Data Types in Delta Lake + Spark. Join and Storage Performance.

Photo by Amador Loureiro on Unsplash
Hmm … data types. We all know they are important, but we don’t take them very seriously. I mean we know the difference between boolean, string, and integers, those are easy to get right. But we all get sloppy, sometimes we got the string and varchar route because we don’t spend enough time on the data model to care.
Can a string versus a int or bigint in Delta Lake with Spark have a big impact on performance? Data size? Does it matter? Let’s find out.
Data Types on Delta Lake.
What I want to find out is very straightforward, how much do data types really matter? I mean if it doesn’t make a big impact on performance or data size usage … it’s just good to know. If we are working on a multitude of Delta Lakes, it seems like an understanding of what sort of impact having the wrong data type makes could lead to some different things. Most all Delta Lakes are used with Apache Spark, usually on Databricks.
- How close attention should we pay to
intorbigintvsvarchar? - Does it make a Delta Table much larger in size (increase storage costs)?
- When using Delta Lake + Spark, is
JOINperformance impacted?
Well, I’m sure all the straight-laced persons out there will say “Of course, it matters.” Don’t get me wrong, I understand data types matter, but some things matter more than others. If say int vs varchar has a sizeable impact at say a few million records join, then we can postulate that indeed data types are serious and we should pay extra care. If we see no difference at all, maybe a few milliseconds, well, then maybe we should spend our time optimizing other parts of Delta Lake and Spark implementations.
Who knows unless we try it?
The Process.
Here is what we are going to do, straight forward and simple approach.
- Create two Delta Tables stored in s3.
- Create two copies of those Delta Tables, with changed data type(s).
- Look at the space/size of those Delta Tables.
- Do a
JOINon the Delta Tables and see the performance difference.
Because it’s so obvious and common, we will test varchar vs intfor our two data types in question.
Create Delta Tables in s3.
For this test we are going to use Backbaze hard drive data set, it’s open-source and free to use. Also, we are going to use Databrick’s free Community Edition, that’s where we will write our Spark code to do all this Delta Table work.
I’m going to use my personal s3 bucket called s3://confessions-of-a-data-guy , this is where I’m going to put about 40GB worth of data from the Backblaze data set. Hopefully, this will be enough data where we can actually see some changes in performance and data size when testing.
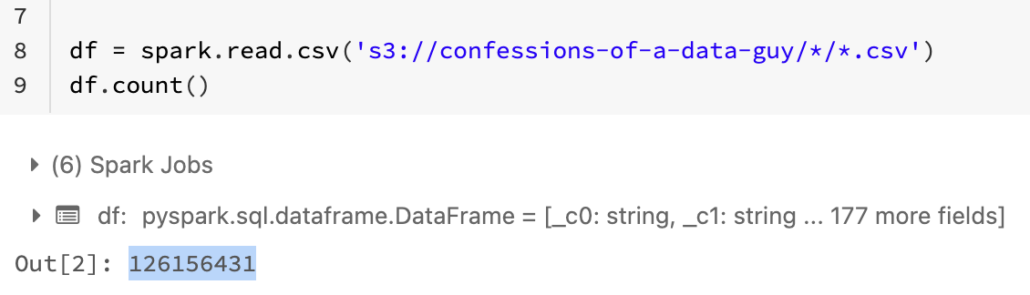
Per this code, it ends up being `126,156,431` million records.
Creating our Delta Tables stored in s3.
Ok, so let’s get to it. We want two Delta tables to start with, but eventually 4, so we can do some joins. The first set of tables will use INT or BIGINT for some columns, and the other set will use VARCHAR for strings. Then we will inspect the size and performance of each set.
First table with some BIGINT and BOOLEAN, second another Delta Table with default STRING types for columns.

To be fair I ran compaction aka OPTIMIZE on these Delta Tables.

Inspecting Delta Table size changes due to Data Types.
So what’s the size of these Delta tables? Here is a little Scala snippet that gives the bytes.


