
Finally, a Simple, Cloud-Friendly Apache Iceberg Catalog That Just Works
Let’s be honest: working with Apache Iceberg stops being fun the moment you step off your local laptop and into anything that resembles production. The catalog system—mandatory and rigid—has long been the Achilles’ heel of an otherwise promising open data format.
For a long time, you had two options: over-engineered corporate-grade solutions that require infrastructure teams to babysit or sketchy hacks no one wants to rely on.
But now? Things might finally be changing.
Say Hello to boring-catalog
Thanks to Julien Hurault, we now have something Iceberg has sorely lacked: a lightweight, no-nonsense, open-source catalog that works out-of-the-box in the cloud. It’s refreshingly simple and lives up to its name—boring-catalog—because it’s exactly what you want a catalog to be: uneventful.
From the GitHub description:
“A lightweight, file-based Iceberg catalog implementation using a single JSON file (e.g., on S3, local disk, or any fsspec-compatible storage).”
It doesn’t need a server. It doesn’t assume you’re Google. And it doesn’t make you jump through flaming hoops to get it running. If you’ve ever tried standing up an Iceberg REST or Hadoop catalog on AWS for a small data team, you know how painful that can be.
Let’s walk through just how quickly you can get boring-catalog up and running.
Quickstart: From Zero to Iceberg Table in S3
Step 1: Install the essentials
Step 2: Initialize your Iceberg warehouse
Heads up: You’ll need to make sure your AWS credentials are exported to your environment. The CLI doesn’t currently support selecting a specific profile from your .aws/config.
Step 3: Create your table manually (yes, really)
Turns out, the pyiceberg library expects you to explicitly define a table location even when the parameter is marked as optional in the source code.
This works fine. Sure, it should ideally default to a logical location, but this little workaround gets you moving.
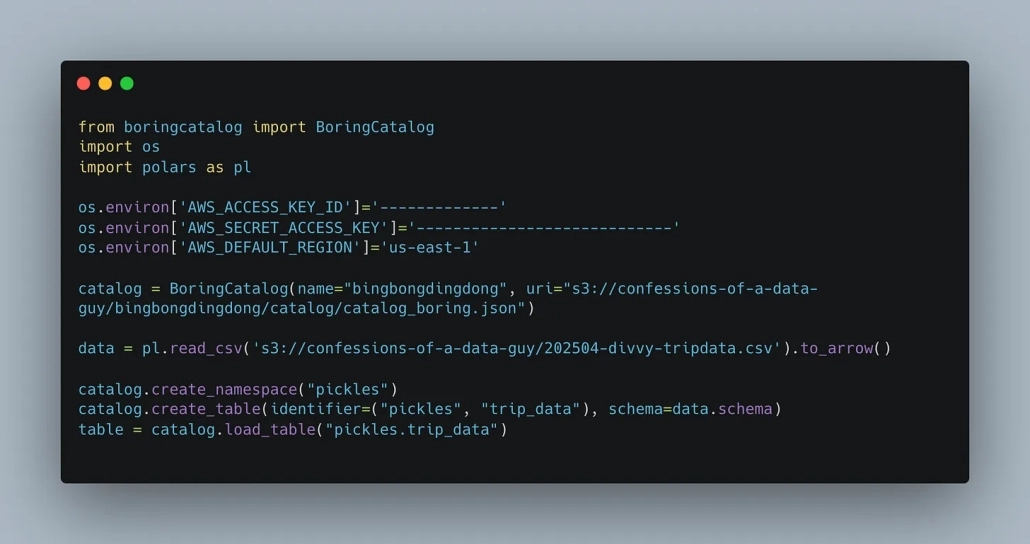
Step 4: Write data using Polars and Arrow
You can load your dataset (e.g., Divvy bike trips), define a schema via Polars, and then write directly to Iceberg:
Simple. Effective. Almost Delta-like.
