
Running Llama 3.1 8B Locally (LangChain and SQLite)
Things have changed a lot in the last year related to LLMs and AI; on the one hand, it seems the AI skeptics for coding are increasingly confined to the corners of the internet. Everyone is dancing around in the middle, not sure of where everything should fall. Clearly, if we don’t use AI at all, we will become coding dinosaurs. But a sea of junior devs relying too much on Cursor has created a knowledge crisis, and demand for Senior+ devs has skyrocketed.
Learning by Doing
I’m not an AI and LLM savant, but perhaps a little more than you, you hobbit. I’ve fine-tuned an LLM, have you?
I’ve built some multi-agent LLM setups. Have you?
I prefer to just learn by doing things. It might not be perfect, it might curl the toes of the actual AI Engineers out there (all 3 of them), but the rest of us can peel back the layers and check for black magic and the hood. None to be found, probably.
I’ve piddled around with my fair share of vector databases, RAGs, little fun chatbots connected to some local docs, etc. But it’s been a while since I’ve poked around to see what’s happened with running local LLMs. Why is this important?
Because there will eventually be fatigue in the world with paying OpenAI for every single token we want to work on. Every single piece of software these days, including LLM workflows, has been shipped off behind APIs. This is good for innovation and development speed, but bad for understanding and building custom workflows to support specific use cases.
The best way to address some of these learning problems with LLMs is to do some really simple stuff, like running an LLM model locally in the terminal. This helps a person understand, at a very basic level, what it would take to build, deploy, and support AI workflows.
Building and running LLama3 locally with SQLite.
So, before we dive into the tooling and code, I want to mention something. Don’t focus on the minute details of what every line of code is doing. Simply try to look at a high level at …
- what frameworks are being used
- how the model is downloaded and served
- what the database does
- how you might productionize something like this
We aren’t trying to build a rocket here; we are just trying to learn pieces and parts of an LLM pipeline and workflow by running stuff locally.
Anywho, let’s jump in and build a little local chatbot on the terminal, using llama3 and SQLite.
First, we will use Ollama to pull and manage our model of choice, llama3, it’s dead simple. Ollama, here we go. (install and pull llama3)
curl -fsSL https://ollama.com/install.sh | sh
# OR
HOMEBREW_NO_AUTO_UPDATE=1 brew install ollama
>> brew services start ollama
>> ollama pull llama3.1:8bNext, we can use Python’s uv package to set up and install everything we need for this local project.
>> uv init llmsaremidatbest
>> cd llmsaremidatbest
>> uv add langchain langchain-core langchain-community sqlalchemy ollamaOllama, combined with LangChain, makes for a dead-simple LLM setup, as you will see shortly.

Like I said, it’s a dead-simple little ChatBot with Ollama and LangChain. Look over the code; it’s nothing crazy and makes sense once you skim through it. If you look at the code on GitHub, it’s easy to replicate.
Running it in the command line and interacting with the bot is easy.
uv run hello.py --session pickles
Chatting with Llama 3.1 (8B) — session: ‘pickles’
Type ‘exit’ to quit.
You> Do you think that data modeling is dead?
lambda session_id: get_history(session_id),
Assistant> No, I don’t think data modeling is dead. While data warehousing and traditional ETL (Extract Transform Load) approaches have given way to more agile and flexible architectures like cloud-native data lakes and real-time processing pipelines, the principles of data modeling remain relevant.
Data modeling helps ensure that data is properly organized, normalized, and consistent across different systems. It also facilitates communication between stakeholders and developers, reduces data quality issues, and enables easier maintenance and evolution of data systems.
In fact, with the rise of modern data architectures, data modeling has become more crucial than ever to ensure proper data governance, compliance, and scalability.
You> See, the point is that the LLM tooling out there today, like Ollama and LangChain, has made it almost TOO easy to build little chatbots. Of course, in a production-like environment, you would probably put the Chat behind an API or something and wire up the frontend to a web app.
But, as you can imagine, this too had been built for you as well. It isn’t the “LLM” part of the “AI” that is hard anymore; it’s the MLOps —the serving and deployment of the model, APIs, the data fed to a RAG or vector DB, the interactions via a web app, etc.
Building ChatBot chains and pulling a model has never been easier. I mean, we just did it in a few minutes on a laptop.
Oh, you want to index some local documents and a RAG setup to this Chat?
uv add faiss-cpu langchain_ollamaJust need to add some documents.
