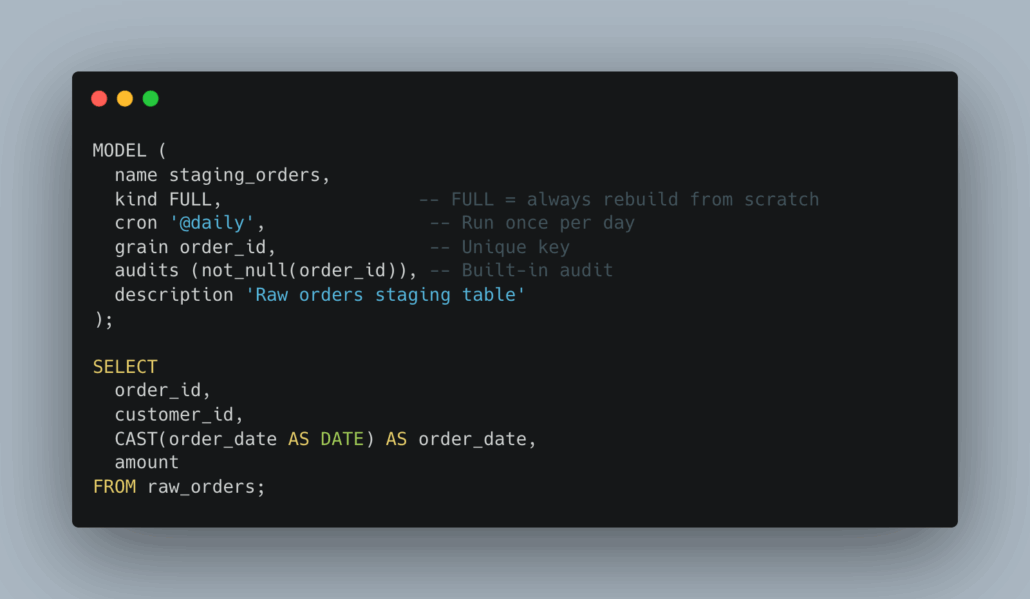
2. A Staging Model – models/staging_orders.sql
3. Python Model – models/python_model.py

4. Running It

Key Takeaways from the Code
-
SQLMesh models are self-describing (
MODEL()metadata). -
Supports incremental and full refresh modes.
-
Can mix SQL and Python seamlessly.
-
Built-in
plan,run, andbackfillcommands remove the need for an external scheduler in many cases.
Key Differences from dbt
1. Execution Model
- dbt
- Primarily a compile-and-run approach: it turns your SQL models into SQL scripts that run against the warehouse.
- Changes often require running the whole DAG or relying on manual selection.
- SQLMesh
- Maintains a stateful plan of your project.
- When you change a model, SQLMesh calculates what needs to be recomputed based on versioning and dependencies.
- Reduces unnecessary recomputation.
2. Versioning & Data Diff Awareness
- dbt: Versioning is handled externally (e.g., Git); dbt doesn’t track dataset versions internally.
- SQLMesh: Assigns a fingerprint to each model definition and keeps track of which data version is in the warehouse.
This lets it:- Backfill only missing or outdated partitions.
- Test new changes in “virtual environments” before applying them to prod.
3. Environments
- dbt: You typically have separate schemas (dev, prod) and rely on
dbt runagainst the correct target. - SQLMesh: Has built-in environment isolation — you can run an updated transformation in a “dev” environment side-by-side with prod, without overwriting prod data, and promote it only when validated.
4. Scheduling & Orchestration
- dbt: Requires an external scheduler (dbt Cloud, Airflow, Dagster, etc.).
- SQLMesh: Includes its own built-in scheduler and orchestration, so you can run and monitor pipelines without extra tools (though you can still integrate with Airflow).
5. Python & SQL Integration
- dbt: Primarily SQL + Jinja templating (some Python support in dbt-Python models, but limited).
- SQLMesh: Native Python model support alongside SQL, enabling more complex transformations without leaving the framework.
6. Testing & CI/CD
- dbt: Strong testing framework for schema/data tests, but tests run outside of actual transformation runs.
- SQLMesh: Allows dry runs and data diffs between environments before deploying, reducing risk of breaking prod.
In Short
| Feature | dbt | SQLMesh |
|---|---|---|
| Execution | Compile & run | Stateful, version-aware |
| Versioning | External only | Built-in model fingerprinting |
| Orchestration | External tool needed | Built-in |
| Environments | Schema-based | Isolated environments with promotion |
| Python Support | Limited | First-class |
| Recompute Strategy | Manual or full DAG | Auto-calculated minimal recompute |
| Backfills | Manual | Automated, dependency-aware |
If you want a mental shortcut:
dbt is great for declarative SQL transformations with strong community and tooling,
SQLMesh adds state awareness, built-in orchestration, and versioned environments to that idea — making it feel more like a data CI/CD system than just a compiler.

