
Embeddings and Vector Databases – Lance + DuckDB + LangChain
It’s an interesting time to be in software and data; the world of generative AI is changing the landscape beneath our feet. I don’t see this as a bad thing for software folk, but as an opportunity to learn new technologies and BUILD / UNDERSTAND the technologies used in an LLM and AI context.
You can’t expect an LLM trained two years ago to be up-to-date on what the new and best approaches are for X, Y, Z tech.
Sure, they can do a decent job given enough context, Agents, etc, but if you’re working on the cutting edge of AI and LLM infrastructure, you are going to have to be active in the community and reading about what others are doing, who’s releasing new tools, and what those tools do.
Don’t forget, there is the whole architectural and systems design piece. One part of the LLM and AI infrastructure is vector and embedding representations.
Embeddings and Vectors
Embeddings are how large language models (LLMs) turn messy human language into something computers can compare. Vectors are the numeric form those embeddings take. Think of embeddings as meaning distilled into numbers.
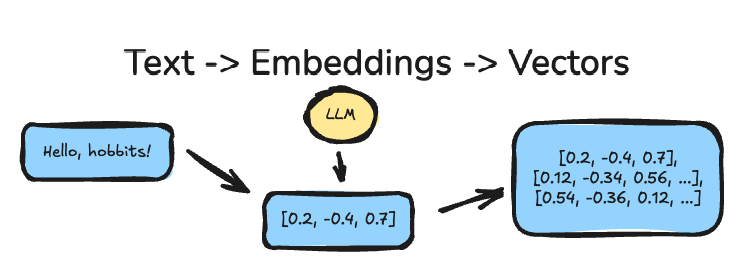
Usually, what happens in some RAG or LLM context, at a dumbed-down high level, is that we have some text, we “embed” that text with some specific LLM model we are using, then many times we store those embeddings in a Vector database, or storage layer, along with relevant metadata information.
- In the case we were embedding all the blog posts from this website for use in some RAG architecture, or as context or training material for an LLM …
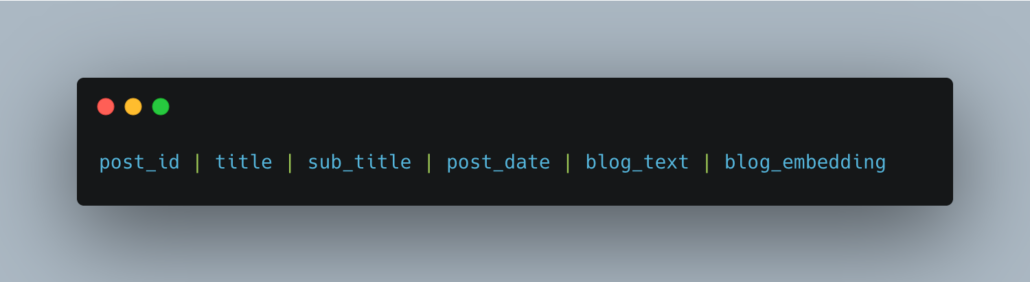
Anywho, I want to keep this simple and to the point.
I’ve struggled recently to find a “good” and “simple” vector database. What I mean is that adding a vector database to store embeddings is yet another layer of architectural complexity, another piece of the puzzle that requires code, complexity, and work.
