
DuckDB … Merge Mismatched CSV Schemas. (also testing Polars)
I recently encountered a problem loading a few hundred CSV files, which contained mismatched schemas due to a handful of “extra” columns. This turned out to be not an easy problem for Polars to solve, in all its Rust glory.
That made me curious: how does DuckDB handle mismatched schemas of CSV files?
Of course, this can be a tricky problem to solve, and every creator of a new Data Engineering tool probably has a different take on how this should be handled. The perfectionist will probably say … “Puke the whole thing, schemas should match exactly if you’re reading multiple files.” The realist, who has worked in data for many years, might say, “No, you simply need to at least give the option to MERGE the schemas on read.”
It’s not a surprise that Polars, in all its Rust-based exactness and perfection, chose to puke. But what about DuckDB? DuckDB seems to be a tool built and grounded in the concepts of real-life dirty Data Engineering, doesn’t it?
So let’s test, I have no idea what will happen, how DuckDB acts when we read a few CSV files, one of which has an extra header column, full of NULLs, added by yours truly.

See that little bugger at the end??
Reading mismatched schema CSV files with DuckDB.
So let’s go ahead and write the simple DuckDB code to do an aggregation on all these files and see if it simply auto-merges the schemas and does the work, or pukes out of the box.

Looks like it works!!
But, what if we remove some of the extra juice we gave DuckDB in the read_csv_auto() ? We gave it help by saying strict_mode=false, ignore_errors=true
But what if we take those last two args out?
We get an error right away.

DuckDB immediately picks up on the file I messed with and adds an extra header record and column.
This is great! It will identify the correct file with a header schema mismatch to the rest, but we can also add a few lines of code if we are feeling adventurous and want to move forward. (This is actually a real use case in real-life production environments.)
What would Polars do?
Let’s try this same thing, with the same files, in Polars and see what happens.
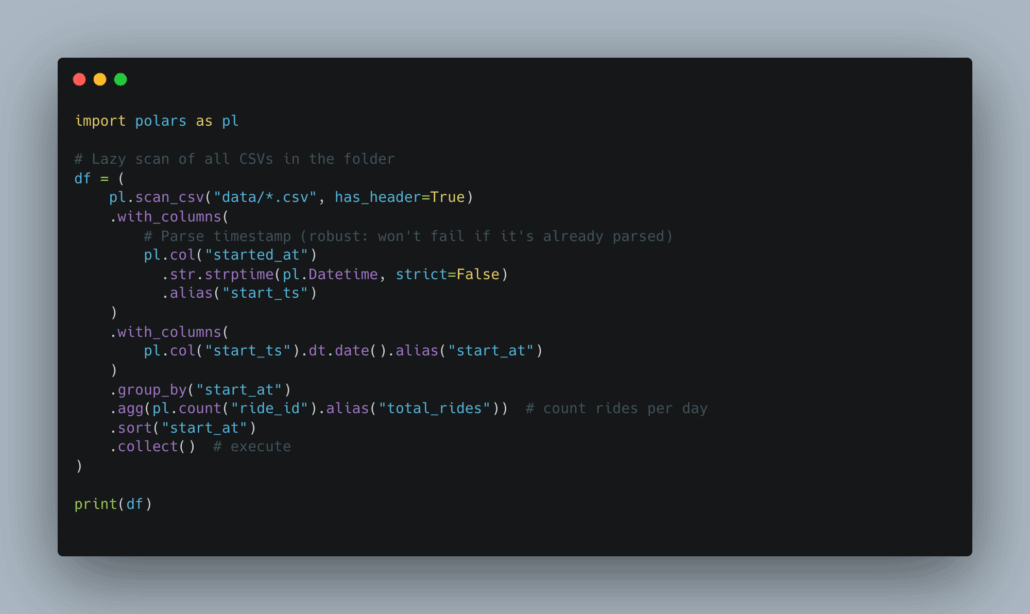
Just some out-of-the-box stuff here.
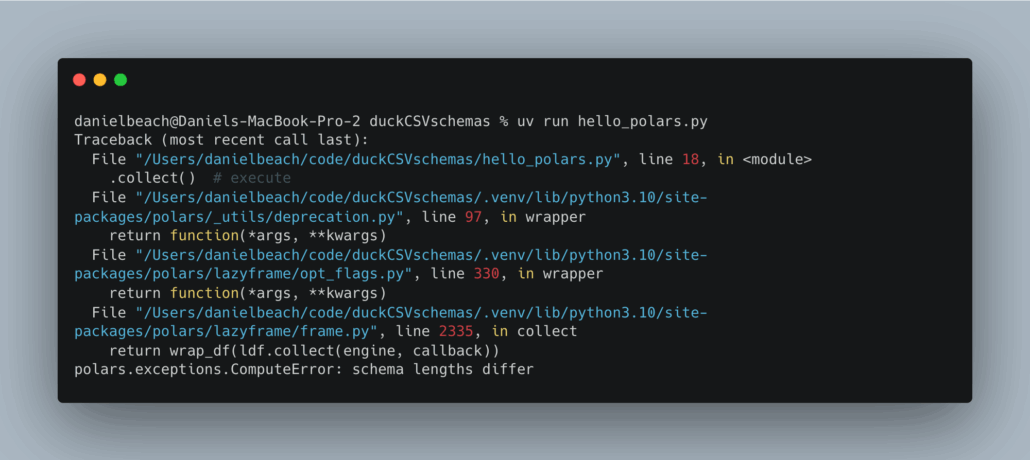
As expected, Polars pukes its gut at the first sign of schema trouble.
Adding ignore_errors=True changes nothing, same error. It looks like in the Polars GitHub docs for this read CSV method, there are a number of interesting options to get around this schema error.