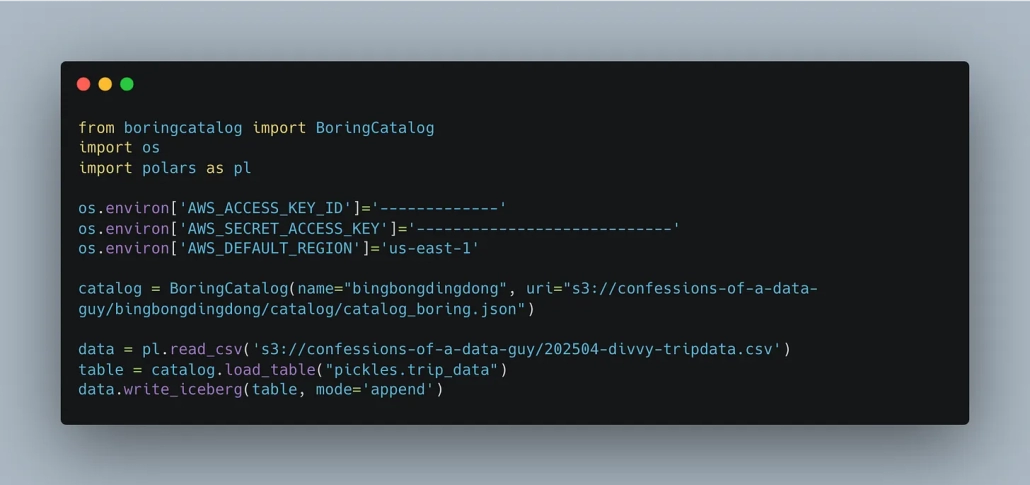
Step 5: Read it back just to prove it worked
table = catalog.load_table(("my_namespace", "trip_data"))
arrow_table = table.to_arrow()
print(arrow_table)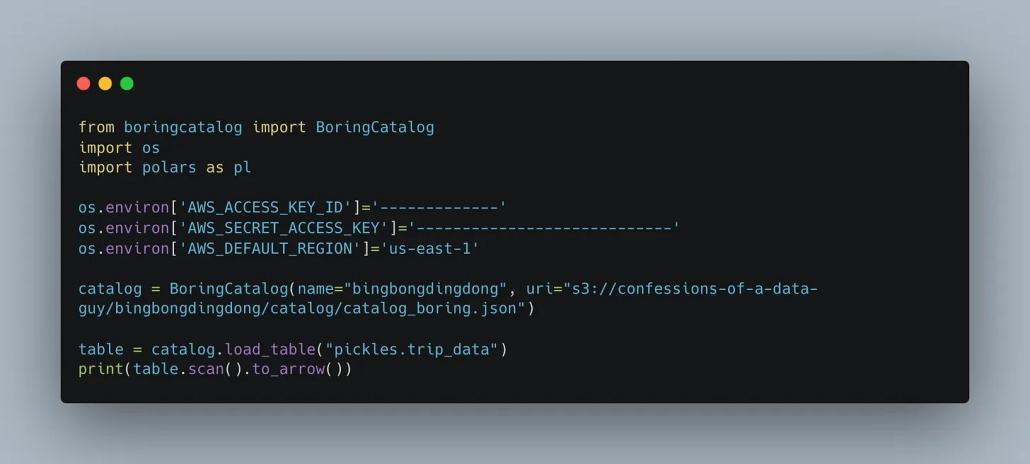
Why This Matters
Apache Iceberg has long lacked a realistic, cloud-friendly option for catalogs that don’t require a dedicated DevOps team to manage. While companies like AWS offer Iceberg support via S3 Tables, most existing solutions feel more like enterprise land-grabs than tools made for actual developers.
boring-catalog finally gives individual engineers and smaller teams the ability to experiment and deploy Iceberg with minimal ceremony.
This isn’t about reinventing the wheel—it’s about making the wheel easy to install.
Final Thoughts
We didn’t need another hyper-complex Iceberg catalog backed by a Kubernetes cluster. We needed something that does the job—quietly, reliably, and in the open.
The fact that it took one independent developer to ship a usable, cloud-native, open-source Iceberg catalog says a lot. Apache Iceberg’s community should take a long look at what the Delta Lake ecosystem got right: developer-first tooling and easy onboarding.
If you’re working with Iceberg, go check out boring-catalog on GitHub and send a thank-you to Julien Hurault. He’s doing the work the big vendors won’t.