Real-Life Example of Big O(n) Notation (and other such nonsense) for Data Engineering.

In the beginning, I always thought the humdrum Big O Notation discussions should be reserved for Software Engineers who enjoyed working on such things. I mean, what could it possibly have to do with Data Engineering? I mean, if you are the person writing the Spark application, by all means, have at it, but if you are the Data Engineer who is simply using Spark, why can’t you just leave the details to the Devil? Seems to make sense.
The only problem with that logic is the longer you work as a Data Engineer, probably the harder the problems you work on become, you write more and more code, and basically end up being a specialized Software Engineer … even if you don’t want to be. In the end, to be a good Data Engineer you should at least attempt to understand the concepts behind Big O Notation, and how those concepts can apply to you as Data Engineer, especially for the ETL that most of us write.
Why care about Big O Notation?
Should you really care about Big O Notation as a Data Engineer? Yes. What is Big O Notation?
“Big O Notation is used mostly in reference to algorithms, their space/time complexiy, and how does the code (inside your algorithm) respond to changes of the input.”
– Me
If you don’t like my definition of Big O Notation ( go read the real definition ) …
- I don’t care.
- Write your own blog.
- You’re too smart to be reading this … go do something else.
But you’re like “Hey, I don’t write algorithms, I just do transformations and data movements all day.” Well, yes you sort of do write algorithms all day long, you’re writing code or something that gets executed as code aren’t you? Then you should care generally about what Big O Notation is, and what all those smart Software Engineers are telling you about Big O.

Blah, blah, blah, so what does it really boil down to? Why do people care about Big O Notation? It is usually about speed. If you write code that works on 10 items, and it takes 10 seconds to do that work, ok, it’s probably fine. But what if that input size is changed to 100,000 items, and now it takes 100,000 seconds … that is not good. You don’t want the time it takes to do the thing to scale with your input. That’s not efficient and won’t work in the long run.
Sure, it’s ok if 10 items take 10 seconds, and 100,000 items take 20 seconds. But not 100,000 seconds … you get the idea.
Data Engineers write algorithms every day, even if they don’t think they do. They are writing code, or taking a combination of code others have written (via a GUI, API (like Spark API’s), and stitching them together to do a thing, to produce an output. The stitched-together thing called “ETL” or “ELT”, or whatever you want to call it, should abide by the same rules that Software Engineers apply to their algorithms when it comes to Big O Notation.
Real-Life Big O(n) Notation for an everyday Data Engineering task.

We should pontificate about Big O Notation for Data Engineering using an everyday example, something that pretty much most all Data Engineers have done at some point in time. Like load a Fact (or a stupid Gold table if you must call it that) table in a Data Lake / Warehouse / Lake House.
Let’s look at an O(n) example where “Runtime grows in proportion to n,” meaning as we add more inputs the time to compute the operation grows linearly. I think a good old staging to fact load in a Data Lake will be sufficient to observe how Big O Notation, or its thought process, can affect Data Engineers writing ETL/ELT.
O(n) example for Data Engineers.
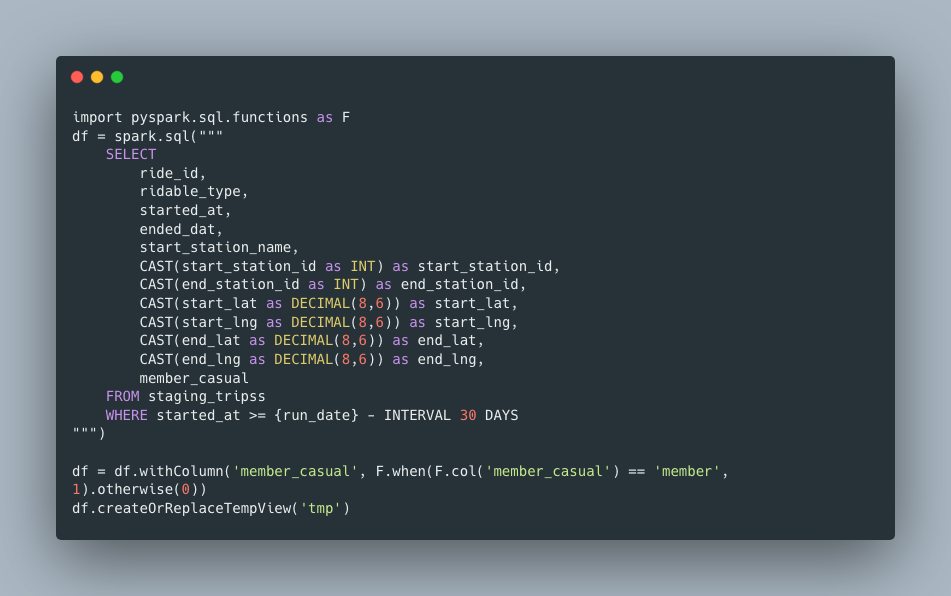
Let’s say we have two Delta tables, one is a staging table holding our raw data, and another is our fact table holding the transformed data. Every day, or multiple times a day, we must push new records from our staging table and insert them into the fact table, a simple pull, transform, then insert. We will of course use the free and open source Divvy Bike’s data set. I will also use Databricks and Delta Lake with files on s3, but the concepts apply outside those technologies.