- Strings -> `1.073349667` GB
- Ints/Bools -> `1.021053763` GB
So it appears indeed our int/bool Delta Table is smaller than the String one. Sure, it’s not much of a difference, but in reality, in production, we would be dealing with Delta Tables that are hundreds of TBs in size, where this would probably make a difference. A 5% difference in size, as above, at scale, could add up to some cost savings!
Moral of the story. The data types in your Delta Tables matter.
Do Data Types affect Performance?
So to do some testing on this, we need to sort of generate another Delta Table and figure out how to make a join work with this data. We are going to have to make something up. In our dataset we have a column called `model` which describes the hard drive model, for example, WDC WUH721414ALE6L4 or ST12000NM001G.
Let’s pretend this dataset only has an integer in it for model number, which we have to use to do a lookup to get some random description of the model. To do this we will make distinct set of our models, and assign them an id. We will update our int table to hold this id, and join to our “description” Delta Table to get the model number.
Confused? Let’s just do it.
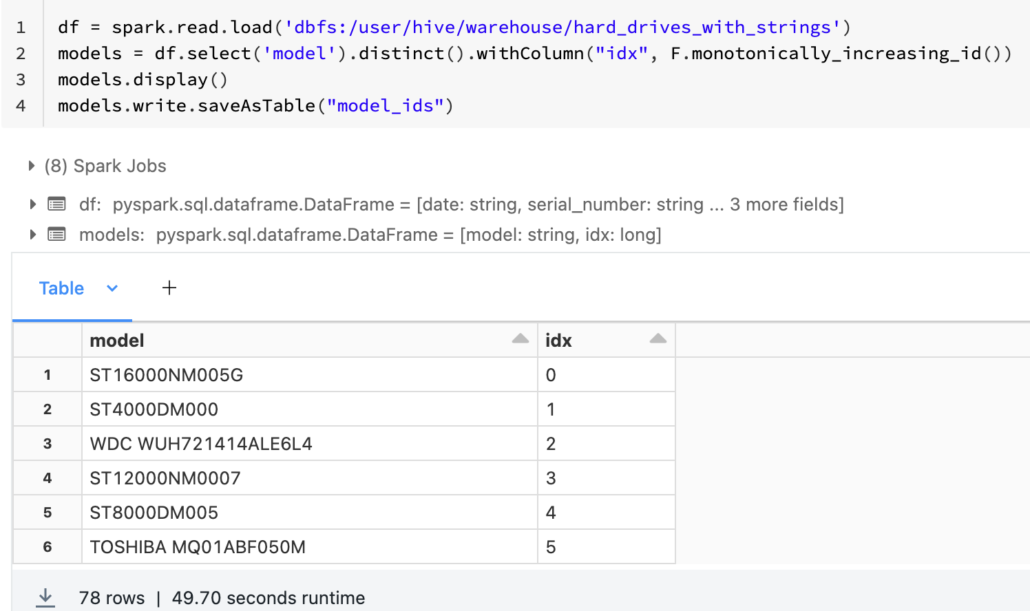
See? Now we will write those idxs back into a new column in our original Delta Table. So in theory we have to join this table to get the model number.
First, add the new column to the Delta Table.

Next, let’s update that idx column with the correct values.