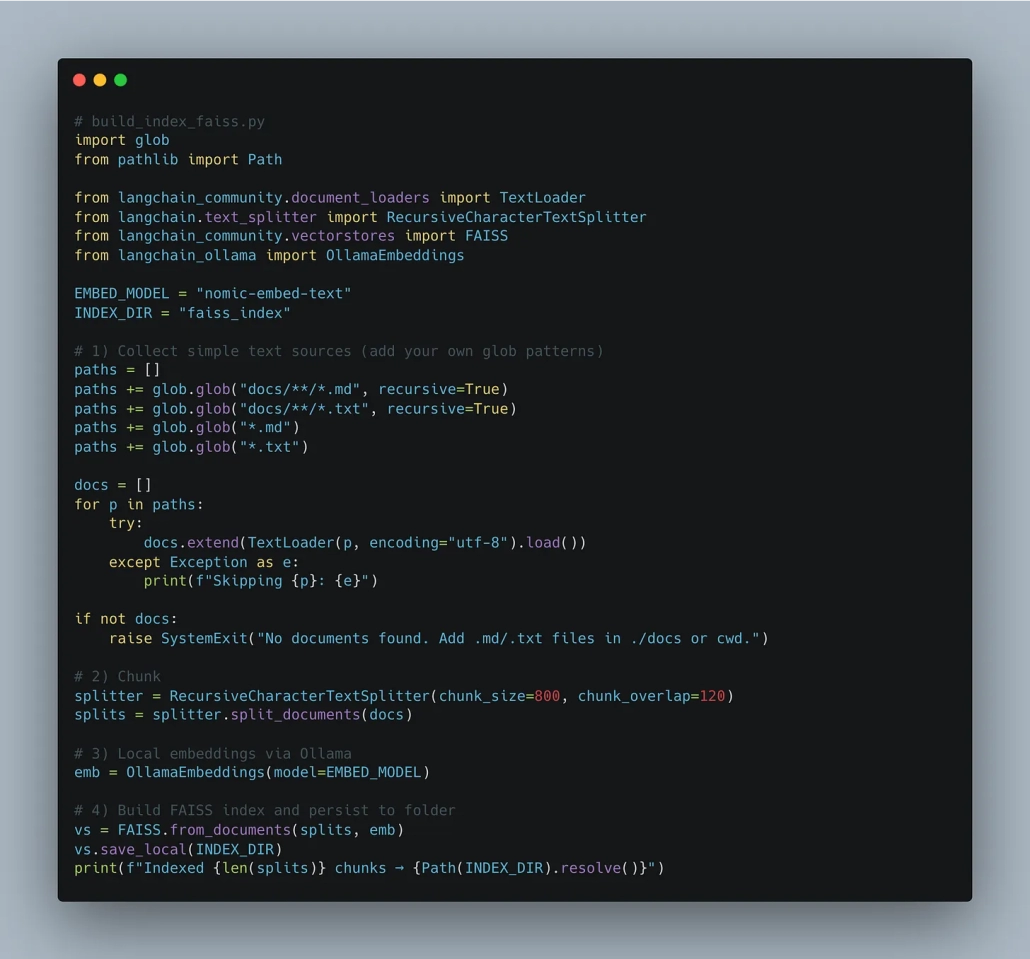
Again, imagine in a production environment we would host some sort of Vector database or something, and then have to massage the data to store it … just another data pipeline, my friend.
Now, we can update our main script to use RAG approach. Basically, we take our script from before and replace the build_chain() method with the one below.
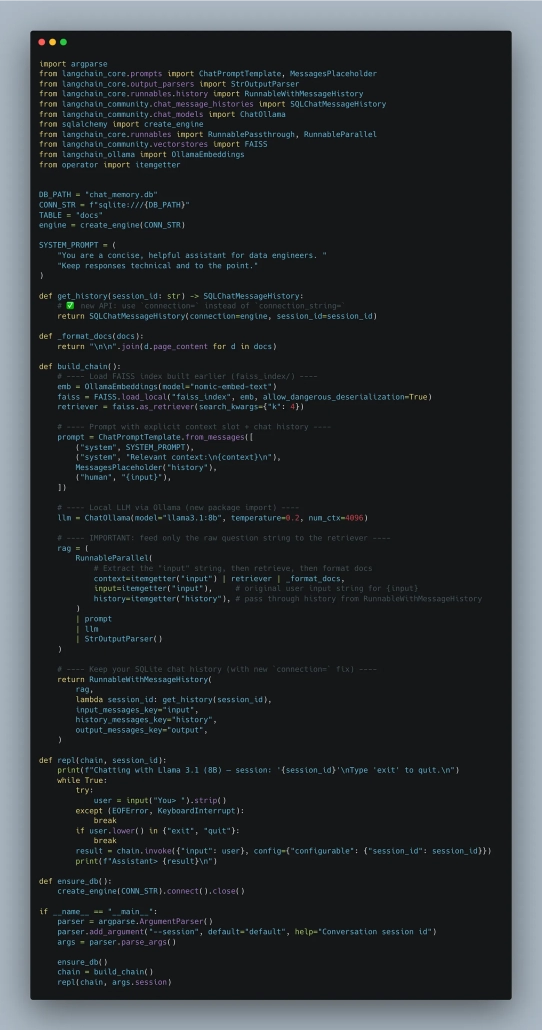
Again, nothing earth-shattering —just updating a function to account for any documents we added. Just normal software stuff, nothing crazy.
- reterive it
- ingest it
- store it
- make it available
- update our and use new framework(s)