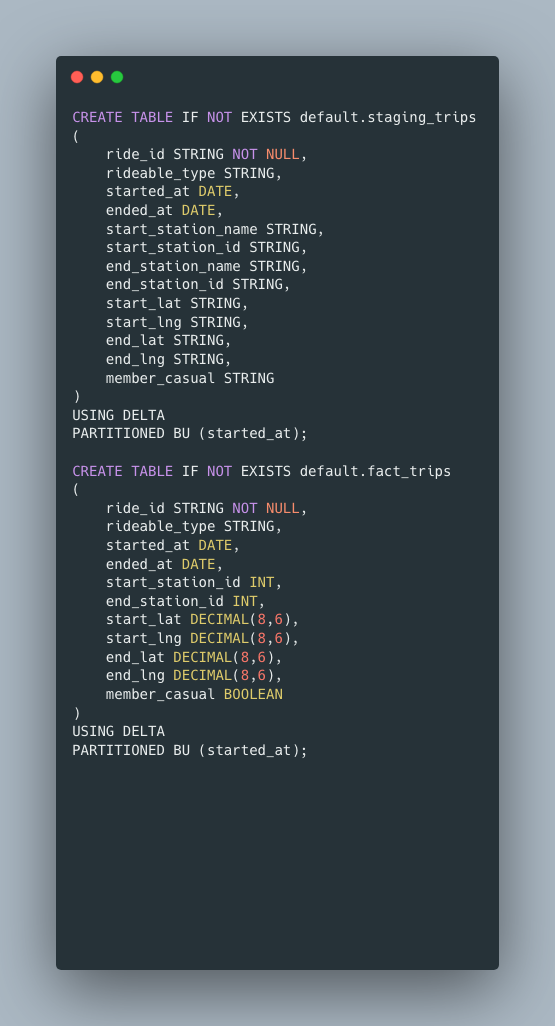
As you can see in the above DDL, this is a contrived example, our transformations mostly consist of changing data types, but that’s ok, we really are going to be focused on the problem at hand, loading new records from the staging table in the fact table.
How might a new Data Engineering approach this problem and inadvertently design an O(n) data load that will not scale, and cause severe problems down the road? What about a common MERGE statement to pull data from the staging table and insert the new records?
But first, I want to slowly insert records into my staging table, one file a time, and then run the MERGE statement, after each file load … with a bare MERGE statement ( O(n) ) , that must act on all records, every time.
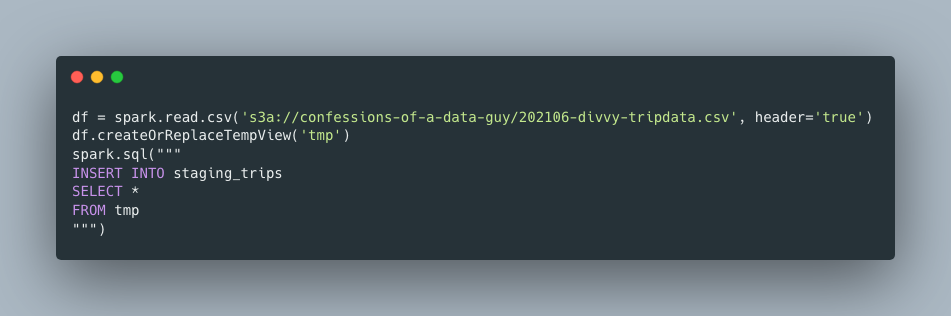
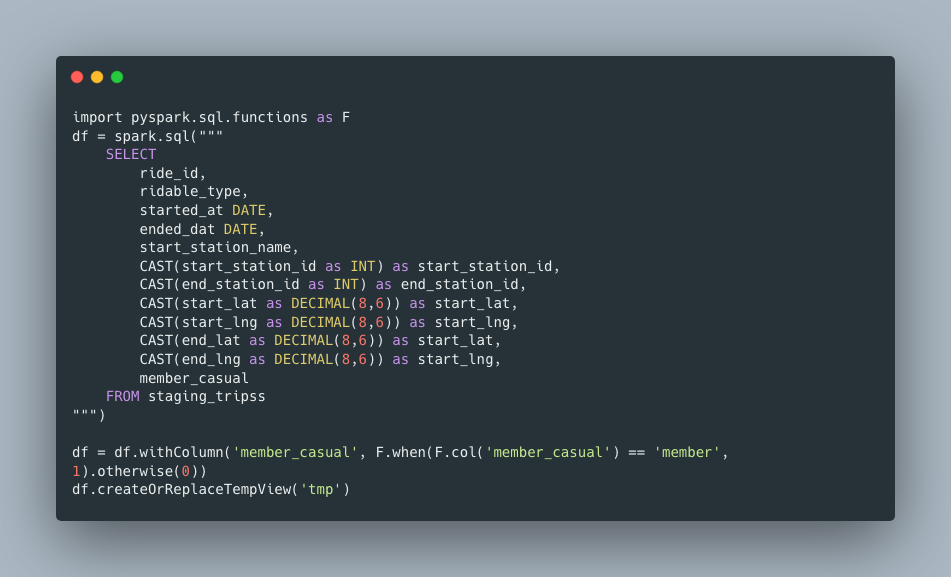