Don’t worry, I’m running more OPTIMIZE after these commands, just to be safe.
Ok, after all that we can see our Delta Table now was a column called idx that contains an id that points, to an id over in our model_ids Delta Table created above. We are going to pretend that our Delta Table hard_drives_with_ints doesn’t contain the model column, but that we must join to model_ids on idx to pull the model.
idx stored as a String, see how the performance compares.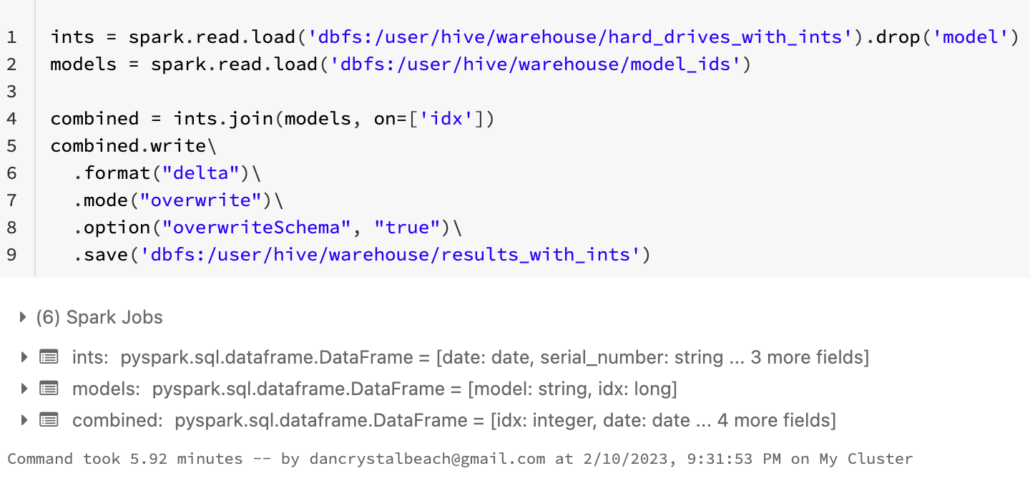
5.92 minutes to join and write the new dataset with an int for the join. What’s left but to do the same thing with idx morphed to Strings?model_ids Delta Table with String.
hard_drives_with_strings.
String version of idx.
Strings.
7.89 minutes compared to 5.92 , well now we know that data types on Delta Lake do matter!Results
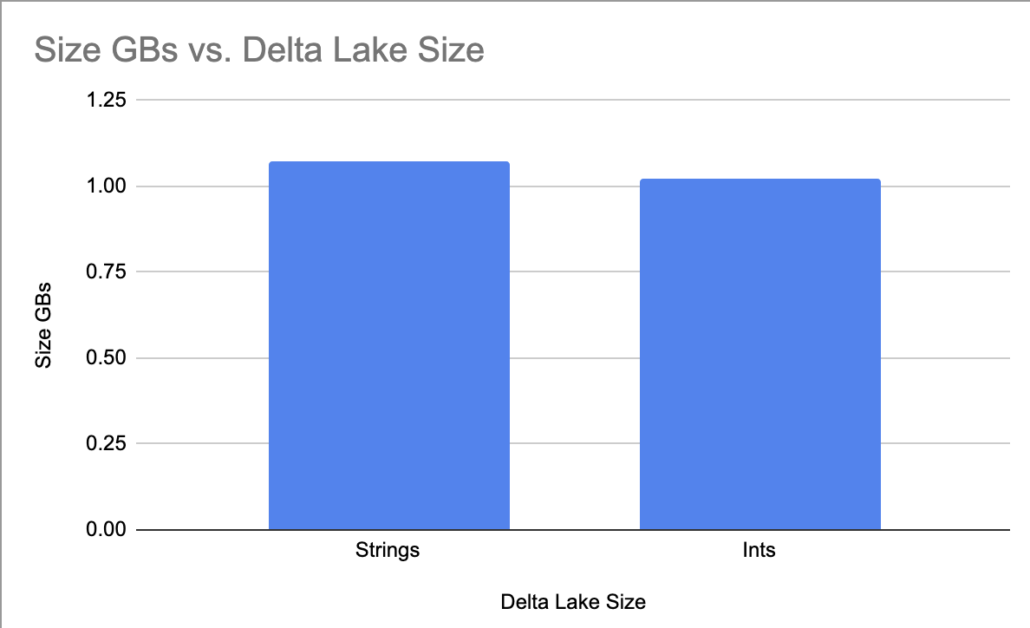
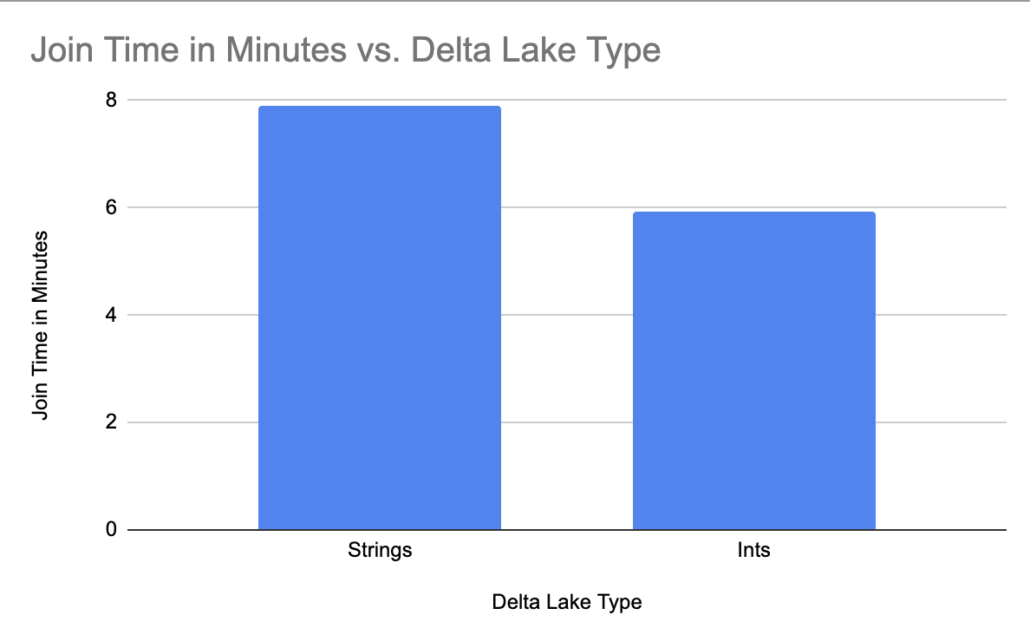
Ok, so what’s the big picture here? The story about Delta Lake and Data Types is that they matter. I mean our example was simple and used a very small data set, compared to most production uses of Delta Lake. Saving 5% or more in storage size is going to translate to real cost savings over time at scale.
Even more important is the knowledge that data types, String vs Integer makes a huge difference in JOIN performance. We can probably extrapolate that many Delta Lake operations could benefit from the integer if we have a choice in the matter. Data modeling matters.
Doing joins at scale on Delta Tables with hundreds of TBs and billions of records … go for the ints my friend, the savings in run times and resource consumption will be real.