When working on POCs or MVPs, I don’t really want to install or host some heavy SaaS vendor or other tooling database technology just to store embeddings I can use for retrieval in RAG or other contexts.
Enter the Lance file format.

Lance is much more than just a simple file format for storing embeddings, but for my purposes today, that’s all I’m going to use it for.
A simple solution (storage) for embeddings as my “vector database” in a RAG application. You find the full code base for my RAG CLI application, along with the code for embedding a bunch of my blog posts and storing them in Lance here on GitHub.
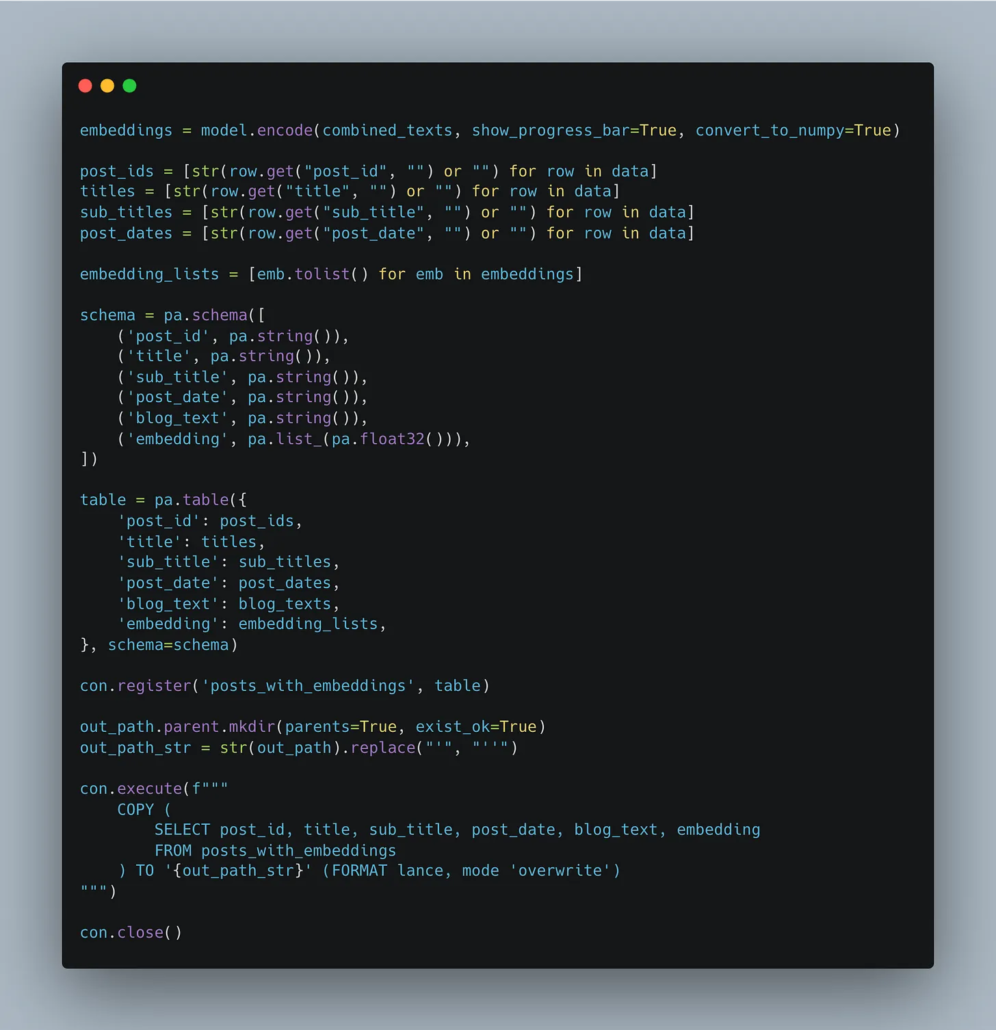
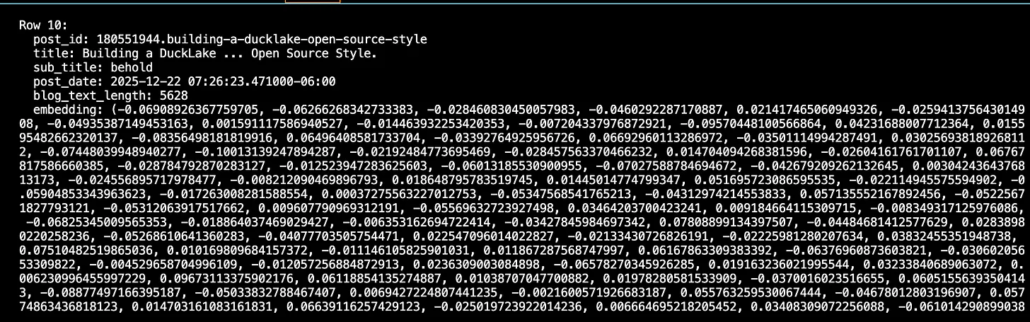
When you take text, embed it, and then store it to Lance, it shows up as files (maybe locally or in S3). You can see an example fold below called posts.lance on the left side.
Inside this Lance file is my metadata and embedding column.
- Simple pip install
- No heavy architecture or tooling
- Works with tools like DuckDB
- Works with tools like LangChain
Below is a code snippet of the Lance + LangChain integration. Easy.
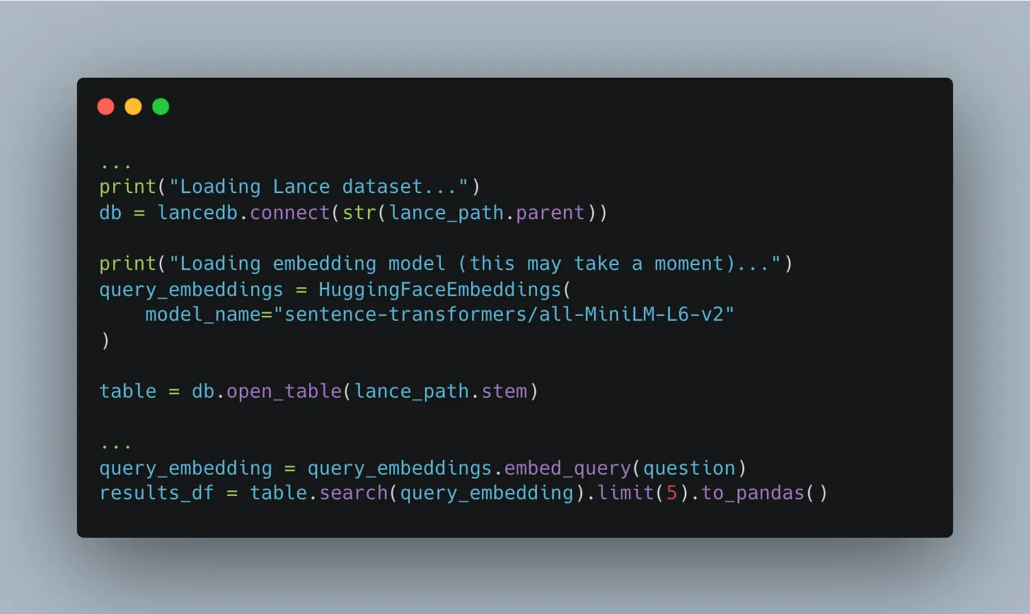
Lance just works.
That’s all I have to say about Lance. It just works. Period. Easy to install, easy to integrate with other tooling, like DuckDB and LangChain, what more could you ask for? Nothing. Simple file system, store embeddings, wire it up to LangChain, and now you have an easy-to-use Vector Database that doesn’t require a bunch of money or a server to install some heavy tooling.
This might not seem like a big deal to you, but then again, if you haven’t spent time on something like Databricks trying to spin up the slowest vector embedding endpoint in the world, storing records into the slowest vector index in the world, and the MOST EXPENSIVE way to store text embedding… then yeah … it might be hard to appreciate Lance.
I’m going to be amazed if I don’t hear more about Lance + Embeddings and using it as a Vector Database in our AI future.