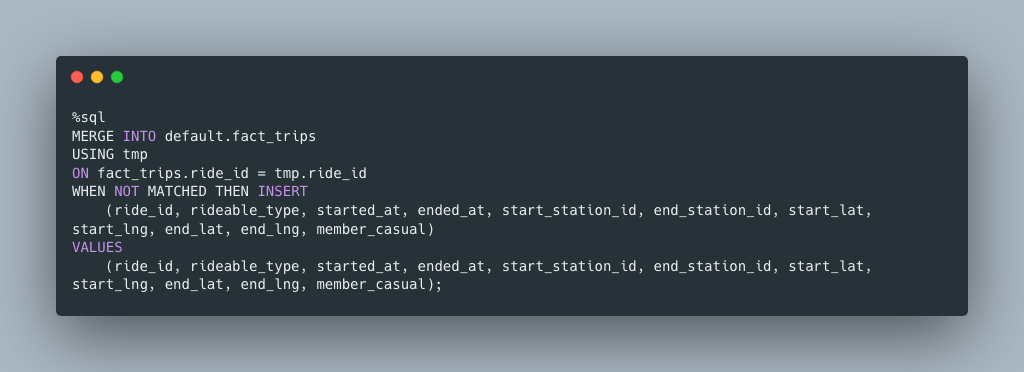
For each file I load, I will continue to run the same load statement, copying in a new file, the simple ETL statement (note, above MERGE statement that is simply getting new records based on a join to the primary key, ride_id. This isn’t very scalable, the more data I add on both ends, both staging and fact, the longer and more time this process will take.
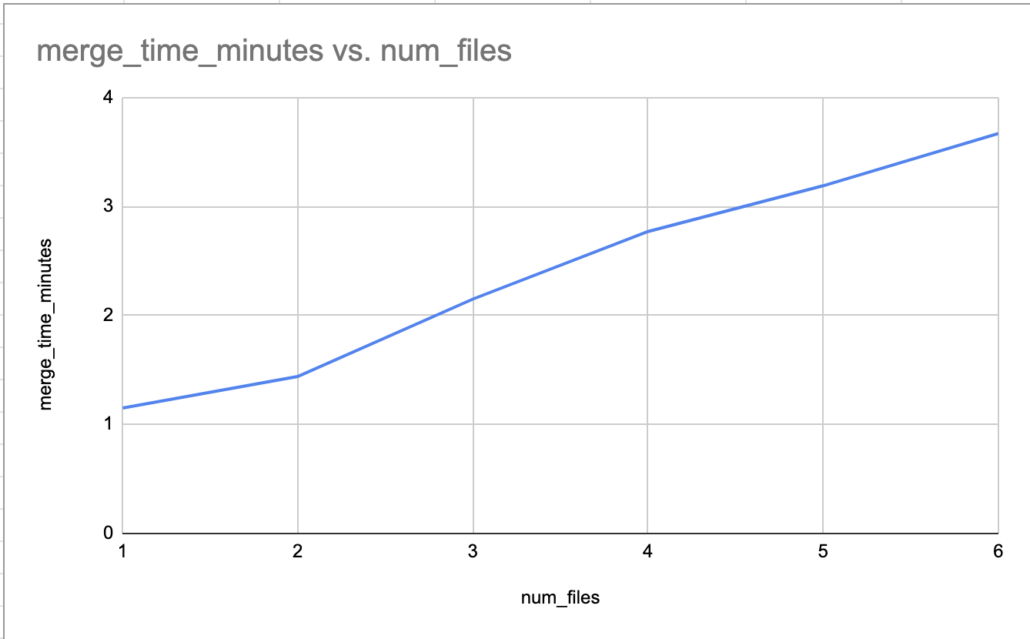
Well, that’s not a trend-line you want to see is it. How very O(n) of you. Maybe some of those crusty old SWE concepts like Big O notation and teach us Data Engineer’s something after all. If we wrote some ETL/Ingest like this, which is very easy, especially in the beginning we would have something that would slowly break us over time, cost, runtimes would continue to climb with no end in sight. Eventually bogging down into the quagmire.

