Musings on Python’s map() and filter()

I’ve always been surprised at the distinct lack of most Python code I’ve seen using the map() and filter() methods as standalone functions. I’ve always found them useful and easy to use, but I don’t often come across them in the wild, I’ve even been asked to remove them from my MR/PR’s, for no other reason then that they are supposedly ambiguous to some people? That’s got me thinking a lot about map() and filter() as related to readability, functional programming, side effects and other never ending debates where no one can even agree on the “correct” definition. Seriously. But, I will leave that rant for another time.
Reviewing Python’s map() and filter()
I have no desire to dig into the internals of how map and filter work. But, lets just review them quickly to set a baseline.
map()
If you’re going to run into one of these methods, you are most likely to come across `map()` before anything else. Map is very straight forward… it takes two arguments…
- function
- iterable (for example a list)
Also, map() will return a iterable as well.
def who_is(name: str) -> str:
return f"{name} is a hobbit."
workload = ['Frodo', 'Billbo', 'Samwise']
hobbits = map(who_is, workload)
for hobbit in hobbits:
print(hobbit)
...
Frodo is a hobbit.
Billbo is a hobbit.
Samwise is a hobbit.
>>> Nothing to earth shattering about that.
filter()
The filter() method is exactly the same as map() except it’s doing the opposite in a sense. It takes two inputs as well.
- function to test truthiness
- iterable.
It will return a iterable as well.
def who_is(name: str) -> str:
if "F" in name:
return f"{name} is a hobbit."
workload = ['Frodo', 'Billbo', 'Samwise']
hobbits = map(who_is, workload)
for hobbit in hobbits:
print(hobbit)
...
Frodo is a hobbit.
>>>Musings on readability, testability, side affects and more.
I’m not totally sure if I buy this one, but I’ve seen it come up when objections are raised about using map() and filter(), and it usually takes the shape of some ambiguous statement about how it isn’t obvious what is happening in the code … especially if you throw a lambda in the middle… which I’ve been known to do. Again, I sort of get it and I don’t.
- Yes, most people use
forloops to do everything… even simple and small actions. - I don’t think
map()orfilter()are not “readable”, you just don’t use them so it makes you take a second look.
Let’s say you have a list or stream of customer records that require some slight ETL changes on ingestion into some system. You need to create a full name based on first and last names. Now most people are going to do this. Specifically the for record in records_stream:
def create_full_name(record: dict) -> dict:
first_name = record["first_name"]
last_name = record["last_name"]
record["full_name"] = f"{first_name} {last_name}"
return record
records_stream = [
{"first_name": "Billbo", "last_name": "Baggins"},
{"first_name": "Samwise", "last_name": "Gamgee"}
]
records = []
for record in records_stream:
record = create_full_name(record)
records.append(record)
print(records)
...
[{'first_name': 'Billbo', 'last_name': 'Baggins', 'full_name': 'Billbo Baggins'}, {'first_name': 'Samwise', 'last_name': 'Gamgee', 'full_name': 'Samwise Gamgee'}]
>>> Now for sake of brevity and simplicity I’m not sure why you wouldn’t just write….
def create_full_name(record: dict) -> dict:
first_name = record["first_name"]
last_name = record["last_name"]
record["full_name"] = f"{first_name} {last_name}"
return record
records_stream = [
{"first_name": "Billbo", "last_name": "Baggins"},
{"first_name": "Samwise", "last_name": "Gamgee"}
]
records = map(create_full_name, records_stream)
print([record for record in records])
...
[{'first_name': 'Billbo', 'last_name': 'Baggins', 'full_name': 'Billbo Baggins'}, {'first_name': 'Samwise', 'last_name': 'Gamgee', 'full_name': 'Samwise Gamgee'}]
>>> Readability is important, but I don’t think map or filter would violate that. I usually see the readability pushback with combining a map and filter with a lambda. Something like this. Although my lambda is very wordy, imbedding such a thing inside a map or filter like below I suppose can be less obvious.
records_stream = [
{"first_name": "Billbo", "last_name": "Baggins", "treasure" : 50},
{"first_name": "Samwise", "last_name": "Gamgee", , "treasure" : 20}
]
records = map(
lambda record: {
"first_name": record["first_name"],
"last_name": record["last_name"],
"full_name": record["first_name"] + " " + record["last_name"],
},
records_stream,
)
print([record for record in records])
...
[{'first_name': 'Billbo', 'last_name': 'Baggins', 'full_name': 'Billbo Baggins'}, {'first_name': 'Samwise', 'last_name': 'Gamgee', 'full_name': 'Samwise Gamgee'}]
>>> When it comes to testability, I feel like if you write code that code can be tested. As long as you can wrap something in a def you can probably easily pytest it.
def add_full_names(records_stream: list) -> iter:
records = map(
lambda record: {
"first_name": record["first_name"],
"last_name": record["last_name"],
"full_name": record["first_name"] + " " + record["last_name"],
},
records_stream,
)
return records
def test_add_full_names():
test_stream = [{"first_name": "bing", "last_name": "bong"}]
outputs = add_full_names(test_stream)
print([output for output in outputs])
assert [output for output in outputs] == [{"first_name": " bing", "last_name": " bong", "full_name": "bing bong"}]When it comes to functional testing, side effects and all the other things those Scala folks talk about I’m not sure if the above function violates any of those rules or not. I generally try to only mutate data once in a single function, which is really what I’m doing above, just because the map and lambda exist in the same definition I’m not sure if that matters. I always at least loosely try to follow the no side effects idea. There is nothing worse then a giant function that should be 5 functions, it’s always messy, hard to read, and hard to know what’s happening or supposed to happen.