We could indeed write out the schema and hand it over to Polars, but that’s a pain, and I want to try other stuff first.
Looks like one of the ONLY ways to do this (with how we did it via DuckDB) and NOT write out the entire schema … is to read the files one by one. Akkk.
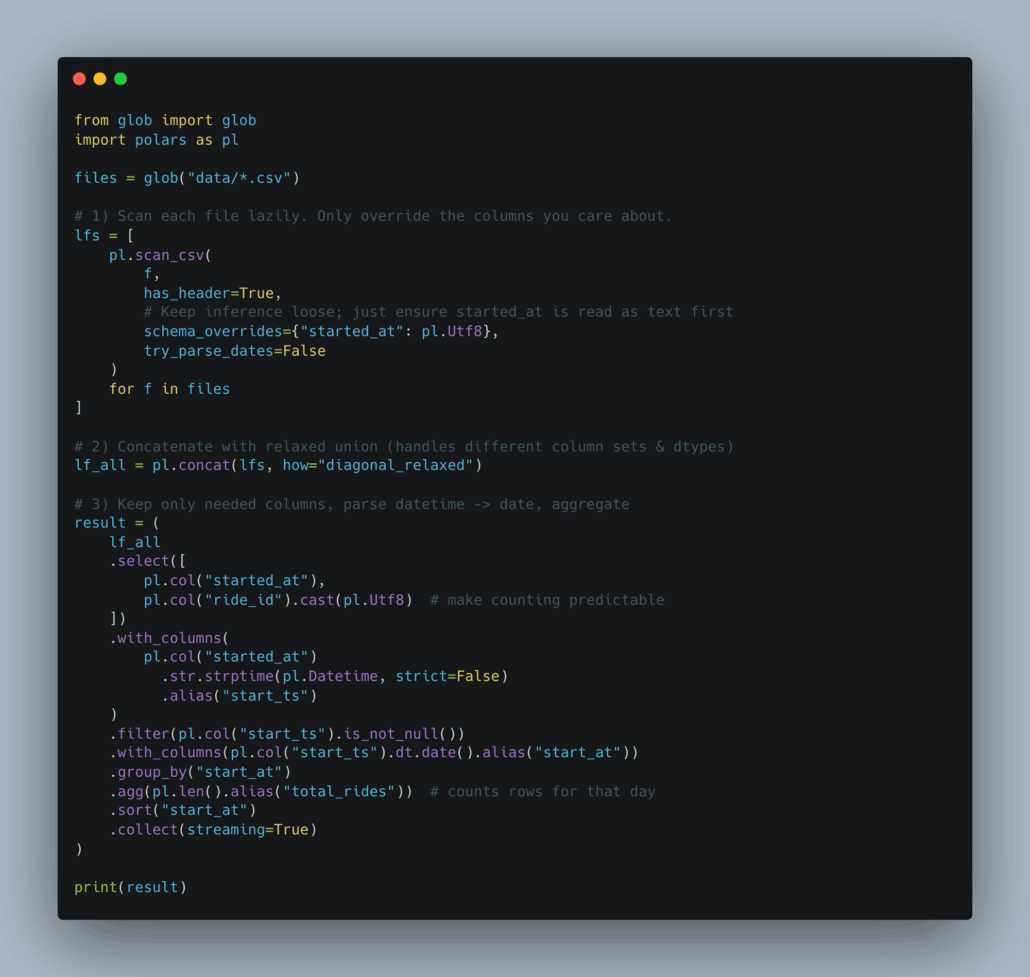
Sorry if you are a Polars expert and screaming at me through the keyboard.
Maybe it’s just a matter of perspective; maybe we all just learn the tools we like, and then we move on with life. It’s hard to argue with the simplicity of the DuckDB approach, heck, I’m no expert in DuckDB either, but it’s fun to play around. DuckDB just seems a little more grounded in the day-to-day reality of data work. Data is dirty, always will be.
This is where the rubber meets the road.
Isn’t it interesting to see the differences between these two competing data engineering tools? Polars is much stricter, no surprise with Rust, and makes it “hard” to get past this sort of data-centric strangeness, that are actually quite common. DuckDB, on the other hand, has a reputation for being down and dirty and able to do just about any data problem out there.
Proof is right here.