Moving past O(n) as Data Engineers
It’s important for good Data Engineers to move past this issues and avoid them all together. We can think about our ETL and transformation pipelines much like a good SWE would think about the time-complexity of their algorithm. Being critical about our designs, testing different scenarios and thinking about the impact of changes and how our code scales is of the highest value.
In our contrived example above the problem is obvious … we can’t compare everything to everything … it’s just not scalable. What are some possible solutions?
- Load the last X days from
stagingtoMERGEinto ourfacttable. - Use something like
input_file_namein Spark and in the DDL of the tables to track what files have or have not been loaded etc. - Use some other black magic of your choosing.
In our simple example, we could just decide to grab the last say, 30 days of the date we are currently loading. Not perfect, but probably a step in the right direction. Maybe we configure our ETL like such.
By George, had to change the chart to be seconds, and not minutes after rerunning the same experiment.
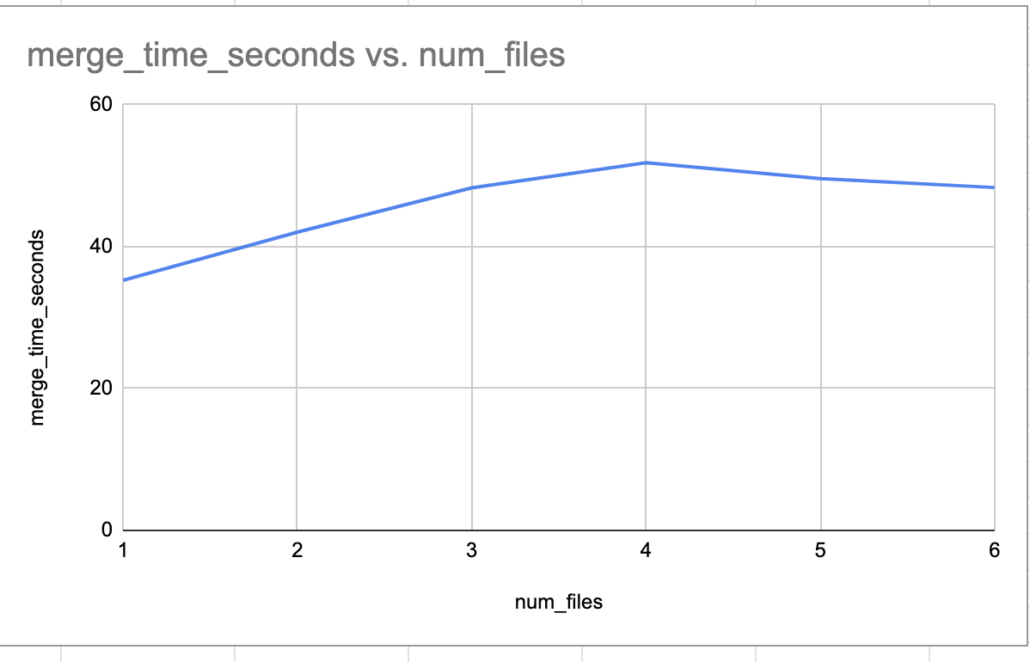
Now that’s more like it, no more 0(n) as we scaled up the data loads as before. Unlike the first attempt, we don’t see the trend spiking up as we increase the inputs and data size. Such a simple solution as well, although the real world is much more complex.
Musings
Although I do write code all day long, I rarely get the time to work on details at level of most SWE’s, worrying about space-time complexity of a single algorithm, pontificating to other smart folks theories on why such and such is O(n) or O(log n) blah blah. I do find it helpful to attempt to learn about such things and apply those sample principals to the work I do on a daily basis.
It’s never good to get suck in a routine, in your own little world, SWE or DE or whatever you happen to be. It’s good to keep your mind open, listen and learn about what helps others, and think about how we can ingest those principals for our own benefit. In the age of SAAS vendors taking over Data Engineering, companies like Snowflake and Databrick’s are taking over the world, but those things cost money. Keeping eye to the details as a DE, even when writing ETL/ELT all day long pays off in the long run, finding ways to reduce runtime and costs are usually easier than you think and provide lasting value.