It seems that by default map and filter are always mutating the data input, so in theory a function should only include the map and filter and nothing else. Which maps and filters are so concise it’s kinda hard to not keep going.
Performance of map and filter vs for loops.
I’ve often wondered about the performance difference, if any between using a map and a for loop. I’m sure I could just google it but the proof is in the pudding. I’m going to use the ole’ Divvy Bike trips open source dataset to get a decent sized csv file to iterate rows on. There are 550,000 rows in my dataset so that should be good enough.
Let’s say I wanted to return all the values where someone rented a bike for more then 1 day.
import csv
from datetime import datetime
def date_diff(row: list):
start = datetime.strptime(row[2], '%Y-%m-%d %H:%M:%S')
end = datetime.strptime(row[3], '%Y-%m-%d %H:%M:%S')
diff = start - end
if diff.days >= 1:
return diff.days
else:
return 0
def read_csv_file(csv_path: str) -> object:
f = open(csv_path, "r")
csv_reader = csv.reader(f)
next(csv_reader)
return csv_reader
if __name__ == "__main__":
csv_reader = read_csv_file("202007-divvy-tripdata.csv")
t1 = datetime.now()
days = []
for row in csv_reader:
day = date_diff(row)
days.append(day)
sum([day for day in days])
t2 = datetime.now()
print(t2-t1)Above is the simple for loop and below is what I changed to add the map.
if __name__ == "__main__":
csv_reader = read_csv_file("202007-divvy-tripdata.csv")
t1 = datetime.now()
days = map(date_diff, [row for row in csv_reader])
sum([day for day in days])
t2 = datetime.now()
print(t2 - t1)Well, didn’t see that coming. Maybe you did? Apparently the plain old for loop is faster then the fancy map. I suppose it isn’t that big of a deal, but if your writing custom distributed Python on Kubernetes like me…. then it does kinda of matter which is faster. I suppose little choices like this add up over time, and on top of bit data would end up costing you more money. Below is the graph, I ran each set of code 5 times.
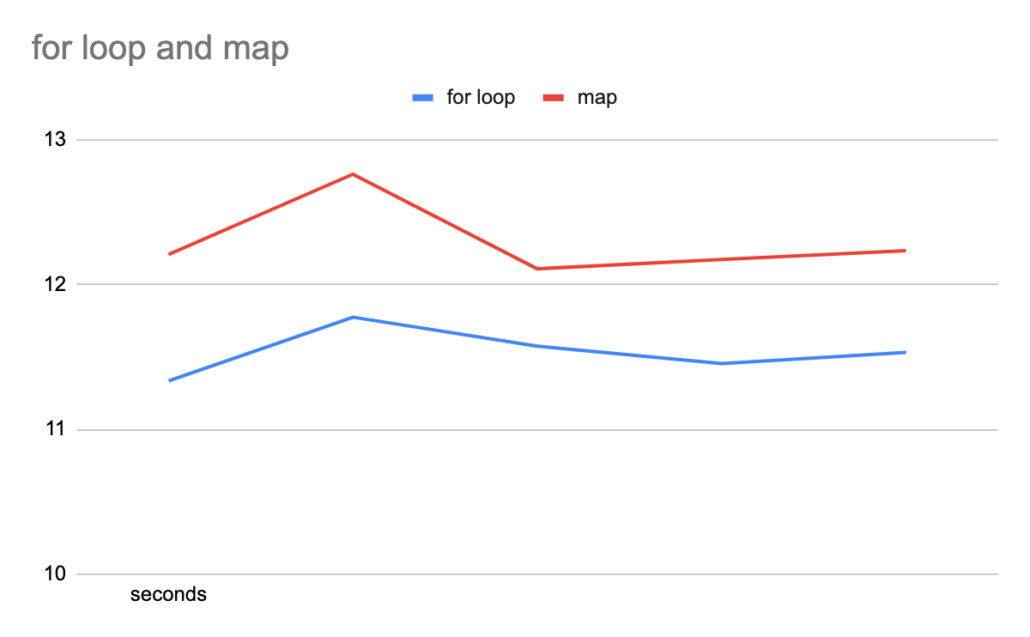
Musings in conclusion.
Maybe it’s just because I’ve been writing Scala lately and appreciate concise statements and less lines of code. Part of me is ok with writing map and filter even with a nasty lambda in the middle…. just because I like the way it looks. But, knowing at scale that the basic for loop is faster… well that does give me pause.