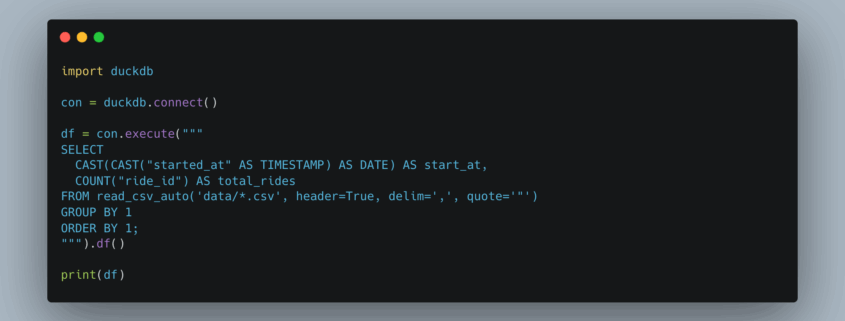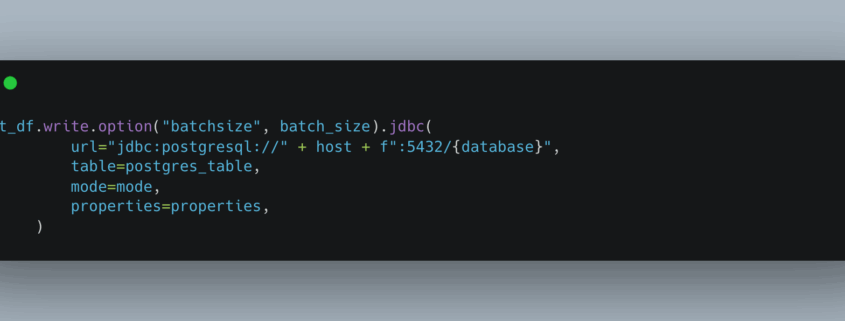
I was recently working on a PySpark pipeline in which I was using the JDBC option to write about 22 million records from a Spark DataFrame into a Postgres RDS database. Hey, why not use the built in method provided by Spark, how bad could it be? I mean it’s not like the creators and maintainers of Spark aren’t probably our version of rocket engineers.
Well, a few hours later staring at my screen, I knew something had to change. Slower than your grandma on her way to the quilt shop.